


Introdução à ciência de dados | Componentes Chave | Tipos e oportunidades
O que é Ciência de Dados?
Data Science é um campo interdisciplinar que envolve o uso de métodos, processos e sistemas científicos para coletar, preparar e analisar dados na forma estruturada e não estruturada. A ciência de dados faz uso de vários campos, incluindo matemática, estatística, bancos de dados, ciência da informação e ciência da computação. Os dados podem ser de vários tipos e de vários tamanhos.
Necessidade de Ciência de Dados como um campo separado:
A principal razão para atualizar a ciência de dados para o nível de um campo separado é a taxa de dados em crescimento exponencial ao nosso redor. As estimativas mostram que cerca de 1,7 megabytes de dados serão produzidos por segundo até 2020. A acumulação de dados digitais chegará a 44 trilhões de gigabytes. Com uma quantidade tão grande de dados, entendê-los e armazená-los se torna cada vez mais difícil. Como resultado, precisamos de uma maneira de estudar e dar sentido a esses dados. Assim, a Ciência de Dados foi reconhecida como um campo separado. 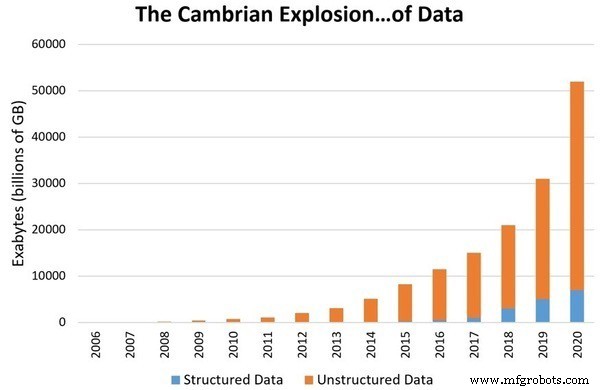
Ciência de dados ao nosso redor:
As empresas estão usando a ciência de dados para entender e classificar facilmente seus processos de dados dentro da empresa. Por exemplo, o Google usa Data Science para personalizar os anúncios exibidos aos usuários nos sites que eles usam. Isso é feito por meio do programa AdSense, que permite que os editores veiculem conteúdo para públicos-alvo.
Da mesma forma, a Uber calcula quanto deve ser cobrado de um cliente, quando dar descontos e para quem. O Airbnb ajuda as pessoas a estimar o preço pelo qual devem alugar suas casas usando o Data Science. Em termos simples, podemos entender isso pensando em clientes e usuários como dados brutos e a ciência de dados ajuda a interpretar esses dados. 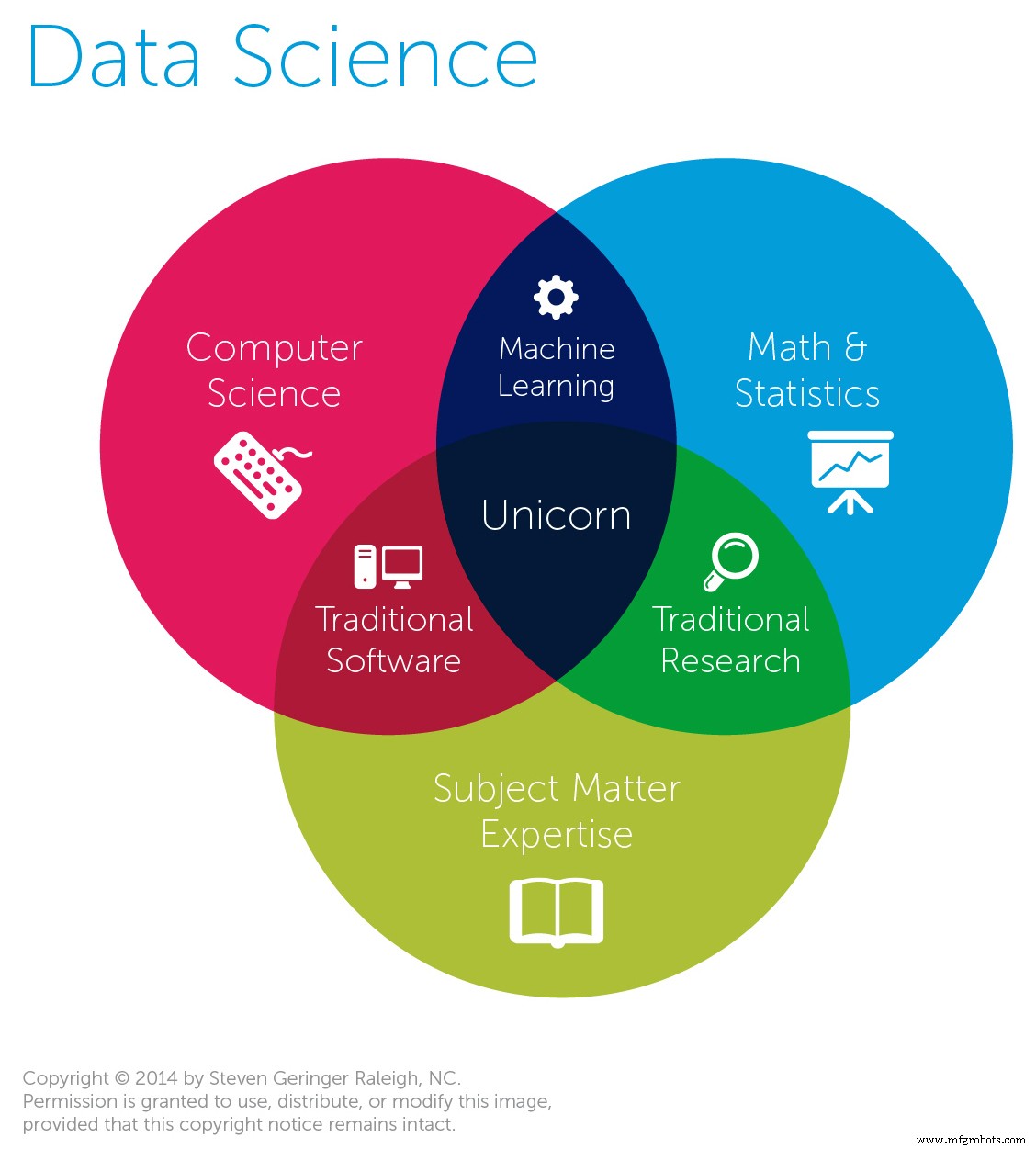
Ciência de dados em organizações governamentais e não governamentais:
Os dados são um ativo crítico para organizações governamentais. Há uma quantidade crescente de dados coletados todos os dias. Por isso, eles exigem uma maneira de classificar e armazenar todos esses dados, o que pode ser feito por meio de Data Science. Da mesma forma, organizações não governamentais também usam ciência de dados. O WWF usa a ciência de dados para mostrar informações em uma questão estatística sobre questões de vida selvagem e, portanto, tornar sua causa efetiva.
Oportunidades em Ciência de Dados:
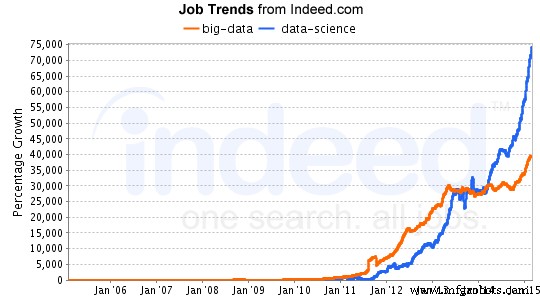
À medida que o campo da ciência de dados continua a crescer, as oportunidades de emprego nesse campo também aumentam exponencialmente. A análise feita pelo LinkedIn sobre o crescimento do emprego em ciência de dados mostrou um grande aumento no campo da ciência de dados, especialmente nos últimos 30 anos. Se você estiver interessado em ciência de dados, poderá obter cursos gratuitos on-line. Confira este tutorial sobre um lounge comum.
Componentes principais:
Agora, apresentaremos algumas informações sobre ciência de dados e seus vários componentes.
1:Programação:
A ciência de dados tem tudo a ver com dados. Para organizar e analisar esses dados usamos programação. As linguagens de programação são de vários tipos. Os dois mais difundidos são Python e R.
Python: Python é a linguagem de programação mais legível e flexível, daí seu uso generalizado. Ele tem muitos pacotes estatísticos e numéricos poderosos, incluindo NumPy e pandas, Matplotlib, Tensorflow, iPython etc. Python é muito mais rápido e fácil de aprender.
R: R é outra linguagem de programação, mas a maior parte é focada em técnicas estatísticas e gráficas. O R é amplamente utilizado entre estatísticos e mineradores de dados para desenvolver software estatístico e análise de dados. É uma linguagem de código aberto.
2:Dados e seus tipos:
O próximo componente chave são os dados em si. Para entender os dados, devemos primeiro entender seus tipos.
Dados estruturados: Dados estruturados referem-se a informações com alto grau de organização. Ele pode ser facilmente representado em forma de tabela, pode ser armazenado e processado em bancos de dados.
Dados não estruturados: Dados não estruturados são informações que não possuem um modelo de dados ou não são organizadas. Pode consistir em texto ou dados como datas, números, e-mails, arquivos PDF, imagens, vídeos etc.
Linguagem Natural: Dados na forma de idiomas escritos usados para comunicação, como inglês, espanhol e urdu, etc. Podem ser considerados como um subtipo de dados não estruturados.
Imagem, vídeo, áudio: Imagens, vídeos e áudios também são desestruturados na forma. Eles são gerados usando câmeras e microfones. O uso crescente é visto em smartphones onde imagens e vídeos são salvos e processados todos os dias.
Dados baseados em gráficos: Grafo é um conjunto de vértices e arestas. É uma estrutura matemática usada para mostrar a relação entre duas entidades.
Gerado por máquina: Dados gerados por máquina são criados por sistemas de computador, aplicativos ou máquinas sem o envolvimento de humanos.
3:Estatística, Probabilidade e sua relação com Data Science:
Estatísticas: Estatística é um ramo da matemática que lida com a coleta, interpretação, análise, apresentação e organização de dados. Ele usa pro0gamming ti analisar dados.
Probabilidade: Probabilidade é a medida da probabilidade de um evento ocorrer. É quantificado como um número entre 0 e 1, onde 0 indica impossibilidade e 1 indica certeza.
Relação com a ciência de dados: Estatística e probabilidade estão relacionadas à ciência de dados. Eles são a base do processamento e análise de dados. Usamos essas duas ciências em relação à ciência de dados para interpretar os dados corretamente.
4:Aprendizado de máquina:
Aprendizado de máquina é o campo da ciência da computação decorrente da IA. Ele usa técnicas estatísticas para dar aos computadores a capacidade de aprender sem serem programados. A máquina melhora progressivamente seu desempenho em uma tarefa específica, alterando a estrutura ou o programa. Existem três objetivos principais do aprendizado de máquina. Um, para aprender as mudanças e a representação dessas mudanças. Segundo, para generalizar o desempenho, para que seja eficaz não em uma única tarefa, mas em tarefas semelhantes. Terceiro. Para melhorar o desempenho de uma máquina e encontrar maneiras de evitar a degradação do desempenho. Na ciência de dados, o aprendizado de máquina é usado em algoritmos, métodos de regressão e classificação. Ele é usado para prever o resultado de dados sendo processados de diferentes maneiras.
5:Big Data:
Big Data é o nome dado aos dados são uma quantidade tão grande que armazenar ou processar esses dados requer um grande número de computadores. É caracterizada por três Vs:
Volume: Dados em grandes volumes que variam de terabytes a zettabytes.
Variedade: Os dados podem mostrar muita variedade e diversidade. Pode ser uma mistura de dois ou mais tipos de dados, por exemplo, ambos estruturados e não estruturados.
Velocidade: Os dados estão sendo gerados a uma taxa em constante crescimento. Essencialmente, é a velocidade dos dados. 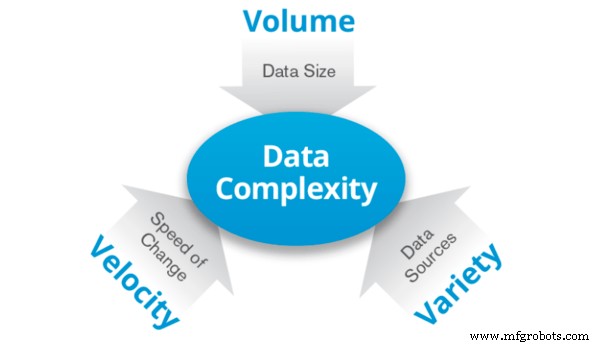
Na ciência de dados, os dados são agrupados em várias formas e tipos. Big data pode ser referido a enormes volumes de dados que não podem ser processados usando aplicativos tradicionais. Os cientistas de dados usam diferentes ferramentas para estudar e processar big data, por exemplo, Hadoop, Spark, R e Java etc.
Tecnologia industrial
- Variáveis C# e tipos de dados (primitivos)
- Tipos de dados Python
- Uma introdução à computação de ponta e exemplos de casos de uso
- 5 tipos diferentes de data center [com exemplos]
- C - Tipos de dados
- MATLAB - Tipos de dados
- C# - Tipos de dados
- Tipos e classificação do processo de usinagem | Ciência da Manufatura
- Fresadoras - Introdução e Tipos Discutidos
- Significado e Tipos do Processo de Fabricação