


SoCs habilitados para IA lidam com vários streams de vídeo
A especialista em processamento de imagem Ambarella lançou dois novos SoCs para câmeras de segurança de sensor único e múltiplo, cada um com novos recursos de IA habilitados pelo motor acelerador CVflow AI da empresa. Ambos suportam codificação de vídeo 4K e processamento avançado de IA, como reconhecimento facial ou reconhecimento de placa de carro.
O CV5S SoC tem como alvo sistemas de câmeras multissensores, codificando quatro canais de imagem de até 8MP / 4K de resolução, cada um a 30 quadros por segundo (fps) enquanto executa IA avançada em cada fluxo de imagem 4K. Ele pode lidar com até 14 entradas. A família SoC dobra a resolução de codificação e largura de banda de memória da geração anterior de produtos Ambarella, consumindo 30 por cento menos energia. Ele consome <5W e fornece 12 eTOPS (TOPS equivalente à GPU, a medida de Ambarella da quantidade de potência da GPU necessária para executar as mesmas tarefas de processamento de IA).
O outro novo SoC, CV52S, tem como alvo câmeras de sensor único e suporta resolução 4K a 60 fps. Comparado com as gerações anteriores de Ambarella SoCs, este novo dispositivo quadruplica o desempenho de IA, dobra o rendimento da CPU e oferece 50 por cento mais largura de banda de memória. Consome <3 W e fornece 6 eTOPS.
O aumento de desempenho decorre da migração para o nó de processo de 5 nm, juntamente com melhorias e ampliação do bloco de acelerador CVflow AI interno de Ambarella.
“Você vê todas essas startups vindo de todos os lugares, dizendo que têm o melhor desempenho de IA por watt, e podem estar certas”, disse Jerome Gigot, diretor sênior de marketing da Ambarella. “Mas isso não faz uma câmera, isso não faz um produto. Se você tem apenas um acelerador de IA, você só tem um acelerador de IA. ”
Gigot observou que um pipeline de imagem para vídeo 4K ou 8K é complexo, lidando com uma grande quantidade de dados, codificando grandes volumes de dados, transferindo esses dados para um bloco especial para processamento de IA enquanto provavelmente executa uma pilha Linux no topo. Isso é difícil de conseguir com orçamentos de baixo consumo de energia, mantendo a qualidade do vídeo.
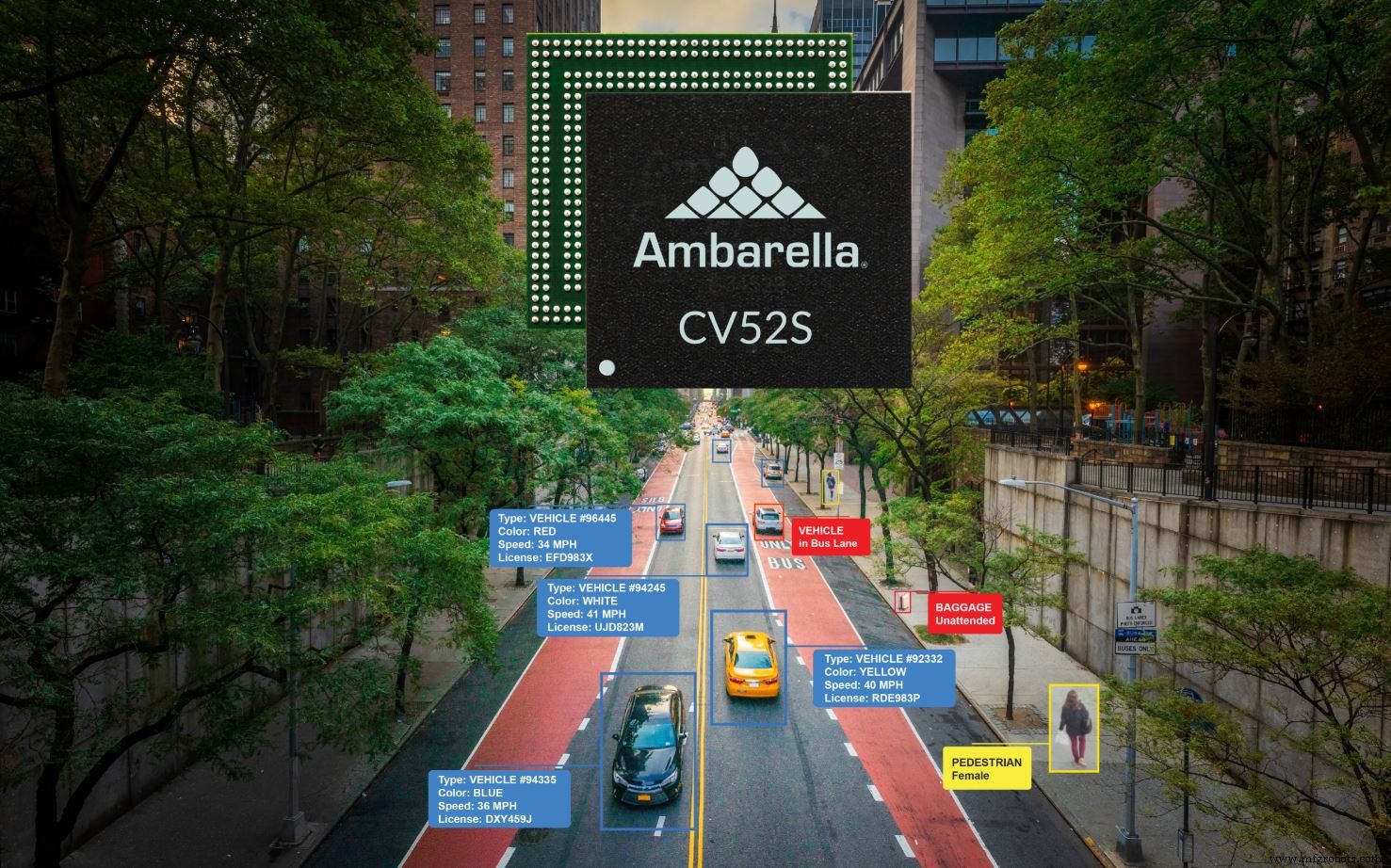
O CV52S visa projetos de sensor único, como aqueles encontrados no monitoramento de tráfego e outras aplicações de cidades inteligentes (Fonte:Ambarella)
Junto com o acelerador CVflow AI, os dois novos SoCs incluem processador de sinal de imagem (ISP) Ambarella que lida com recursos como processamento de cores, exposição automática, balanço de branco automático e filtragem de ruído.
“Este bloco que desenvolvemos há 16 anos”, disse Gigot. “É por isso que pensamos que as startups ainda têm um longo caminho a percorrer. Eles poderiam licenciar [um bloco de ISP de outro lugar], mas não está realmente integrado com o resto do sistema em termos de acesso à memória e tudo o mais. ”
O sistema de memória está entre as peças-chave de IP da empresa.
“Temos um controlador de memória e orquestramos tudo para que possamos obter os dados no chip. Tentamos não fazer nenhuma cópia ”, disse Gigot. “Movemos ponteiros, não movemos dados. Isso só é possível se você projetar toda a arquitetura do zero, sabendo exatamente o que o chip fará. ”
Motor acelerador
O acelerador AI é um processador vetorial que pode acelerar a convolução e outras funções AI comuns, ou ser usado para cargas de trabalho clássicas de visão computacional. Os usuários também podem optar por executar partes de uma rede neural (como algoritmos de classificação em uma rede de detector de disparo único) ou por meio de uma CPU Arm Cortex-A76 dual-core no chip.
A pilha de software permite que os aplicativos aproveitem a dispersão do coeficiente, uma técnica pela qual os coeficientes da rede com valores próximos de zero são arredondados para zero. A abordagem pode “podar” “ramos” inteiros de cálculos do algoritmo para reduzir enormemente os requisitos de computação.
A esparsificação "é uma técnica realmente eficaz para nós porque quando há um coeficiente zero, em nossa arquitetura não fazemos a operação, temos uma função de salto", disse ele. “Portanto, não calculamos o resultado para esse coeficiente. Demora praticamente zero ciclos. ”
O processo normalmente identifica 50 a 80 por cento dos coeficientes como alvos para esparsificação, disse Gigot. Um pequeno retreinamento geralmente é necessário após a esparsificação, a fim de recuperar a precisão da previsão perdida durante o processo. De acordo com Gigot, o retreinamento geralmente pode trazer precisão para 1 por cento do modelo original - uma compensação aceitável para a maioria dos clientes, especialmente dada a redução de tamanho de modelo de até 5 vezes. Ambarella também está trabalhando em ferramentas de esparsificação e quantização que são mais sensíveis à arquitetura.
clique para imagem em tamanho real
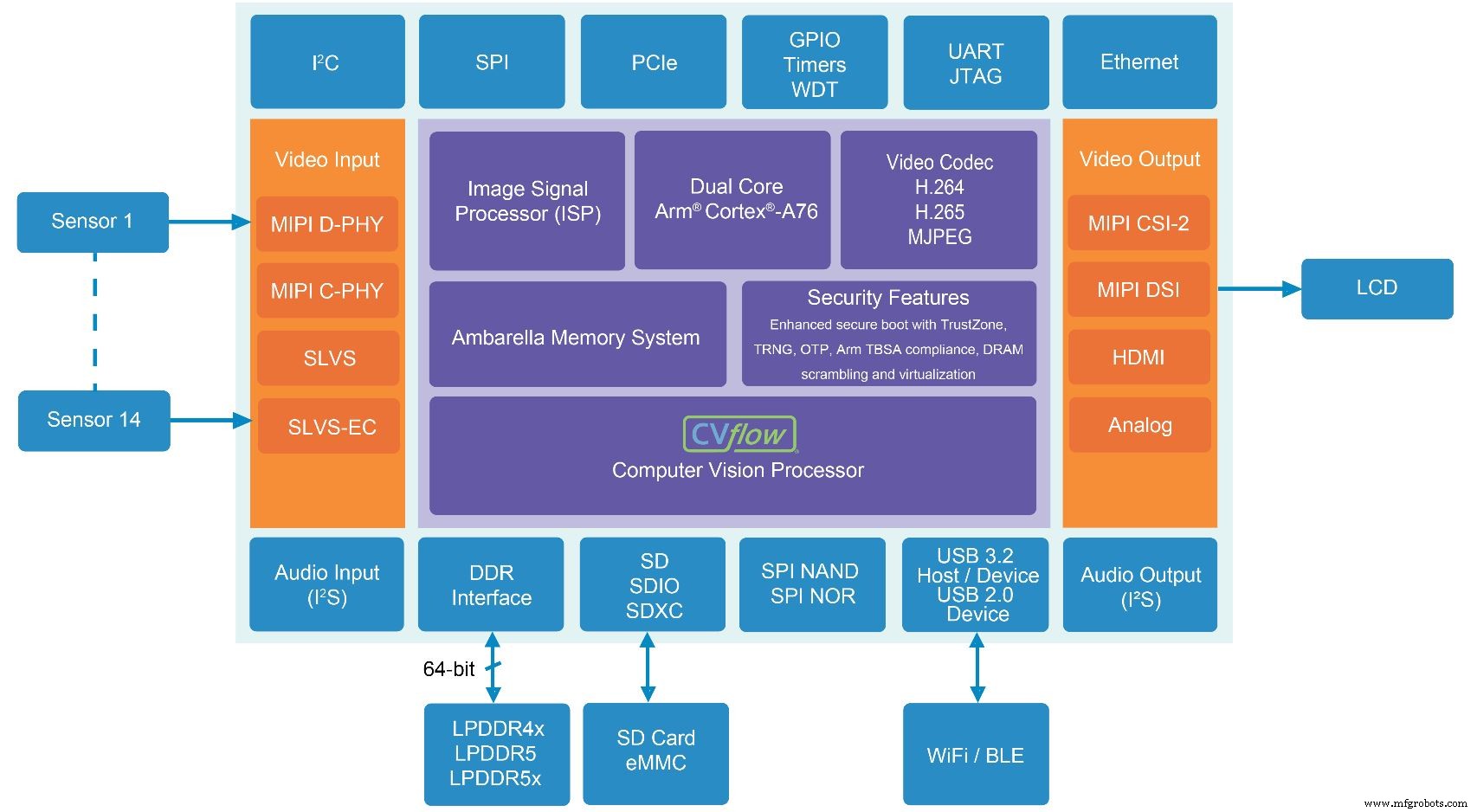
O CV5S SoC para sistemas de câmera multissensor inclui a última geração do CVflow AI da Ambarella e acelerador de visão por computador (Fonte:Ambarella)
Com a capacidade de aceitar até 14 fluxos de vídeo e, em seguida, executar IA nesses fluxos simultaneamente, os clientes executarão várias redes neurais simultaneamente? Será necessário algum tipo de esquema de multiplexação?

Jerome Gigot (Fonte:Ambarella)
Sim para ambos, respondeu Gigot. “O CVflow é um motor vetorial muito rápido, um motor de convolução muito rápido. Tudo é multiplexado no tempo. Temos caminhos diferentes no hardware para que possamos paralelizar as operações, mas não o amarramos a uma rede específica [que é] totalmente diferente do processamento em lote em uma GPU. ”
O processamento em lote, uma técnica frequentemente empregada por grandes GPUs, agrupa as imagens e as envia para serem processadas em paralelo. As GPUs já possuem outros parâmetros carregados. Essa abordagem reduz o custo de computação por não ter que alternar entre as operações.
Para motores menores como CVflow, redes neurais maiores devem ser quebradas em pedaços para serem processados, uma vez que a memória do chip não pode armazenar todos os parâmetros de uma vez. Pedaços consecutivos podem se originar da mesma rede neural, ou de outra rede, ou de outra entrada de canal. A utilização típica de hardware em CVflow está entre 70 e 80 por cento, disse Gigot, acrescentando que a comutação de redes / canais não afeta a eficiência.
Espera-se que o CV5S e o CV52S comecem a amostragem em outubro de 2021.
>> Este artigo foi publicado originalmente em nosso site irmão, EE Vezes.
Conteúdos Relacionados:
- O processador AI Vision permite vídeo de 8K a 30 fps em menos de 2W
- Ambarella visa detecção inteligente de bordas com nova câmera SoC
- FPGAs substituem ASICs em ADAS baseado em visão Subaru Eyesight
- Arm adiciona CPU, GPU e ISP para segurança autônoma e visual
- A placa de visão de IA de baixo consumo dura ‘anos’ com uma única bateria
Para obter mais informações sobre o Embedded, assine o boletim informativo semanal por e-mail da Embedded.
Integrado
- Java captura múltiplas exceções
- Microchip:A solução PolarFire com base em FPGA permite vídeo e imagem em 4K com fator de forma menor
- Rutronik:SoCs multiprotocol sem fio e módulos da Redpine Signals
- Renesas:controlador de vídeo full HD LCD com entrada MIPI-CSI2
- Usar vários chips de inferência exige um planejamento cuidadoso
- SoCs avançados trazem mudanças nos designs de IoT médica
- O processador de vídeo permite codificação de vídeo 4K para designs alimentados por bateria
- Sistemas Abaco:gráficos XMC robustos e placa de vídeo
- Portwell:o sistema de 19 ”visa aplicativos de video wall
- Módulo Tiny integra vários biossensores