


O que é computação sem servidor?
O gerenciamento de infraestrutura adiciona uma camada adicional de complexidade ao fluxo de trabalho de desenvolvimento de software moderno. Manter os servidores em funcionamento, cuidar das atualizações de segurança e dimensionar os recursos ocupa um tempo valioso das equipes de DevOps. Com a computação sem servidor, todas as operações de infraestrutura são tratadas pelo provedor de serviços. Como tal, o serverless permite que as equipes de desenvolvimento se concentrem em escrever código em vez de gastar muito tempo no gerenciamento de infraestrutura.
Este artigo explica o que é a computação sem servidor e como ela se compara a diferentes modelos de implantação em nuvem. Também exploraremos os prós e contras do serverless e falaremos sobre alguns casos de uso comuns.
O que é computação sem servidor?
A computação sem servidor é um método de implantação e execução de código na nuvem sem lidar com o provisionamento de servidor e o gerenciamento de infraestrutura. Apesar do nome, serverless ainda depende de servidores físicos ou em nuvem para execução de código. No entanto, os desenvolvedores não estão preocupados com a infraestrutura subjacente. Isso é deixado para o provedor sem servidor que aloca dinamicamente os recursos de computação necessários e os gerencia em nome do usuário.
Para os desenvolvedores, isso significa zero tempo gasto na administração do servidor, manutenção, dimensionamento de recursos ou planejamento de capacidade. Eles simplesmente carregam seu código e permitem que o provedor execute a lógica do lado do servidor com base em diferentes eventos ou solicitações. Em contraste com os modelos familiares de cobrança em nuvem, os serviços sem servidor são cobrados com base no número de vezes que o código é executado ou quando um determinado evento é acionado.
Como funciona a computação sem servidor?
Em um ambiente sem servidor, o código é acionado por eventos e executado como uma função. É por isso que o serverless é frequentemente associado a “Functions-as-a-Service” ou FaaS, que é um conceito semelhante. FaaS é um modelo de nuvem orientado a eventos que lida com a lógica do lado do servidor para execução de código sem qualquer intervenção do usuário. Esses eventos podem ser qualquer coisa, desde uma simples solicitação HTTP, chamada de API, até uma consulta de banco de dados ou upload de arquivo.
As funções são executadas em contêineres sem estado. Isso significa que os recursos de computação para executar uma função são provisionados apenas quando invocados. Nenhum dado é mantido na RAM ou gravado no disco. Depois que a solicitação for atendida, o estado do aplicativo é redefinido e não há memória da transação. Fazer uma nova solicitação exige que os recursos sejam provisionados do zero e o código seja executado sem nenhuma referência à invocação anterior.
Para acomodar esse estado sem estado, os aplicativos precisam ser arquitetados como funções que podem ser executadas em contêineres sem estado. Isso geralmente é feito por meio de microsserviços. Grandes aplicativos monolíticos são divididos em segmentos menores e interconectados por meio de uma API. Os aplicativos Monolith ainda podem ser executados como funções únicas, mas essa não é uma prática comum. Tendo em mente que um novo contêiner de computação é provisionado a cada solicitação, funções grandes afetarão negativamente a velocidade e a duração da execução.
As funções FaaS não são executadas infinitamente. Eles são encerrados após um certo período de tempo ao serem chamados. Na maioria dos casos, as funções atingem o tempo limite após cerca de cinco minutos. Isso significa que os aplicativos que executam tarefas de longa duração precisam ser reprojetados para levar em conta os limites de encerramento.
O provisionamento e a inicialização de contêineres para execução de funções também levam tempo. Isso geralmente é medido em milissegundos. No entanto, funções complexas podem levar vários segundos para inicializar, causando maior latência.
Existem dois métodos comuns para inicializar uma função — partida a quente e partida a frio. Uma inicialização de aviso reutiliza recursos de um evento anterior, enquanto uma inicialização a frio implanta um novo contêiner. O tempo necessário para inicializar e executar uma função dependerá da quantidade de código, da linguagem de programação, do número de bibliotecas que o script usa, além de muitos outros fatores. Em termos de latência, uma inicialização a frio leva mais tempo para iniciar uma função.

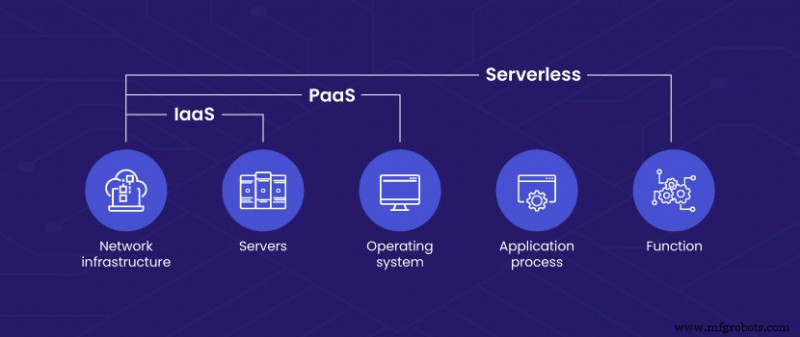
Como a computação sem servidor se compara a BaaS, PaaS e IaaS?
Como acontece com qualquer tendência de software, não há uma definição oficial que descreva o que é serverless e o que não é. É por isso que a computação sem servidor é frequentemente confundida com outros serviços em nuvem e modelos de implantação. O conceito de computação sem servidor gira em torno de duas áreas semelhantes:
Back-end como serviço — O BaaS permite que os desenvolvedores se concentrem em escrever interfaces de front-end enquanto transferem todas as operações de back-end para um provedor de serviços. Essas tarefas nos bastidores geralmente envolvem autenticação de usuário, armazenamento, gerenciamento de banco de dados e serviços de hospedagem prontos para uso. Além disso, os desenvolvedores não precisam gerenciar servidores que executam seu back-end, permitindo implantações de aplicativos mais rápidas.
Funções como serviço — Esse modelo de serviço em nuvem sem servidor elimina o gerenciamento de infraestrutura. O provedor de serviços tem a tarefa de implantar recursos de computação sob demanda para executar o código dos usuários. Isso acontece sempre que um evento ou solicitação é acionado. As funções sem servidor são executadas em contêineres sem estado, o que significa que os recursos de computação são implantados somente quando a função é invocada.
O principal ponto de confusão é entre Backend-as-a-Service e Platform-as-a-Service (PaaS). A primeira é uma técnica de computação sem servidor, enquanto a segunda é um modelo de implantação em nuvem. Embora compartilhem algumas características básicas, o PaaS não está alinhado com os requisitos do serverless.
Plataforma como serviço — Com PaaS, os usuários alugam as soluções de hardware e software necessárias para cargas de trabalho de desenvolvimento de um provedor de serviços por uma taxa de assinatura. Ele permite que os desenvolvedores gastem mais tempo codificando sem se preocupar com o gerenciamento de infraestrutura. Por outro lado, o BaaS oferece recursos adicionais, como autenticação de usuário pronta para uso, bancos de dados gerenciados, notificações por e-mail e similares. O BaaS também permite que os desenvolvedores se concentrem apenas na construção do front-end enquanto integram vários serviços de back-end sob demanda.
Infraestrutura como serviço — IaaS refere-se a uma solução de nuvem de autoatendimento em que o provedor hospeda a infraestrutura em nome do usuário. Todas as operações de provisionamento e gerenciamento de servidor, incluindo instalação de software, são tratadas pelo usuário. Alguns provedores de IaaS também oferecem soluções sem servidor, mas como produtos distintamente diferentes.
Casos de uso comuns de computação sem servidor
Como mencionado anteriormente, serverless não é para todos. Mas se suas necessidades estiverem alinhadas com alguns desses casos de uso, você poderá se beneficiar do serverless.
Construindo APIs
Sem servidores para gerenciar, a criação de APIs altamente escaláveis e responsivas é um dos casos de uso mais populares para sem servidor. O recurso de dimensionamento automático do serverless garante que as APIs estejam sempre disponíveis, mesmo sob tráfego intenso. Além disso, o usuário não é cobrado por recursos ociosos quando não há chamadas para a API.
Sites e aplicativos
A implantação de sites e aplicativos baseados na Web em uma plataforma sem servidor não requer nenhuma configuração de infraestrutura prévia. Isso reduz significativamente o tempo necessário para iniciar um aplicativo da Web totalmente funcional. O recurso de dimensionamento automático também desempenha um papel significativo aqui, pois o usuário não precisa se preocupar em provisionar mais servidores para dar suporte ao aumento da demanda. Como resultado, é muito mais fácil manter 100% de tempo de atividade.
Aplicativos em vários idiomas
Com serverless, um único aplicativo pode ser escrito em vários idiomas. O Serverless permite que os desenvolvedores dividam um aplicativo monolítico em partes menores e as executem como microsserviços. Esses microsserviços se comunicam entre si por meio de uma API. Cada segmento de um aplicativo pode ser escrito usando uma linguagem de programação diferente.
Oleodutos CI/CD
A automação é fundamental para executar pipelines de desenvolvimento, teste e integração bem-sucedidos. O Serverless permite que os desenvolvedores testem automaticamente o código e corrijam bugs mais rapidamente. Como o serverless é baseado em eventos, os usuários podem definir eventos para acionar testes automatizados sem qualquer intervenção manual.
Quais são as vantagens da computação sem servidor?
Em comparação com a computação em nuvem tradicional orientada a servidor, a computação sem servidor abstrai as operações de infraestrutura. Tudo funciona fora da caixa, o que, por sua vez, garante lançamentos de código mais rápidos e escalabilidade automatizada a um preço mais baixo.
Estes são os três benefícios mais comuns do serverless:
Escalonamento automático
O provedor sem servidor dimensiona os recursos de infraestrutura com base na demanda. As operações de dimensionamento são realizadas de forma dinâmica e automática, sem qualquer intervenção dos desenvolvedores.
Tempo de comercialização mais rápido
Sem a necessidade de provisionar clusters de servidores complexos, os desenvolvedores podem se concentrar mais em alcançar uma velocidade de lançamento mais alta. Isso acelera o tempo necessário para liberar o código para produção ou implementar alterações incrementais no código, resultando em entrega mais rápida de aplicativos aos clientes.
Custos otimizados
Como tudo é provisionado sob demanda, as organizações nunca precisam pagar por espaço de armazenamento não utilizado, tempo de computação ou rede. O consumo de serviços sem servidor geralmente é medido em milissegundos e cobrado de acordo.
Quais são as desvantagens da computação sem servidor?
Como acontece com qualquer solução de software, o serverless também traz algumas desvantagens. Mas dependendo do aplicativo que você está construindo, você pode não estar tão preocupado com algumas dessas desvantagens do serverless.
Latência
Ao executar uma função, os provedores sem servidor implantam automaticamente os recursos necessários em cada chamada. Dependendo do tamanho da carga de trabalho, os contêineres geralmente são provisionados em milissegundos, mas podem levar vários segundos. A latência pode ser reduzida por meio de “warn start” que reutiliza instâncias de uma execução anterior.
Duração da Execução
O tempo de execução de uma função sem servidor é limitado e é abortado após um determinado período. Isso geralmente ocorre em torno de cinco minutos após a invocação, mas varia entre os provedores. Os limites de execução são uma grande desvantagem para aplicativos que iniciam processos de longa duração. É possível mitigar esse problema segmentando o código em partes menores e executando-os como microsserviços.
Bloqueio do fornecedor
Os provedores geralmente usam tecnologias proprietárias para habilitar seus serviços sem servidor. Isso pode causar problemas para usuários que desejam migrar suas cargas de trabalho para outra plataforma. Ao mudar para outro provedor, as alterações no código e na arquitetura do aplicativo são inevitáveis.
Segurança
Os usuários têm pouco controle sobre a configuração da instância que executa seu código. Isso está oculto do usuário e cai no domínio do provedor de serviços. Como tal, as operações de segurança também caem nas mãos do provedor. O usuário fica impotente se ocorrer um ataque, contando apenas com o provedor para mitigar os danos e recuperar o sistema. Os aplicativos que têm vários pontos de entrada em um ambiente sem servidor são mais propensos a vulnerabilidades devido a uma maior superfície de ataque.
Qual é o futuro da computação sem servidor?
A computação sem servidor ainda é uma tecnologia relativamente nova. Seu futuro depende da capacidade dos provedores de serviços de resolver algumas das desvantagens listadas acima – o mais importante, as partidas a frio. Os provedores precisam reduzir o tempo necessário para executar uma função depois que ela estiver no estado ocioso por um tempo. Resolver esse problema diminuirá a latência e garantirá uma experiência de usuário perfeita.
Serverless atualmente depende de contêineres sem estado para execução de funções. O futuro do serverless está se movendo para permitir que aplicativos com estado aproveitem os benefícios do serverless. Isso permitirá que os desenvolvedores criem aplicativos com estado sem se preocupar com o gerenciamento de dados de back-end.
Em termos de DevOps, o serverless levará à expansão do NoOps. Essa tendência levará os provedores sem servidor a lidar com todas as operações de infraestrutura em nome do cliente. Nesse cenário, não há necessidade de as empresas terem equipes de operações internas.
Nos próximos anos, espera-se que o Kubernetes se torne a base do serverless. Com suporte para rede, escalonamento automático ágil e implantações em várias nuvens, a portabilidade do Kubernetes aprimora a computação sem servidor de várias maneiras. A execução de determinadas classes de aplicativos sem servidor é impraticável, pois os provedores de serviços às vezes limitam seu comportamento. Com o Kubernetes, os desenvolvedores poderão superar essas limitações e construir plataformas sem servidor com base em suas necessidades específicas.
Conclusão
Embora o nome sugira a ausência de servidores, a computação sem servidor ainda depende da nuvem ou de servidores físicos. É um modelo de computação que elimina as operações de infraestrutura, permitindo que os desenvolvedores se concentrem em escrever e implantar aplicativos. O modelo serverless gira em torno de duas áreas principais:Backend-as-a-Service e Functions-as-a-Service.
O primeiro fornece aos usuários uma arquitetura de back-end pronta para uso, enquanto o último permite a execução de aplicativos em contêineres sem estado. Esses contêineres são provisionados automaticamente com base em eventos ou gatilhos. Como tal, serverless não é uma solução mágica para todos os problemas de desenvolvimento atuais. Ele é voltado principalmente para aplicativos não monolíticos que empregam uma arquitetura baseada em microsserviços.
14 ferramentas de otimização e gerenciamento de custos na nuvem {Como escolher?}
Computação IoT Edge
Computação em Nuvem
- Computação sem servidor - a mais recente oferta “como serviço”
- Quais são os melhores cursos de computação em nuvem?
- O que é computação em nuvem e como a nuvem funciona?
- Qual é a relação entre big data e computação em nuvem?
- Os maiores obstáculos para uma adoção mais ampla sem servidor
- Computação em nuvem vs local
- O que é A2 Steel?
- O que é computação de borda e por que isso importa?
- O que é computação quântica?
- O que é o código HS para bomba hidráulica?