


Rede de previsão de metamaterial com ressonador de anel dividido baseado em aprendizado profundo
Resumo
A introdução de “metamateriais” teve um impacto profundo em vários campos, incluindo o eletromagnético. Projetar a estrutura de um metamaterial sob demanda, no entanto, ainda é um processo extremamente demorado. Como um método de aprendizado de máquina eficiente, o aprendizado profundo tem sido amplamente usado para classificação e regressão de dados nos últimos anos e, de fato, apresentou bom desempenho de generalização. Construímos uma rede neural profunda para projetos sob demanda. Com a refletância necessária como entrada, os parâmetros da estrutura são calculados automaticamente e, em seguida, produzidos para atingir o propósito de projeto sob demanda. Nossa rede atingiu erros quadráticos médios baixos (MSE), com MSE de 0,005 nos conjuntos de treinamento e teste. Os resultados indicam que, usando o aprendizado profundo para treinar os dados, o modelo treinado pode guiar com mais precisão o projeto da estrutura, agilizando assim o processo de projeto. Em comparação com o processo de design tradicional, o uso de aprendizado profundo para orientar o design de metamateriais pode atingir finalidades mais rápidas, precisas e convenientes.
Introdução
A nano-óptica é um assunto interdisciplinar de nanotecnologia e óptica. Nos últimos anos, ao projetar constantemente estruturas com diferentes tamanhos de sub comprimentos de onda a fim de obter interações especiais com a luz incidente, os cientistas conseguiram manipular certas características de transmissão de luz [1,2,3]. Desde que metamateriais foram propostos, eles têm atraído a atenção de muitos estudiosos neste campo e, concomitantemente, seus estudos teóricos relacionados [4, 5], processos [6, 7] e pesquisas aplicadas [8] estão todos avançando na mesma velocidade. Muitas funções peculiares foram realizadas, incluindo imagens holográficas, absorção perfeita [9] e lentes planas [10]. Devido ao rápido desenvolvimento da tecnologia terahertz e suas características únicas, também se tornou um tópico de pesquisa popular na área de metamateriais nos últimos anos [11,12,13].
Embora a aplicação de metamateriais seja muito ampla, o método de design tradicional requer que o designer execute repetidamente cálculos numéricos complexos na estrutura que está sendo projetada. Este processo consome muito tempo e recursos de computação. Portanto, é urgente encontrar novas maneiras de simplificar ou mesmo substituir os métodos tradicionais de design.
Como um campo interdisciplinar, o aprendizado de máquina cobre muitas disciplinas, incluindo ciências da vida, ciências da computação e psicologia, e tem trabalhado para usar computadores para imitar e implementar processos de aprendizagem humana para adquirir novos conhecimentos ou habilidades. O princípio básico do aprendizado de máquina pode ser simplesmente descrito como o uso de algoritmos de computador para obter a correlação entre uma grande quantidade de dados ou para prever as regras entre dados semelhantes e, finalmente, atingir o propósito de classificação ou regressão. Até agora, muitos algoritmos de aprendizado de máquina foram aplicados à designação de metamateriais e obtiveram resultados significativos, incluindo algoritmos genéticos [14], algoritmos de regressão linear [15] e redes neurais rasas. À medida que a estrutura se torna cada vez mais complexa e as mudanças na estrutura se tornam mais diversas, os problemas exigirão mais tempo para serem resolvidos. Ao mesmo tempo, a natureza altamente não linear dos problemas torna difícil para algoritmos simples de aprendizado de máquina obter previsões precisas. Além disso, para projetar uma estrutura de metamaterial correspondente para um efeito eletromagnético específico, os projetistas devem tentar realizar cálculos numéricos complexos na estrutura. Esses processos consumirão uma quantidade enorme de tempo e recursos de computação.
Como um dos algoritmos mais destacados no campo do aprendizado de máquina, o aprendizado profundo tem feito conquistas mundialmente conhecidas em vários campos relacionados, como visão computacional [16], extração de recursos [17] e processamento de linguagem natural [18]. Ao mesmo tempo, os sucessos em outros campos não relacionados à computação são numerosos, incluindo muitas disciplinas básicas como ciências da vida, química [19] e física [20] [21]. Portanto, a aplicação de aprendizado profundo ao projeto de metamateriais também é uma direção de pesquisa quente no momento, e muitos trabalhos pendentes surgiram [22,23,24].
Inspirado no aprendizado profundo, este artigo relata um estudo usando um algoritmo de aprendizado de máquina baseado em uma rede neural profunda para prever a estrutura do ressonador de anel dividido (SRR) para atingir o objetivo de projetar sob demanda. Além disso, a rede direta e a rede reversa são treinadas de forma inovadora separadamente, o que não apenas pode melhorar a precisão da rede, mas também pode atingir funções diferentes por meio de uma combinação flexível. Os resultados mostram que o método pode atingir MSE de 0,0058 e 0,0055 no conjunto de treinamento e no conjunto de validação, respectivamente, e apresenta boa robustez e generalização. Com o modelo treinado orientando o projeto de estruturas de metamateriais, o ciclo de projeto pode ser reduzido para dias ou mesmo horas, e a melhoria na eficiência é óbvia. Além disso, esse método também tem boa escalabilidade e só precisa alterar os dados do conjunto de treinamento para projetar diferentes entradas ou diferentes estruturas sob demanda.
Teoria e método
Construção do modelo COMSOL
A fim de mostrar que o aprendizado profundo pode ser aplicado ao projeto reverso de estruturas de metamateriais, modelamos uma estrutura SRR de três camadas que consiste em um anel de ouro, um fundo de sílica e um fundo de ouro para observar sua resposta eletromagnética sob a ação do luz incidente. Conforme mostrado na Fig. 1, o ângulo de abertura θ do anel de ouro, o raio interno r do anel, e a largura da linha d do anel são selecionados como variáveis independentes desta estrutura. Quando um feixe de luz polarizada linearmente entra nos metamateriais normalmente, as curvas de refletância do comprimento de onda sob diferentes estruturas são obtidas alterando as variáveis estruturais. A espessura do anel Au é de 30 nm, da parte inferior de SiO 2 é de 100 nm, e da parte inferior do Au é de 50 nm, e o tamanho dos metaátomos é de 200 nm por 200 nm.
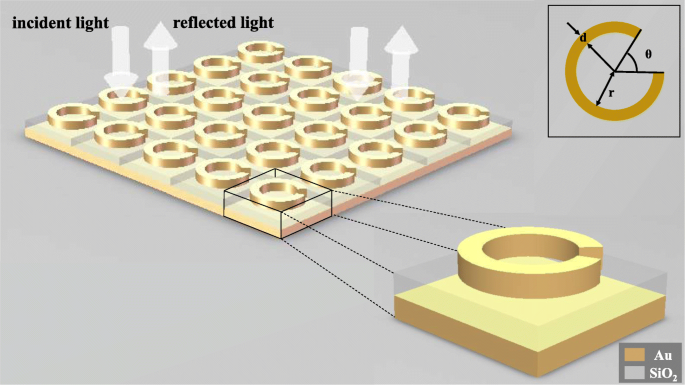
Diagrama esquemático da estrutura. Toda a metassuperfície é composta de metaátomos dispostos repetidamente em duas direções, e a luz polarizada linearmente é incidente perpendicular à metassuperfície. Cada meta-átomo é composto de um anel de ouro, uma base de sílica e uma base de ouro, de cima para baixo. O anel de ouro superior contém três parâmetros estruturais, a saber, a largura da linha d , o ângulo de abertura θ , e o raio do anel interno r
Use o COMSOL Multiphysics 5.4 [25] para modelagem, escolha a dimensão do espaço tridimensional, escolha óptica ≥ óptica de onda ≥ domínio de frequência de onda eletromagnética (ewfd) para o campo físico e selecione o domínio de comprimento de onda para pesquisa. Crie o modelo acima em geometria. O material de cada parte e seu índice de refração são definidos em ordem no material, e portas e condições periódicas são adicionadas no domínio da frequência da onda eletromagnética.
Construindo um modelo de rede neural de aprendizado profundo
Construímos uma rede reversa e uma rede direta para a estrutura do metamaterial. A rede reversa pode prever os parâmetros estruturais do SRR a partir de dois conjuntos de curvas de refletância de comprimento de onda com diferentes direções de polarização. A rede direta pode prever as curvas de refletância do comprimento de onda em duas direções de polarização pelos parâmetros estruturais dados. A função da rede reversa é o corpo principal da função de previsão. O papel da rede direta é verificar os resultados da previsão da rede reversa para observar se os resultados da previsão atendem à resposta eletromagnética necessária.
Use o eclipse 2019 como a plataforma de desenvolvimento, o python3.7 como a linguagem de programação e o TensorFlow 1.12.0 como a estrutura de desenvolvimento.
As duas redes são treinadas separadamente para evitar que os resultados de formação de cada rede sejam afetados pelo erro da outra rede, o que garante a respetiva precisão das duas redes.
Conforme mostrado na Fig. 2, outra vantagem de treinar as duas redes separadamente é que elas podem ser usadas para diferentes propósitos por meio de diferentes sequências de conexão:(a) rede reversa + rede direta, que pode usar a curva de refletância de comprimento de onda dada para calcular o estruturar parâmetros, fazer previsões e verificar se os resultados da previsão atendem às necessidades e (b) usar a rede direta sozinha pode simplificar o processo de cálculo do método de cálculo numérico e reduzir o tempo de cálculo.
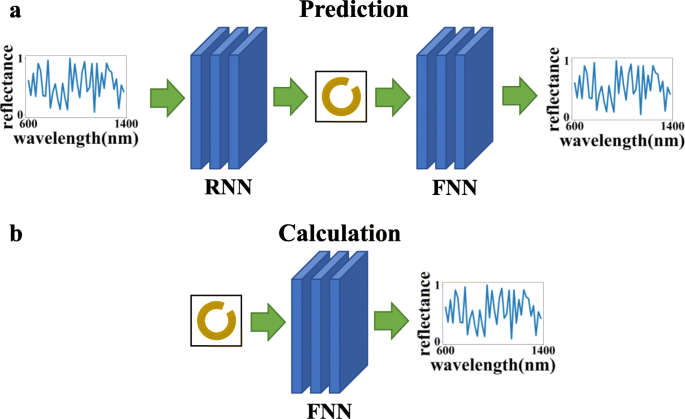
Nesta figura, FNN se refere à rede neural direta e RNN se refere à rede neural reversa. O gráfico superior ( a ) indica que as duas redes podem ser conectadas para atingir o efeito de previsão e verificação, e o gráfico inferior ( b ) indica que a rede de resposta direta sozinha pode ser usada para calcular a resposta óptica
Vale ressaltar que o processo de entrada e obtenção dos resultados do modelo treinado utilizando o método de aprendizado profundo leva um tempo extremamente curto. E sempre que novos dados são obtidos por meio de simulação ou experimento, o modelo pode ser usado para treinamento posterior. Estudos têm mostrado que com o aumento contínuo dos dados de treinamento, a precisão do modelo será cada vez maior e o desempenho de generalização cada vez melhor [26].
Os parâmetros da estrutura são conjuntos múltiplos de autovalores contínuos, que pertencem ao problema de regressão. Nos últimos anos, as redes totalmente conectadas têm sido o foco das redes de aprendizado profundo em problemas de regressão e mostraram as características de alta confiabilidade, grande taxa de transferência de dados e baixa latência. Fazer alguns ajustes em uma rede totalmente conectada permitirá que a rede preveja melhor a estrutura.
Conforme mostrado na Fig. 3b, a rede direta é uma rede totalmente conectada na qual todos os nós das duas camadas adjacentes estão conectados um ao outro. Os dados de entrada são o parâmetro estrutural e a saída é a curva de refletância do comprimento de onda das duas direções de polarização. Conforme mostrado na Fig. 3a, a rede reversa consiste em uma camada de extração de recursos (camada FE) e uma camada totalmente conectada (camada FC). A camada FE inclui dois conjuntos de redes totalmente conectadas que não estão conectadas entre si e processa as curvas de refletância do comprimento de onda da luz polarizada linearmente nas duas direções para extrair alguns recursos dos dados de entrada. A camada FC aprenderá os recursos extraídos e produzirá os parâmetros estruturais. Devido às características de alta coesão e baixo acoplamento entre as curvas de refletância de comprimento de onda em diferentes estados de polarização, separar as entradas de dois conjuntos de dados de luz polarizada em diferentes direções pode evitar que a rede seja perturbada pela padronização de dados durante o processo de extração de dados. A rede direta não envolve vários conjuntos de entradas e não precisa considerar a interferência mútua entre os dados, portanto, não tem uma camada de extração de recursos.
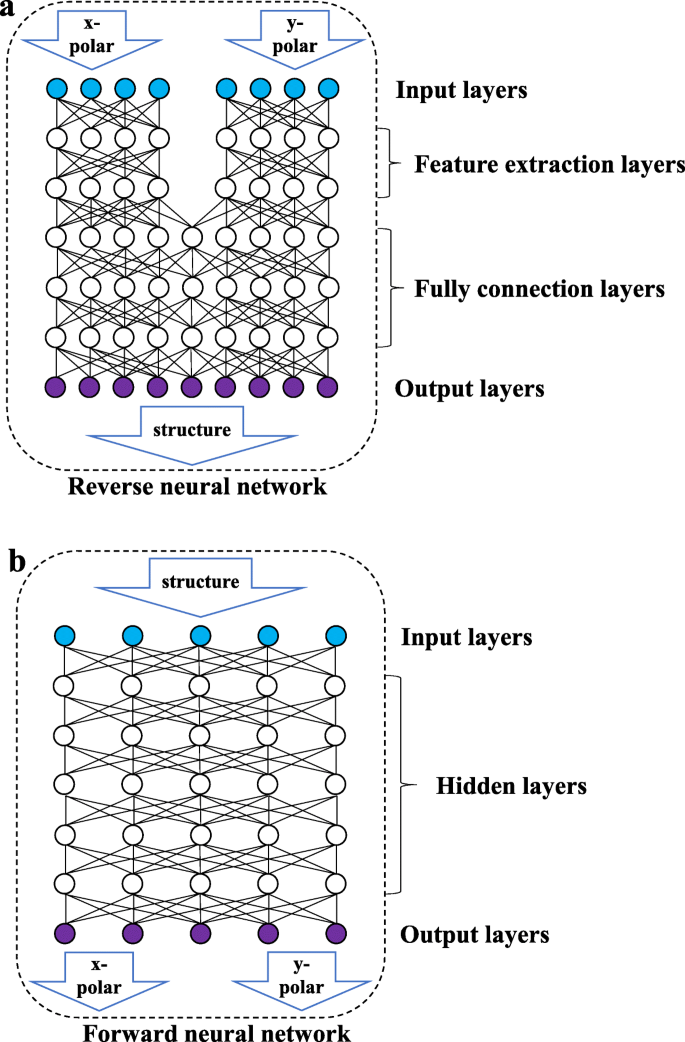
Diagrama esquemático da estrutura da rede. A figura acima mostra a rede reversa. A rede reversa consiste em uma camada de entrada, uma camada de extração de recursos, uma camada totalmente conectada e uma camada de saída. A figura a seguir mostra a rede direta, que consiste em uma camada de entrada, uma camada oculta e uma camada de saída
Para determinar a estrutura de rede ideal, redes em estruturas diferentes são treinadas usando o mesmo conjunto de dados. Conforme mostrado na Fig. 4, após os dados terem experimentado 50 épocas (quando todos os dados passaram por um treinamento completo, é chamado de época), o MSE alcançado pela rede direta de diferentes estruturas. Como pode ser visto na imagem à esquerda da Fig. 4, quando a rede direta contém 5 camadas ocultas, cada camada contendo 100 nós, o MSE mais baixo alcançado é cerca de 0,0174, então a rede direta desta estrutura será selecionada.
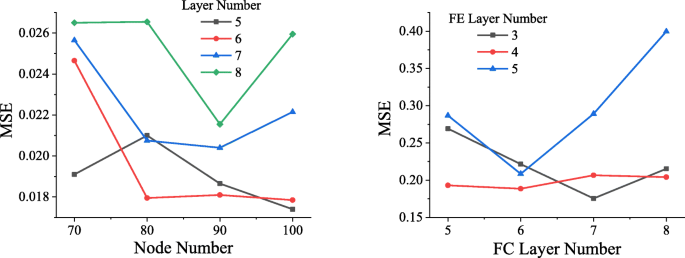
Comparação de estruturas de rede. Na figura à esquerda, o eixo horizontal representa o número de nós em cada camada, o eixo vertical representa MSE e o preto, vermelho, azul e verde representam a situação em que a camada oculta contém 5, 6, 7 e 8 camadas, respectivamente. Na figura à direita, o eixo horizontal indica o número de camadas na camada totalmente conectada, o eixo vertical indica MSE e as linhas preta, vermelha e azul indicam a situação quando a camada FE inclui 3, 4 e 5 , respectivamente
Da mesma forma, diferentes redes de redes reversas foram treinadas, e o volume de treinamento ainda foi definido para 50 épocas. O resultado é mostrado na figura à direita da Fig. 4. Quando o número de camadas FC é 7 e o número de camadas FE é 3, a rede atinge o MSE mais baixo, que é cerca de 0,1756.
Descobrimos que um número maior de camadas de rede produzirá um fenômeno de explosão de gradiente, que fará com que a rede falhe em convergir, e a perda é infinita, portanto não está listada na figura.
Pré-processamento de dados
A fim de treinar uma rede direta mais confiável, os dados de refletância são redivididos e costurados com a refratividade de Au e SiO 2 correspondente a cada frequência. Os dados agrupados são então normalizados e inseridos na rede direta, o que pode melhorar muito a precisão da rede direta.
A fim de garantir que os dados com valores maiores não tenham um impacto maior na rede do que os dados com valores menores, os dados de entrada precisam ser normalizados para fazer com que cada coluna de dados esteja em conformidade com a distribuição normal padrão (o valor médio é 0, a variação é 1) e, em seguida, os dados processados x pode ser expresso da seguinte forma:
$$ x =\ frac {\ left ({x} _0 \ hbox {-} \ mu \ right)} {\ sigma} $$ (1)
Na expressão, x 0 são os dados originais da amostra, μ a média da amostra e σ o desvio padrão da amostra. Se os dados de entrada não forem redivididos, a refletância será distorcida após a normalização, o que reduzirá a precisão da rede. Os dados redivididos não afetarão sua distribuição devido à normalização.
Método de rede neural
O princípio da rede neural é construir muitos neurônios (nós), imitando a maneira como o cérebro humano funciona e aprende [27]. Os neurônios são conectados uns aos outros e a saída é ajustada ajustando o peso da conexão. A saída do j o nó de uma camada pode ser expresso da seguinte forma:
$$ {y} _j =\ frac {\ sum \ limits_ {i =1} ^ nf \ left ({w} _i {x} _i + {b} _j \ right)} {n} $$ (2)
f é a função de ativação, w i é o peso da conexão do i da camada anterior o nodo conectado ao j o nodo, x i é a saída do i o nó da camada anterior, b j é o termo de polarização deste nó, e n é o número de nós na camada anterior conectados ao j o nodo.
Escolha de uma função de ativação
Para atender à alta não linearidade do problema inverso, a função ELU [28] é utilizada como a função de ativação de cada camada de neurônios [28]. A saída f ( x ) da função ELU pode ser expressa como forma por partes da seguinte forma:
$$ f (x) =\ left \ {\ begin {array} {c} x \\ {} \ alpha \ left ({e} ^ x-1 \ right) \ end {array} \ right. {\ displaystyle \ begin {array} {c}, \\ {}, \ end {array}} {\ displaystyle \ begin {array} {c} x \ ge 0 \\ {} x <0 \ end {array}} $$ (3)
Nesta função, x é a entrada original e o valor do parâmetro para α varia de 0 a 1.
A razão para usar a função de ativação é que a função de ativação altera a capacidade de expressão não linear de cada camada da rede, melhorando assim a capacidade geral de ajuste não linear da rede. Conforme mostrado na Fig. 5, a função ELU combina as vantagens das funções de ativação de sigmoide e unidade linear retificada (ReLU). Quando x <0, tem melhor saturação suave, o que torna a rede mais robusta para alterações de entrada e ruído. Quando x > 0, não há saturação, o que ajuda a amenizar o desaparecimento do gradiente da rede. A característica de que o valor médio de ELU é próximo a 1 pode tornar a rede mais fácil de se ajustar. O resultado prova que usando ELU como a função de ativação do aprendizado profundo, a rede neural melhora a robustez da rede significativamente.
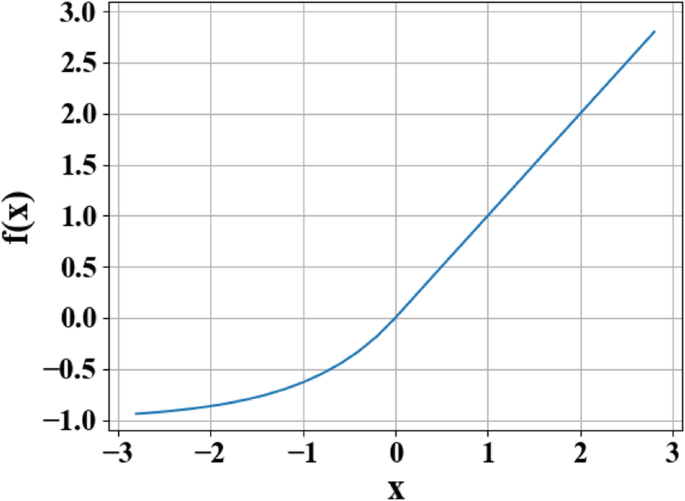
Curva de função de unidades lineares exponenciais (ELU). Na figura, x representa a entrada original e f ( x ) representa a saída da função
Esquema de inicialização de peso
O método de inicialização do peso da rede de cada camada determina a velocidade de adaptação da rede e ainda determina se a rede pode caber ou não. A inicialização da escala de variância é baseada na quantidade de dados de entrada em cada camada e extrai pesos de uma distribuição normal truncada centrada em 0, de modo que a variância pode ser reduzida a um determinado intervalo, então os dados podem ser espalhados mais profundamente pela rede [29 ] Nesta estrutura de rede, usar a inicialização de escala de variação pode tornar a velocidade de convergência da rede significativamente mais rápida.
Solução de sobreajuste
Devido à insuficiência de dados, a rede produzirá algum sobreajuste. Com o overfitting reduzido, a rede pode ter um bom desempenho de generalização em dados fora do conjunto de treinamento. A regularização L2 (também chamada de redução de peso em problemas de regressão) é usada para processar o peso w . A saída regularizada L pode ser expresso da seguinte forma:
$$ L ={L} _0 + \ frac {\ lambda} {2n} \ sum {w} ^ 2 $$ (4)
Na Eq. (4), L 0 representa a função de perda original, e um termo de regularização \ (\ frac {\ lambda} {2n} \ sum {w} ^ 2 \) é adicionado nesta base, onde λ representa o coeficiente de regularização, n a taxa de transferência de dados e w O peso. Depois de adicionado o prazo de regularização, o valor do peso w tende a diminuir de maneira geral, e a ocorrência de valores excessivos pode ser evitada, então w também é chamado de atenuação de peso. A regularização L2 pode reduzir o peso para evitar uma grande inclinação da curva ajustada, aliviando assim efetivamente o fenômeno de sobreajuste da rede e ajudando a convergir.
Com base nisso, o método de abandono também é usado. Este método pode ser visualmente considerado como “ocultando” uma certa escala de nós de rede para cada treinamento, e ocultando nós diferentes durante cada treinamento, para atingir o objetivo de treinar várias “redes parciais”. E por meio do treinamento, a maioria das “redes parciais” pode representar com precisão os alvos, e os resultados de todas as “redes parciais” podem ser classificados para obter a solução dos alvos.
Usar a regularização L2 e os métodos de abandono mencionados acima pode não apenas aliviar efetivamente a baixa generalização causada por dados insuficientes, mas também reduzir o impacto de uma pequena quantidade de dados errôneos no conjunto de dados sobre os resultados do treinamento.
Nesta estrutura de rede e conjunto de dados, com dropout =0,2 e coeficiente de regularização L2 λ =0,0001, a rede pode obter uma precisão semelhante no conjunto de treinamento e no conjunto de teste, alcançando assim um alto desempenho de generalização.
Resultado e discussão
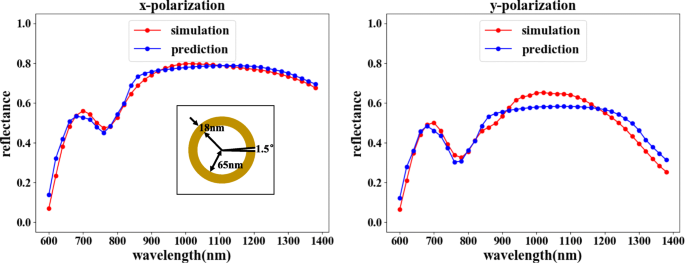
Após o treinamento, nossa rede direta pode atingir um alto grau de adaptação, com um MSE de 0,0015, o que mostra que a saída é muito semelhante aos resultados da simulação, conforme mostrado na Fig. 6. Isso também garante que, ao treinar a rede reversa, o os resultados da rede reversa podem ser verificados com segurança.
Resultados do treinamento da rede direta. Os parâmetros estruturais correspondentes são θ =50 °, r =60 nm, e d =10 nm. Na figura, o eixo horizontal representa o comprimento de onda da luz incidente, o eixo vertical representa a refletividade, a linha vermelha representa o resultado da simulação do COMSOL e a linha azul representa o resultado do treinamento da rede. A figura à esquerda mostra a curva de refletividade correspondente ao x - entrada polarizada, e a figura à direita mostra a curva de refletividade correspondente ao y - entrada polarizada
Finalmente, iremos gerar dois modelos da rede aprendida e conectar os dois modelos para alcançar a função de previsão.
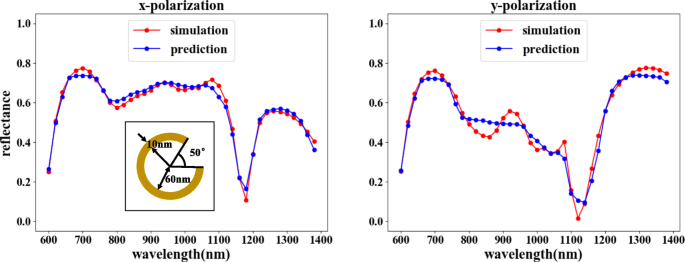
A função de previsão pode escolher a combinação mostrada na Fig. 2a. A rede reversa prevê a estrutura correspondente de acordo com a curva de refletância do comprimento de onda necessária e a rede direta verifica a resposta óptica da estrutura. Conforme mostrado na Fig. 7, comparando a refletância verificada com a refletância de entrada, as características de refletância da luz incidente nas duas direções de polarização são basicamente consistentes. Embora a incompatibilidade de refletância menor seja observável para determinados valores de comprimento de onda, a tendência geral de correspondência é claramente irrefutável, uma vez que os erros estão dentro de uma faixa aceitável.
A rede reversa seguida por uma rede direta pode atingir o propósito de previsão. Na figura, o eixo horizontal representa o comprimento de onda da luz incidente, o eixo vertical representa a refletividade, a linha vermelha representa o resultado da simulação do COMSOL e a linha azul representa o resultado do treinamento da rede. A figura à esquerda mostra a curva de refletividade correspondente ao x - entrada polarizada, e a figura à direita mostra a curva de refletividade correspondente ao y entrada polarizada. Os resultados previstos para a curva de refletância do comprimento de onda de entrada são θ =1,5 °, r =65 nm, e d =18 nm
Conclusão
Neste artigo, apresentamos nossa rede de aprendizagem profunda projetada, capaz de criar vários efeitos por meio do emprego de combinações flexíveis de configurações de rede. Nossa rede reversa projetada pode prever a estrutura necessária usando a curva de refração do comprimento de onda de entrada, o que pode reduzir muito o tempo necessário para resolver o problema reverso e atender a diferentes necessidades por meio da utilização de combinações flexíveis. Os resultados indicam que a rede alcançou uma maior precisão nas previsões, o que implica ainda que o design sob demanda pode ser resolvido por meio de nosso método. O uso de aprendizado profundo para orientar o projeto de metamateriais pode obter automaticamente estruturas de metamateriais mais precisas, um resultado inatingível por métodos de projeto tradicionais.
Disponibilidade de dados e materiais
A data em que o manuscrito vem de nossa rede de simulação, não podemos compartilhá-la por alguns motivos pessoais.
Abreviações
- ELU:
-
Unidades lineares exponenciais
- Camada FC:
-
Camada totalmente conectada
- Camada FE:
-
Camada de extração de recursos
- FNN:
-
Rede neural direta
- MSE:
-
Erros quadráticos médios
- ReLU:
-
Unidade linear retificada
- RNN:
-
Rede neural reversa
- SRR:
-
Ressonador de anel dividido
Geração de sinal RF simples / duplo amplamente ajustável por um laser monolítico de DFB de três seções
Nanopartículas Co / CoP encapsuladas em nanotubos de carbono dopados com N, P em nanofolhas de estrutura orgânica de metal nanoporoso para reações de redução e evolução de oxigênio
Nanomateriais
- Aproveitando FPGAs para aprendizado profundo
- Processador automotivo apresenta acelerador AI integrado
- Reconhecimento de dígitos AI com PiCamera
- Um robô móvel com prevenção de obstáculos baseada na visão
- Melhorando o desempenho de ativos com aprendizado de máquina
- Aprendizagem não supervisionada com neurônios artificiais
- WND faz parceria com a Sigfox para fornecer rede IoT ao Reino Unido
- Método de String Split() em Java:Como dividir String com exemplo
- As propriedades elétricas de compostos híbridos baseados em nanotubos de carbono multifoliados com nanoplacas de grafite
- Preveja a vida útil da bateria com aprendizado de máquina