


União em linguagem C para empacotar e desempacotar dados
Saiba como compactar e descompactar dados com uniões na linguagem C.
Aprenda sobre como compactar e descompactar dados com sindicatos em linguagem C.
Em um artigo anterior, discutimos que a aplicação original dos sindicatos tinha criado uma área de memória compartilhada para variáveis mutuamente exclusivas. No entanto, com o passar do tempo, os programadores usaram amplamente as uniões para um aplicativo completamente diferente:extrair partes menores de dados de um objeto de dados maior. Neste artigo, veremos esta aplicação particular de sindicatos em mais detalhes.
Usando uniões para empacotar / desempacotar dados
Os membros de um sindicato são armazenados em uma área de memória compartilhada. Esta é a principal característica que nos permite encontrar aplicações interessantes para sindicatos.
Considere o sindicato abaixo:
união {uint16_t palavra; struct {uint8_t byte1; uint8_t byte2; };} u1; Existem dois membros dentro desta união:O primeiro membro, “palavra”, é uma variável de dois bytes. O segundo membro é uma estrutura de duas variáveis de um byte. Os dois bytes alocados para a união são compartilhados entre seus dois membros.
O espaço de memória alocado pode ser conforme mostrado na Figura 1 abaixo.
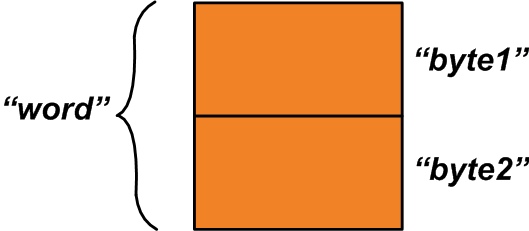
Figura 1
Enquanto a variável “palavra” se refere a todo o espaço de memória alocado, as variáveis “byte1” e “byte2” se referem às áreas de um byte que constroem a variável “palavra”. Como podemos usar esse recurso? Suponha que você tenha duas variáveis de um byte, “x” e “y”, que devem ser combinadas para produzir uma única variável de dois bytes.
Neste caso, você pode usar a união acima e atribuir “x” e “y” aos membros da estrutura da seguinte forma:
u1.byte1 =y; u1.byte2 =x; Agora, podemos ler a “palavra” membro do sindicato para obter uma variável de dois bytes composta pelas variáveis “x” e “y” (consulte a Figura 2).
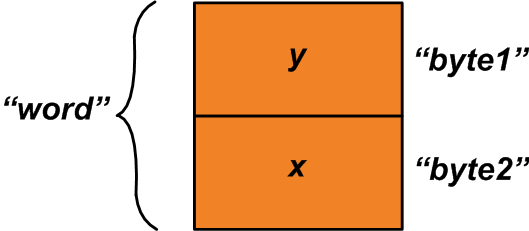
Figura 2
O exemplo acima mostra o uso de uniões para empacotar duas variáveis de um byte em uma única variável de dois bytes. Também poderíamos fazer o inverso:escrever um valor de dois bytes em “palavra” e descompactá-lo em duas variáveis de um byte lendo as variáveis “x” e “y”. Escrever um valor para um membro de um sindicato e ler outro membro é às vezes chamado de “trocadilho de dados”.
O fim do processador
Ao usar uniões para empacotar / descompactar dados, precisamos ter cuidado com o endianness do processador. Conforme discutido no artigo de Robert Keim sobre endianness, este termo especifica a ordem em que os bytes de um objeto de dados são armazenados na memória. Um processador pode ser little endian ou big endian. Com um processador big-endian, os dados são armazenados de forma que o byte que contém o bit mais significativo tenha o endereço de memória mais baixo. Em sistemas little-endian, o byte que contém o bit menos significativo é armazenado primeiro.
O exemplo representado na Figura 3 ilustra o armazenamento de little endian e big endian da sequência 0x01020304.
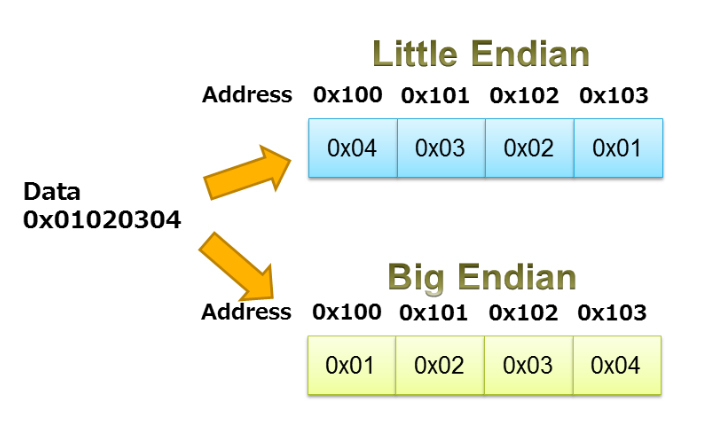
Figura 3. Imagem cortesia do IAR.
Vamos usar o seguinte código para experimentar a união da seção anterior:
#include <stdio.h > # include <stdint.h >int main () {união {struct {uint8_t byte1; uint8_t byte2; }; palavra uint16_t; } u1; u1.byte1 =0x21; u1.byte2 =0x43; printf ("Word is:% # X", u1.word); return 0;} Executando este código, obtenho a seguinte saída:
A palavra é:0X4321
Isso mostra que o primeiro byte do espaço de memória compartilhada (“u1.byte1”) é usado para armazenar o byte menos significativo (0X21) da variável “palavra”. Em outras palavras, o processador que estou usando para executar o código é little endian.
Como você pode ver, esse aplicativo específico de sindicatos pode exibir um comportamento dependente da implementação. No entanto, isso não deve ser um problema sério, porque para essa codificação de baixo nível, geralmente sabemos o endianness do processador. Caso não saibamos esses detalhes, podemos usar o código acima para descobrir como os dados estão organizados na memória.
Solução alternativa
Em vez de usar uniões, também podemos usar os operadores bit a bit para realizar a compactação ou descompactação de dados. Por exemplo, podemos usar o seguinte código para combinar duas variáveis de um byte, “byte3” e “byte4”, e produzir uma única variável de dois bytes (“palavra2”):
word2 =(((uint16_t) byte3) <<8) | ((uint16_t) byte4); Vamos comparar a saída dessas duas soluções nos casos little endian e big endian. Considere o código abaixo:
#include <stdio.h > # include <stdint.h >int main () {união {struct {uint8_t byte1; uint8_t byte2; }; uint16_t word1; } u1; u1.byte1 =0x21; u1.byte2 =0x43; printf ("Palavra1 é:% # X \ n", u1.word1); uint8_t byte3, byte4; uint16_t palavra2; byte3 =0x21; byte4 =0x43; palavra2 =(((uint16_t) byte3) <<8) | ((uint16_t) byte4); printf ("Palavra2 é:% # X \ n", palavra2); return 0;} Se compilarmos este código para um processador big endian, como TMS470MF03107 , a saída será:
Word1 é: 0X2143
Word2 é: 0X2143
No entanto, se o compilarmos para um pequeno processador endian, como STM32F407IE , a saída será:
Word1 é: 0X4321
Word2 é: 0X2143
Enquanto o método baseado em união exibe um comportamento dependente de hardware, o método baseado na operação de deslocamento leva ao mesmo resultado, independentemente do endianness do processador. Isso se deve ao fato de que, com a última abordagem, estamos atribuindo um valor ao nome de uma variável (“palavra2”) e o compilador se encarrega da organização da memória empregada pelo dispositivo. No entanto, com o método baseado em união, estamos alterando o valor dos bytes que constroem a variável “palavra1”.
Embora o método baseado em união exiba um comportamento dependente de hardware, ele tem a vantagem de ser mais legível e sustentável. É por isso que muitos programadores preferem usar uniões para esta aplicação.
Um exemplo prático de “manipulação de dados”
Ao trabalhar com protocolos de comunicação serial comuns, podemos precisar realizar a compactação ou descompactação de dados. Considere um protocolo de comunicação serial que envia / recebe um byte de dados durante cada seqüência de comunicação. Desde que estejamos trabalhando com variáveis de um byte, é fácil transferir os dados, mas e se tivermos uma estrutura de tamanho arbitrário que deve passar pelo link de comunicação? Nesse caso, temos que representar de alguma forma nosso objeto de dados como um array de variáveis longas de um byte. Assim que obtivermos essa representação de array de bytes, podemos transferir os bytes por meio do link de comunicação. Então, na extremidade do receptor, podemos embalá-los adequadamente e reconstruir a estrutura original.
Por exemplo, suponha que precisamos enviar uma variável float, “f1”, por meio da comunicação UART. Uma variável float geralmente ocupa quatro bytes. Portanto, podemos usar a seguinte união como um buffer para extrair os quatro bytes de “f1”:
união {float f; struct {uint8_t byte [4]; };} u1; O transmissor escreve a variável “f1” para o membro flutuante do sindicato. Em seguida, ele lê a matriz “byte” e envia os bytes pelo link de comunicação. O receptor faz o inverso:ele grava os dados recebidos no array “byte” de sua própria união e lê a variável float da união como o valor recebido. Poderíamos fazer essa técnica para transferir um objeto de dados de tamanho arbitrário. O código a seguir pode ser um teste simples para verificar essa técnica.
#include <stdio.h > # include <stdint.h >int main () {float f1 =5.5; buffer de união {float f; struct {uint8_t byte [4]; }; }; buffer de união buff_Tx; buffer de união buff_Rx; buff_Tx.f =f1; buff_Rx.byte [0] =buff_Tx.byte [0]; buff_Rx.byte [1] =buff_Tx.byte [1]; buff_Rx.byte [2] =buff_Tx .byte [2]; buff_Rx.byte [3] =buff_Tx.byte [3]; printf ("Os dados recebidos são:% f", buff_Rx.f); return 0;} A Figura 4 abaixo visualiza a técnica discutida. Observe que os bytes são transferidos sequencialmente.
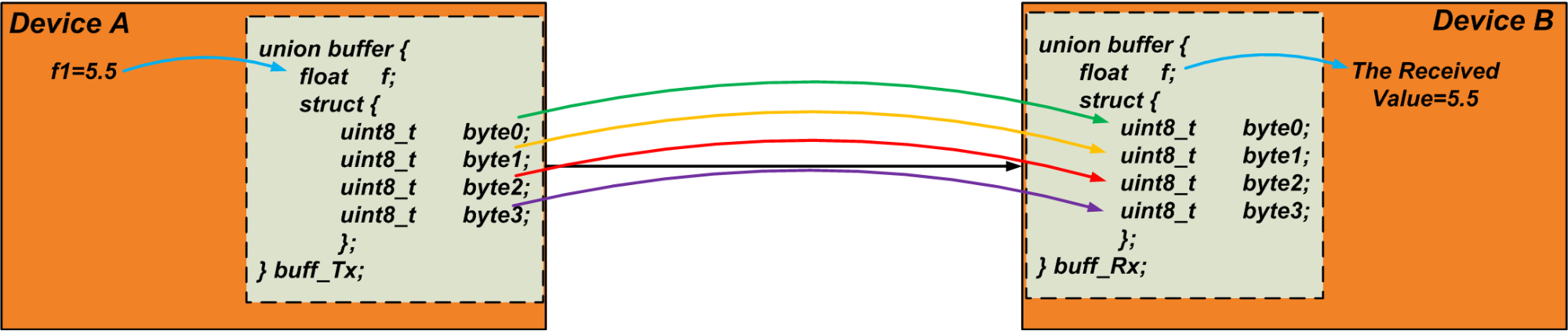
Figura 4
Conclusão
Enquanto o aplicativo original de uniões criava uma área de memória compartilhada para variáveis mutuamente exclusivas, com o passar do tempo, os programadores usaram amplamente uniões para uma aplicação completamente diferente:usar uniões para empacotar / descompactar dados. Esta aplicação particular de sindicatos envolve escrever um valor para um membro do sindicato e ler outro membro dele.
O “trocadilho de dados” ou o uso de uniões para compactação / descompactação de dados pode levar a um comportamento dependente do hardware. No entanto, tem a vantagem de ser mais legível e sustentável. É por isso que muitos programadores preferem usar uniões para esta aplicação. O “trocadilho de dados” pode ser particularmente útil quando temos um objeto de dados de tamanho arbitrário que deve passar por um link de comunicação serial.
Para ver uma lista completa dos meus artigos, visite esta página.
Dicas de firmware incorporado:como inicializar matrizes em C com formas de onda de sinal e outros dados de arquivo
Aprenda a linguagem de programação C incorporada:Compreendendo o objeto Union Data
Integrado
- Semáforos:serviços utilitários e estruturas de dados
- Estratégia e soluções do Exército para manutenção baseada em condições
- Os benefícios da adaptação de IIoT e soluções de análise de dados para EHS
- Construindo IA responsável e confiável
- O que é computação em névoa e o que isso significa para a IoT?
- C - Sindicatos
- Por que os dados e o contexto são essenciais para a visibilidade da cadeia de suprimentos
- Para gerenciamento de frota, IA e IoT são melhores juntos
- AIoT industrial:combinando inteligência artificial e IoT para a indústria 4.0
- Soluções de IIoT da Litmus e Oden Fuse para fabricação inteligente