


Microcontroladores assumem papel crescente no Edge AI
Há poucos anos, presumia-se que o aprendizado de máquina (ML) - e até mesmo o aprendizado profundo (DL) - só poderia ser realizado em hardware de última geração, com treinamento e inferência na borda executada por gateways, servidores de borda ou dados centros. Era uma suposição válida na época porque a tendência de distribuição de recursos computacionais entre a nuvem e a borda estava em seus estágios iniciais. Mas esse cenário mudou drasticamente graças aos intensos esforços de pesquisa e desenvolvimento feitos pela indústria e pela academia.
O resultado é que hoje, processadores capazes de entregar muitos trilhões de operações por segundo (TOPS) não são necessários para executar ML. Em um número crescente de casos, os microcontroladores mais recentes, alguns com aceleradores de ML incorporados, podem levar o ML aos dispositivos de ponta.
Esses dispositivos não só podem realizar ML, como também o fazem bem, com baixo custo e baixíssimo consumo de energia, conectando-se à nuvem apenas quando absolutamente necessário. Resumindo, os microcontroladores com aceleradores de ML integrados representam a próxima etapa para trazer a computação para sensores como microfones, câmeras e aqueles que monitoram as condições ambientais, que geram os dados sobre os quais todos os benefícios da IoT são realizados.
Qual é a profundidade da borda?
Embora a borda seja amplamente considerada o ponto mais distante em uma rede IoT, geralmente é considerada como um gateway avançado ou servidor de borda. No entanto, não é aí que a borda realmente termina. Termina nos sensores próximos ao usuário. Torna-se lógico colocar o máximo de poder analítico possível perto do usuário, uma tarefa para a qual os microcontroladores são idealmente adequados.
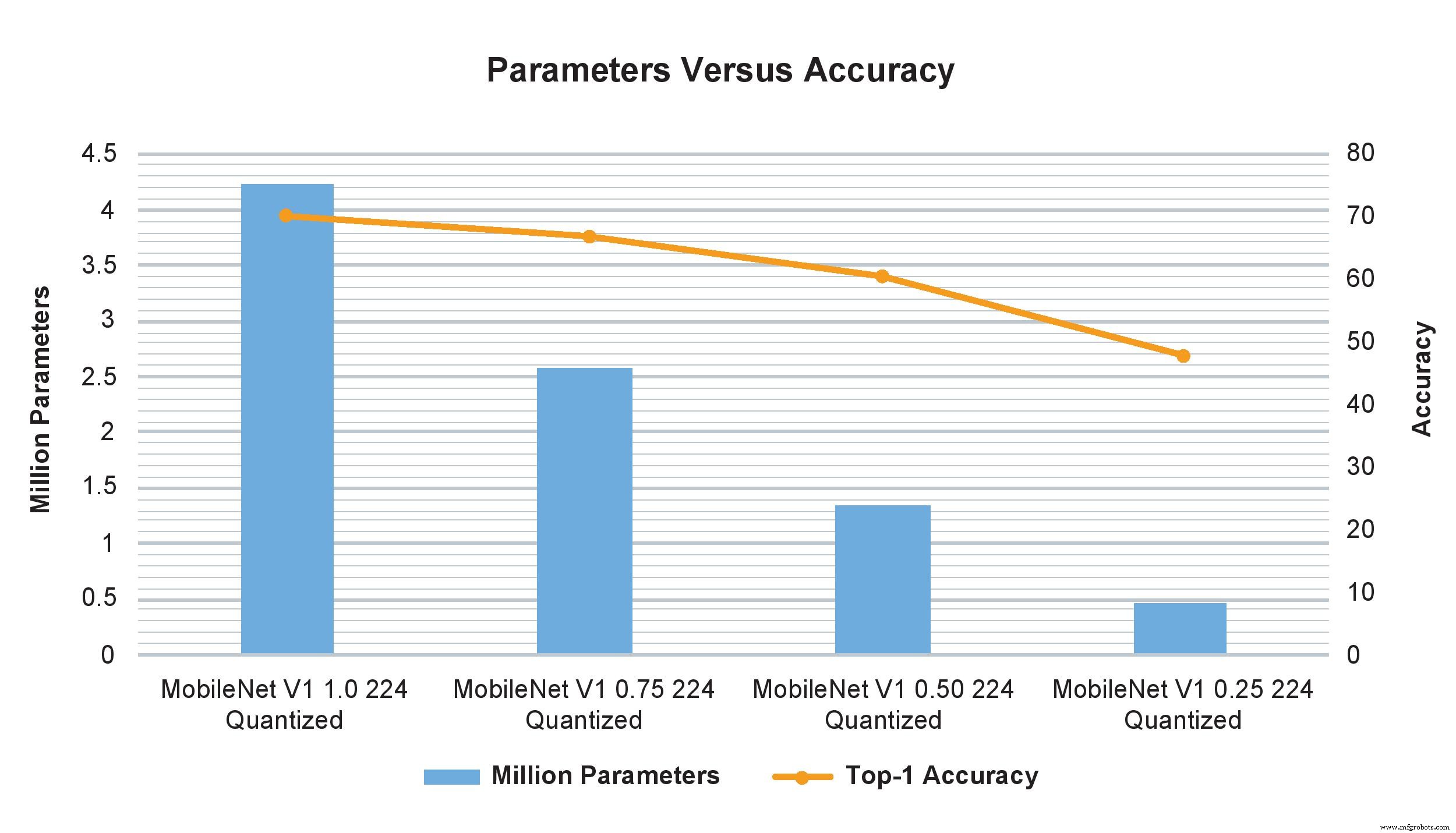
Os exemplos do modelo MobileNet V1 de vários multiplicadores de largura mostram um impacto drástico no número de parâmetros, cálculos e precisão. No entanto, apenas alterar o multiplicador de largura de 1,0 para 0,75 afeta minimamente a precisão do TOP-1, mas afeta significativamente o número de parâmetros e cálculos (Imagem:NXP)
Pode-se argumentar que os computadores de placa única também podem ser usados para processamento de ponta, pois são capazes de desempenho notável e, quando em clusters, podem rivalizar com um pequeno supercomputador. Mas eles ainda são muito grandes e caros para serem implantados nas centenas ou milhares necessários em aplicativos de grande escala. Eles também requerem uma fonte externa de energia DC que em alguns casos pode estar além do que está disponível, enquanto um MCU consome apenas miliwatts e pode ser alimentado por baterias de célula tipo moeda ou mesmo algumas células solares.
Portanto, não é surpreendente que o interesse em microcontroladores para realizar ML na extremidade tenha se tornado uma área muito importante de desenvolvimento. Ele até tem um nome - TinyML. O objetivo do TinyML é permitir que a inferência e, em última instância, o treinamento, sejam executados em pequenos dispositivos de baixa energia com restrição de recursos e, especialmente, microcontroladores, em vez de plataformas maiores ou na nuvem. Isso exige que os modelos de rede neural sejam reduzidos em tamanho para acomodar o processamento comparativamente modesto, armazenamento e recursos de largura de banda desses dispositivos, sem reduzir significativamente a funcionalidade e a precisão.
Esses esquemas de recursos otimizados permitem que os dispositivos ingeram dados de sensor suficientes para atender a sua finalidade, enquanto ajustam a precisão e reduzem os requisitos de recursos. Portanto, embora os dados ainda possam ser enviados para a nuvem (ou talvez primeiro para um gateway de borda e depois para a nuvem), haverá muito menos porque uma análise considerável já foi realizada.
Um exemplo popular de TinyML em ação é um sistema de detecção de objetos baseado em câmera que, embora seja capaz de capturar imagens de alta resolução, tem armazenamento limitado e requer uma redução na resolução da imagem. No entanto, se a câmera incluir análises no dispositivo, apenas os objetos de interesse são capturados em vez de toda a cena e, como as imagens relevantes são menos, sua resolução mais alta pode ser mantida. Esse recurso é normalmente associado a dispositivos maiores e mais poderosos, mas a pequena tecnologia de ML permite que isso aconteça em microcontroladores.
Pequeno, mas poderoso
Embora TinyML seja um paradigma relativamente novo, ele já está produzindo resultados surpreendentes para inferência (mesmo com microcontroladores relativamente modestos) e treinamento (em microcontroladores mais poderosos) com perda mínima de precisão. Exemplos recentes incluem reconhecimento facial e de voz, comandos de voz e processamento de linguagem natural e até mesmo a execução de vários algoritmos de visão complexos em paralelo.
Na prática, isso significa que um microcontrolador que custa menos de US $ 2 com um núcleo Arm Cortex-M7 de 500 MHz e de 28 Kbytes a 128 Kbytes de memória pode fornecer o desempenho necessário para tornar os sensores realmente inteligentes.
Mesmo com esse preço e nível de desempenho, esses microcontroladores têm várias funções de segurança, incluindo AES-128, suporte para vários tipos de memória externa, Ethernet, USB e SPI, e incluem ou suporte para vários tipos de sensores, bem como Bluetooth, Wi-Fi, SPDIF e I
2
Interfaces de áudio C. Gaste um pouco mais e o dispositivo normalmente terá um Arm Cortex-M7 de 1 GHz, Cortex-M4 de 400 MHz, 2 Mbytes de RAM e aceleração gráfica. O consumo de energia normalmente não passa de alguns miliamperes de uma fonte de 3,3 VCC.
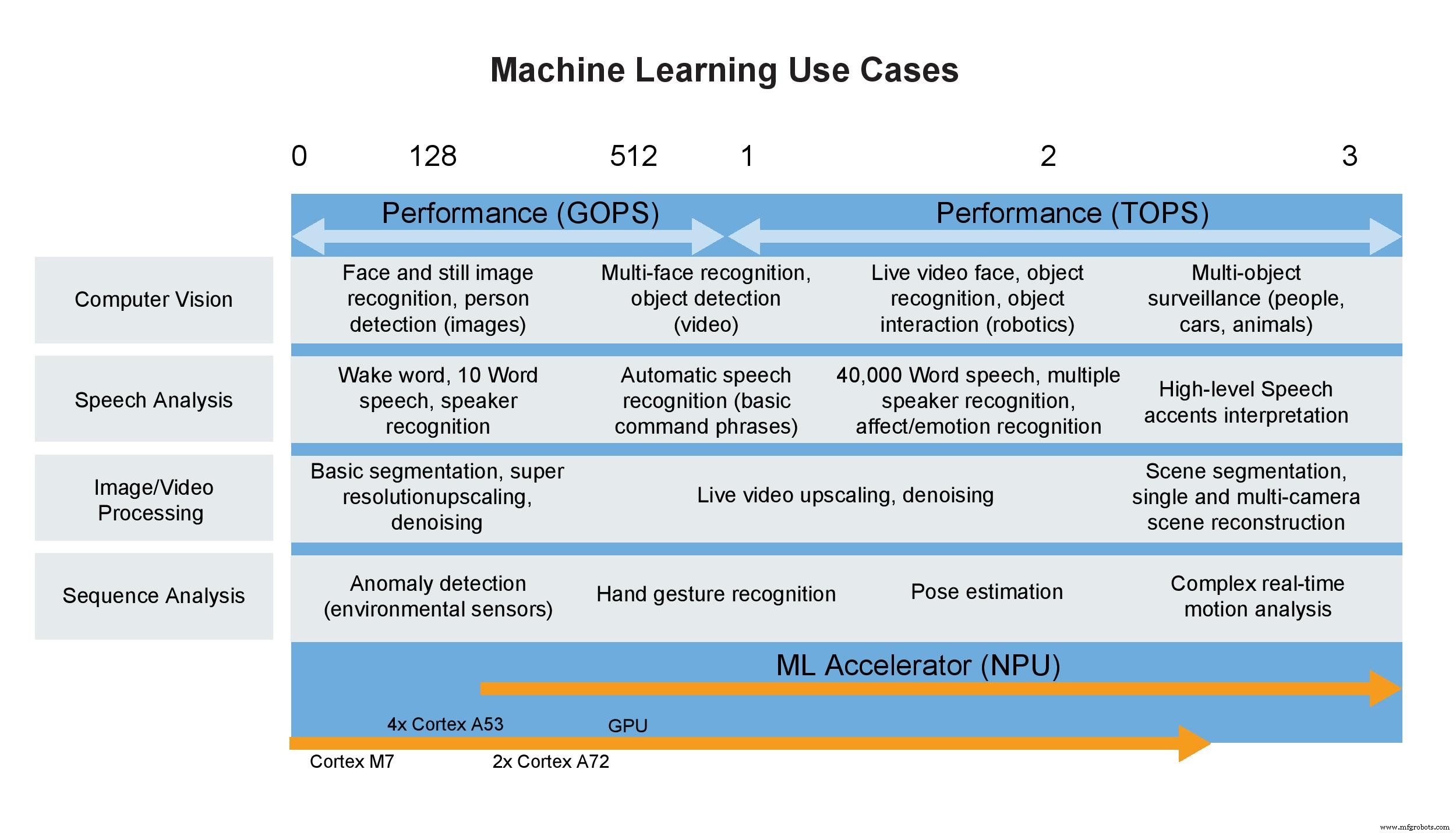
Casos de uso de aprendizado de máquina (Imagem:NXP)
Algumas palavras sobre TOPS
Os consumidores não estão sozinhos quando usam uma única métrica para definir o desempenho; designers fazem isso o tempo todo e os departamentos de marketing adoram. Isso ocorre porque uma especificação de título simplifica a diferenciação entre os dispositivos, ou pelo menos é o que parece. Um exemplo clássico é a CPU, que por muitos anos foi definida por sua taxa de clock. Felizmente para designers e consumidores, esse não é mais o caso. Usar apenas uma métrica para classificar uma CPU é semelhante a avaliar o desempenho de um carro pela linha vermelha do motor. Não é sem sentido, mas tem pouco a ver com a potência do motor ou com o desempenho do carro, porque muitos outros fatores juntos determinam essas características.
Infelizmente, o mesmo é cada vez mais verdadeiro para aceleradores de rede neural, incluindo aqueles dentro de MPUs ou microcontroladores de alto desempenho, que são especificados por bilhões ou trilhões de operações por segundo porque, mais uma vez, é um número fácil de lembrar. Mas, na prática, GOPS e TOPS sozinhos são métricas relativamente sem sentido e representam uma medição (sem dúvida a melhor) feita em um laboratório, em vez de representar um ambiente operacional real. Por exemplo, o TOPS não considera as limitações da largura de banda da memória, a sobrecarga de CPU necessária, pré e pós-processamento e outros fatores. Quando todos esses e outros são considerados, como o desempenho quando empregado em uma placa específica em operação real, o desempenho no nível do sistema provavelmente pode ser 50% ou 60% do valor TOPS na folha de dados.
Todos esses números indicam o número de elementos de computação no hardware multiplicado por sua velocidade de clock, em vez de quantas vezes ele terá os dados disponíveis quando precisar funcionar. Se os dados estivessem sempre disponíveis imediatamente, o consumo de energia não fosse um problema, as restrições de memória não existissem e o algoritmo fosse perfeitamente mapeado para o hardware, eles seriam mais significativos. Mas o mundo real não apresenta esses ambientes ideais.
Quando aplicada a aceleradores de ML em microcontroladores, a métrica é ainda menos valiosa. Esses dispositivos minúsculos normalmente têm um valor de 1 a 3 TOPS, mas ainda podem fornecer os recursos de inferência necessários em muitos aplicativos de ML. Esses dispositivos também contam com processadores Arm Cortex projetados especificamente para aplicativos de ML de baixo consumo de energia. Junto com o suporte para operações inteiras e flutuantes e muitos outros recursos no microcontrolador, torna-se óbvio que TOPS, ou qualquer outra métrica única, é incapaz de definir adequadamente o desempenho sozinho ou em um sistema.
Conclusão
O desejo de realizar inferências em microcontroladores diretamente ou acoplados a sensores, como câmeras fotográficas e de vídeo, está surgindo agora, à medida que o domínio IoT se aproxima de realizar o máximo de processamento possível na borda. Dito isso, o ritmo de desenvolvimento de processadores de aplicativos e aceleradores de rede neural dentro de microcontroladores é rápido, e soluções mais eficientes estão aparecendo com frequência. A tendência é consolidar mais funcionalidade centrada em IA, como processamento de rede neural junto com um processador de aplicativo no microcontrolador, sem aumentar drasticamente o consumo de energia ou o tamanho.
Hoje, os modelos podem ser treinados em uma CPU ou GPU mais potente e, em seguida, implementados em um microcontrolador usando mecanismos de inferência como o TensorFlow Lite para reduzi-los em tamanho e atender aos requisitos de recursos do microcontrolador. O escalonamento pode ser facilmente realizado para acomodar maiores requisitos de ML. Em breve, deverá ser possível realizar não apenas inferências, mas treinamento nesses dispositivos, o que efetivamente tornará o microcontrolador um competidor ainda mais formidável de soluções de computação maiores e mais caras.
>> Este artigo foi publicado originalmente em nosso site irmão, EE Times.
Integrado
- Papel da computação em nuvem na inteligência
- Função de sistemas incorporados em automóveis
- Resfriamento por câmara de vapor encontra um papel crescente em produtos quentes
- Coleta de energia de RF encontra um papel crescente em aplicativos orientados a IA
- USB-C encontra um papel crescente em wearables e produtos móveis
- Módulo de IA pequeno construído no Google Edge TPU
- A placa do sensor inteligente acelera o desenvolvimento de IA de borda
- Câmera inteligente oferece visão de máquina de ponta turnkey AI
- Os robôs desempenham um papel na indústria 4.0
- O papel da computação de borda em implantações comerciais de IoT