


Compiladores no mundo estranho da segurança funcional
Em todos os setores, o mundo da segurança funcional impõe novos requisitos aos desenvolvedores. O código funcionalmente seguro deve incluir código defensivo para defesa contra eventos inesperados que podem resultar de uma variedade de causas. Por exemplo, a corrupção da memória devido a erros de codificação ou eventos de raios cósmicos pode levar à execução de caminhos de código que são “impossíveis” de acordo com a lógica do código. Linguagens de alto nível, particularmente C e C ++, incluem um número surpreendente de recursos cujo comportamento não é prescrito pela especificação da linguagem à qual o código segue. Esse comportamento indefinido pode levar a resultados inesperados e potencialmente desastrosos que seriam inaceitáveis em um aplicativo funcionalmente seguro. Por esses motivos, os padrões exigem que a codificação defensiva seja aplicada, que o código seja testável, que seja possível agrupar a cobertura de código adequada e que o código do aplicativo seja rastreável até os requisitos para garantir que o sistema os implemente completa e exclusivamente.
O código também deve alcançar altos níveis de cobertura de código e, em alguns setores - especialmente automotivo - é comum que o projeto exija ferramentas de diagnóstico, calibração e desenvolvimento externas sofisticadas. O problema que surge é que práticas como codificação defensiva e acesso a dados externos não fazem parte de um mundo que os compiladores reconhecem. Por exemplo, nem C nem C ++ permitem qualquer tipo de corrupção de memória, portanto, a menos que o código projetado para protegê-lo esteja acessível quando não houver tal corrupção, ele pode ser simplesmente ignorado quando o código é otimizado. Consequentemente, o código defensivo deve ser sintaticamente e semanticamente alcançável se não for "otimizado".
Instâncias de comportamento indefinido também podem causar surpresas. É fácil sugerir que eles devem ser simplesmente evitados, mas geralmente é difícil identificá-los. Onde eles existem, não pode haver garantia de que o comportamento do código executável compilado corresponderá às intenções dos desenvolvedores. O acesso “porta dos fundos” aos dados usados pelas ferramentas de depuração representa mais uma situação que a linguagem não permite e, portanto, pode ter consequências inesperadas.
A otimização do compilador pode ter um grande impacto em todas essas áreas, porque nenhuma delas faz parte da responsabilidade dos fornecedores de compiladores. A otimização pode resultar na eliminação de um código defensivo aparentemente sólido onde está associado à "inviabilidade", ou seja, onde existe em caminhos que não podem ser testados e verificados por qualquer conjunto de valores de entrada possíveis. Ainda mais alarmante, o código defensivo mostrado para estar presente durante o teste de unidade pode muito bem ser eliminado quando o executável do sistema é construído. Só porque a cobertura do código defensivo foi alcançada durante o teste de unidade, não garante que ela esteja presente no sistema completo.
Nesta estranha terra de segurança funcional, o compilador pode estar fora de seu elemento. É por isso que a verificação de código de objeto (OCV) representa a prática recomendada para qualquer sistema para o qual existem consequências terríveis associadas à falha - e, de fato, para qualquer sistema onde apenas a prática recomendada é boa o suficiente.
Antes e depois da compilação
As práticas de verificação e validação defendidas por normas de segurança e codificação funcionais, como IEC 61508, ISO 26262, IEC 62304, MISRA C e C ++ colocam ênfase considerável em mostrar quanto do código-fonte do aplicativo é exercido durante o teste baseado em requisitos.
A experiência nos mostrou que, se o código tiver um desempenho correto, a probabilidade de falha no campo é consideravelmente menor. E ainda, porque o foco deste louvável esforço está no código-fonte de alto nível (não importa qual seja a linguagem), tal abordagem coloca muita fé na capacidade do compilador de criar código-objeto que reproduz precisamente o que os desenvolvedores pretendido. No mais crítico dos aplicativos, essa suposição implícita não pode ser justificada.
É inevitável que o controle e o fluxo de dados do código-objeto não sejam um espelho exato do código-fonte do qual foi derivado e, portanto, provar que todos os caminhos do código-fonte podem ser exercidos de forma confiável não prova a mesma coisa do código-objeto . Dado que existe uma relação 1:1 entre o código-objeto e o assembler, uma comparação entre o código-fonte e o assembly é reveladora. Considere o exemplo mostrado na Figura 1, em que o código assembler à direita foi gerado a partir do código-fonte à esquerda (usando um compilador TI com otimização desabilitada).

Figura 1:O código assembler à direita foi gerado a partir do código-fonte à esquerda, mostrando a comparação reveladora entre o código-fonte e o código assembly. (Fonte:LDRA)
Conforme ilustrado posteriormente, quando este código-fonte é compilado, o fluxograma para o código assembler resultante é bastante diferente daquele para a fonte porque as regras seguidas pelos compiladores C ou C ++ permitem que eles modifiquem o código da maneira que quiserem, desde que o binário se comporta "como se fosse o mesmo."
Na maioria das circunstâncias, esse princípio é totalmente aceitável - mas existem anomalias. As otimizações do compilador são basicamente transformações matemáticas aplicadas a uma representação interna do código. Essas transformações “dão errado” se as suposições não forem válidas - como costuma ser o caso em que a base de código inclui instâncias de comportamento indefinido, por exemplo.
Apenas DO-178C, usado na indústria aeroespacial, coloca qualquer foco no potencial de inconsistências perigosas entre a intenção do desenvolvedor e o comportamento executável - e mesmo assim, não é difícil encontrar defensores de soluções alternativas com potencial claro para deixar essas inconsistências sem detecção. No entanto, tais abordagens são desculpadas, o fato é que as diferenças entre o código-fonte e o código-objeto podem ter consequências devastadoras em qualquer aplicativo crítico.
Intenção do desenvolvedor versus comportamento do executável
Apesar das diferenças claras entre o fluxo de código de origem e de objeto, elas não são a principal preocupação. Compiladores são geralmente aplicativos altamente confiáveis e, embora possa haver bugs como em qualquer outro software, a implementação de um compilador geralmente atenderá aos seus requisitos de design. O problema é que esses requisitos de projeto nem sempre refletem as necessidades de um sistema funcionalmente seguro.
Em suma, pode-se presumir que um compilador é funcionalmente verdadeiro para os objetivos de seus criadores. Mas isso pode não ser inteiramente o que é desejado ou esperado, conforme ilustrado na Figura 2 abaixo com um exemplo resultante da compilação com o compilador CLANG.

A Figura 2 mostra uma compilação com o compilador CLANG (Fonte:LDRA)
É claro que a chamada defensiva para a função de "erro" não foi expressa no código assembler.
O objeto 'estado' é modificado apenas quando é inicializado e dentro dos casos 'S0' e 'S1', e assim o compilador pode raciocinar que os únicos valores dados a 'estado' são 'S0' e 'S1'. O compilador conclui que o 'padrão' não é necessário porque 'estado' nunca conterá quaisquer outros valores, assumindo que não há corrupção - e de fato, o compilador faz exatamente essa suposição.
O compilador também decidiu que, como os valores dos objetos reais (13 e 23) não são usados em um contexto numérico, ele simplesmente usará os valores de 0 e 1 para alternar entre os estados e, em seguida, usará um "ou" exclusivo para atualizar o valor do estado. O binário adere à obrigação “como se” e o código é rápido e compacto. Dentro de seus termos de referência, o compilador fez um bom trabalho.
Esse comportamento tem implicações para ferramentas de “calibração” que usam o arquivo de mapa de memória do vinculador para acessar objetos indiretamente e para acesso direto à memória por meio de um depurador. Novamente, tais considerações não fazem parte da competência do compilador e, portanto, não são consideradas durante a otimização e / ou geração de código.
Agora suponha que o código permaneça inalterado, mas seu contexto no código apresentado ao compilador muda ligeiramente, como na Figura 3.
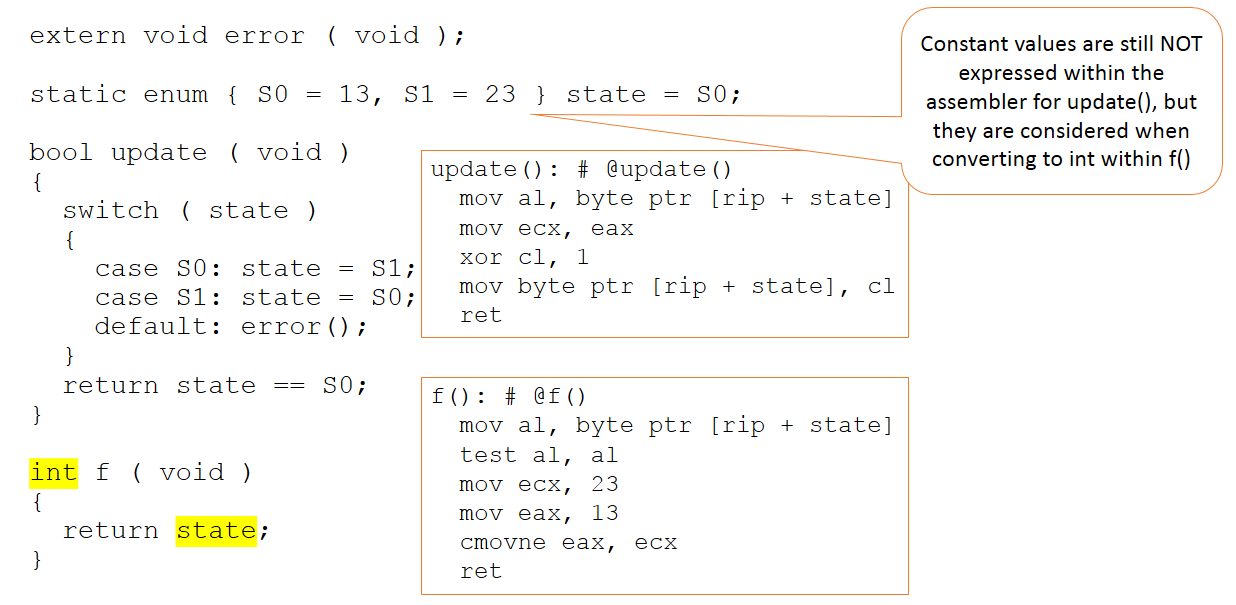
Figura 3:O código permanece o mesmo, mas seu contexto no código apresentado ao compilador muda ligeiramente. (Fonte:LDRA)
Agora existe uma função adicional, que retorna o valor da variável de estado como um inteiro. Desta vez, os valores absolutos 13 e 23 são importantes no código enviado ao compilador. Mesmo assim, esses valores não são manipulados dentro da função de atualização (que permanece inalterada) e são apenas aparentes dentro de nossa nova função “f”.
Em suma, o compilador continua (corretamente) a fazer julgamentos de valor sobre onde os valores de 13 e 23 devem ser usados - e eles não são de forma alguma aplicados em todas as situações em que podem ser.
Se a nova função for alterada para retornar um ponteiro para nossa variável de estado, o código do montador muda substancialmente. Como agora existe o potencial para acessos de alias por meio de um ponteiro, o compilador não pode mais deduzir o que está acontecendo com o objeto de estado. Conforme mostrado na Figura 4 abaixo, não é possível concluir que os valores de 13 e 23 não são importantes e, portanto, agora são expressos explicitamente no montador.
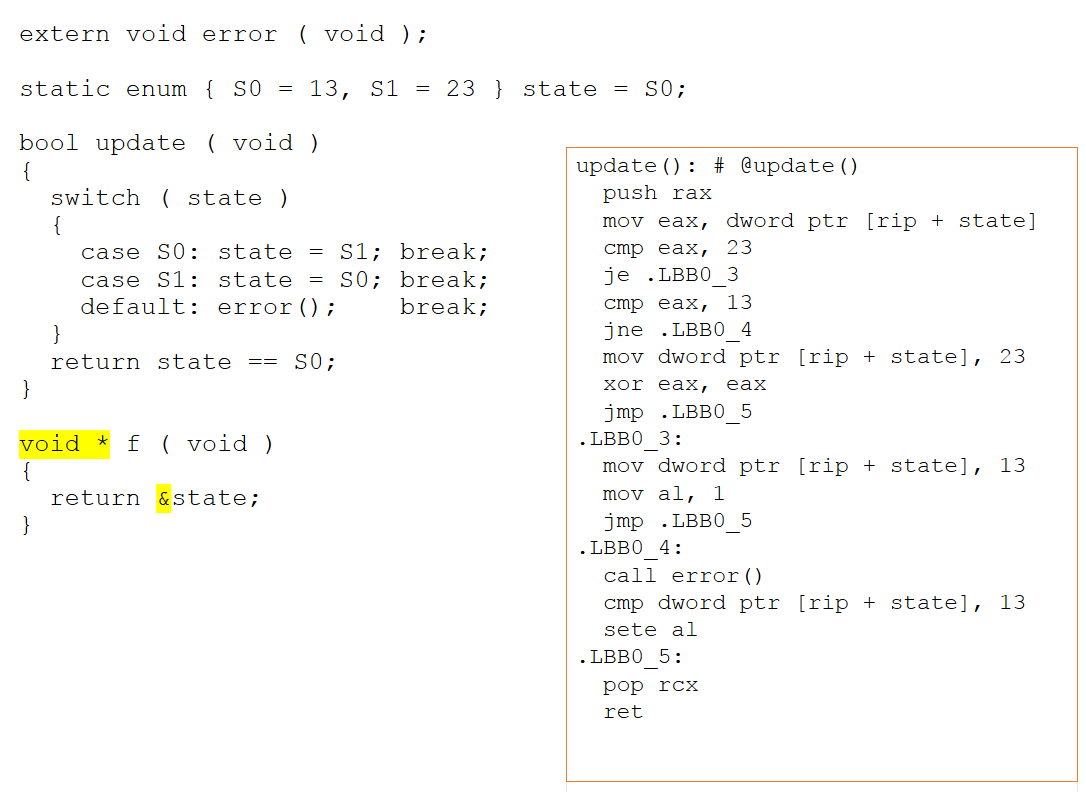
Figura 4:Se a nova função for alterada para retornar um ponteiro para nossa variável de estado, o código assembler muda substancialmente. Não é possível concluir que os valores de 13 e 23 não são importantes e, portanto, agora são expressos explicitamente no montador (Fonte:LDRA).
Implicações para o teste de unidade de código-fonte
Agora considere o exemplo no contexto de um chicote de teste de unidade imaginária. Como consequência da necessidade de um chicote para acessar o código em teste, o valor da variável de estado é manipulado e, como consequência, o padrão não é “otimizado”. Tal abordagem é inteiramente justificável em uma ferramenta de teste que não tem contexto relacionado ao restante do código-fonte e que é necessária para tornar tudo acessível, mas como efeito colateral pode disfarçar a omissão legítima de código defensivo pelo compilador.
O compilador reconhece que um valor arbitrário é escrito na variável de estado por meio de um ponteiro e, novamente, não pode concluir que os valores de 13 e 23 não são importantes. Conseqüentemente, eles agora são expressos explicitamente no montador. Nesta ocasião não se pode concluir que S0 e S1 representam os únicos valores possíveis para a variável de estado, o que significa que o caminho padrão pode ser viável. Conforme mostrado na Figura 5, a manipulação da variável de estado atinge seu objetivo e a chamada para a função de erro agora é aparente no montador.

Figura 5:A manipulação da variável de estado atinge seu objetivo e a chamada para a função de erro agora é aparente no montador. (Fonte:LDRA)
No entanto, essa manipulação não estará presente no código que será enviado com um produto e, portanto, a chamada para error () não está realmente lá no sistema completo.
A importância da verificação do código do objeto
Para ilustrar como a verificação do código do objeto pode ajudar a resolver esse enigma, considere novamente o primeiro trecho de código de exemplo, mostrado na Figura 6:

Figura 6:Ilustra como a verificação do código do objeto pode ajudar a resolver como a chamada ao erro não está no sistema completo. (Fonte:LDRA)
Este código C pode ser demonstrado para atingir 100% de cobertura do código-fonte por meio de uma única chamada, assim:
f_while4 (0,3);
O código pode ser reformatado para uma única operação por linha e representado em um fluxograma como uma coleção de nós de “bloco básico”, cada um dos quais é uma sequência de código em linha reta. A relação entre os blocos básicos é representada na Figura 7 usando arestas direcionadas entre os nós.
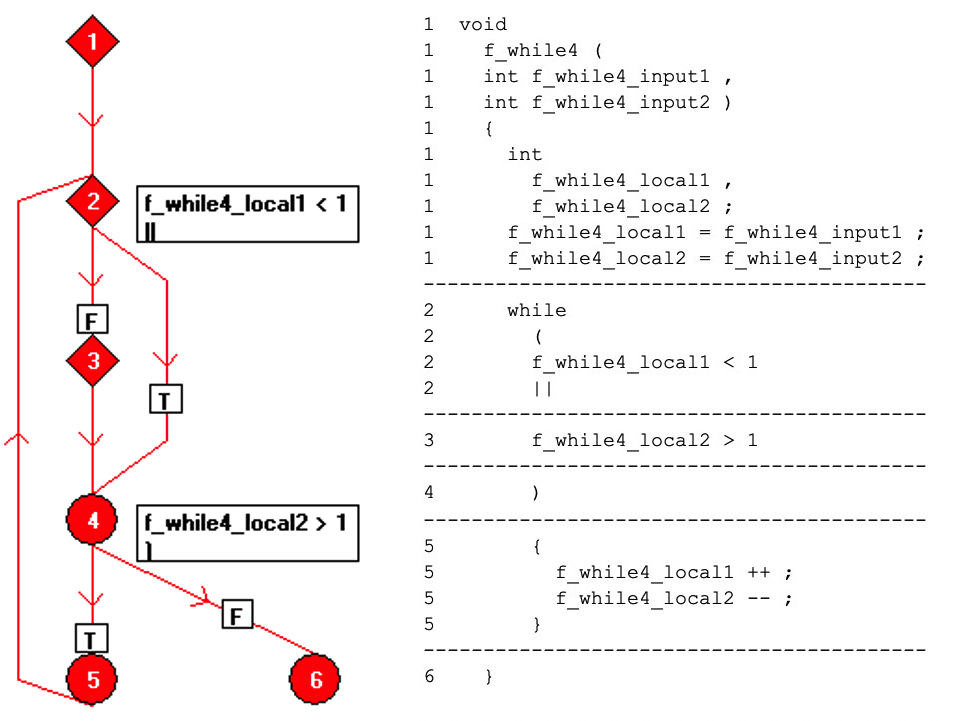
Figuras 7:Mostra a relação entre os blocos básicos usando arestas direcionadas entre os nós. (Fonte:LDRA)
Quando o código é compilado, o resultado é o mostrado abaixo (Figura 8). Os elementos azuis do fluxograma representam o código que não foi exercido pela chamada f_while4 (0,3).
Aproveitando a relação um-para-um entre o código-objeto e o código assembler, esse mecanismo expõe quais partes do código-objeto não são exercidas, solicitando que o testador elabore testes adicionais e obtenha cobertura completa do código assembler - e, portanto, obtenha a verificação do código-objeto.
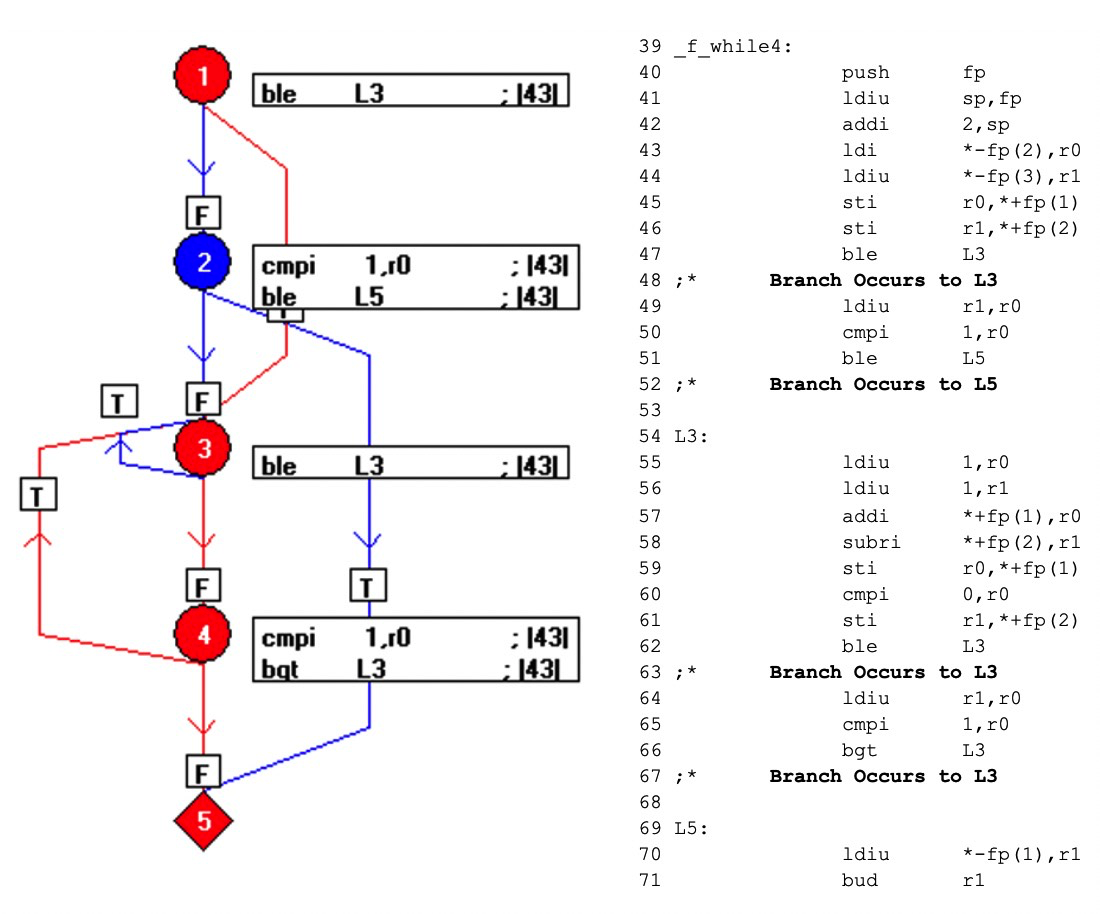
Figuras 8:Mostra o resultado quando o código é compilado. Os elementos azuis do fluxograma representam o código que não foi exercido pela chamada f_while4 (0,3). (Fonte:LDRA)
Claramente, a verificação do código-objeto não tem poder de impedir o compilador de seguir suas regras de design e, inadvertidamente, contornar as melhores intenções dos desenvolvedores. Mas pode, e o faz, chamar a atenção dos incautos para essas incompatibilidades.
Agora considere esse princípio no contexto do exemplo anterior de “chamada ao erro”. O código-fonte no sistema completo seria, é claro, idêntico ao comprovado no nível de teste de unidade e, portanto, uma comparação disso não revelaria nada. Mas a aplicação da verificação do código do objeto ao sistema completo seria inestimável para fornecer garantia de que o comportamento essencial é expresso como os desenvolvedores pretendiam.
Melhores práticas em qualquer mundo
Se o compilador lida com o código de maneira diferente no equipamento de teste em comparação com o teste de unidade, então a cobertura do teste de unidade de código-fonte vale a pena? A resposta é um sim qualificado." Muitos sistemas foram certificados com base nas evidências de tais artefatos e provaram ser seguros e confiáveis em serviço. Mas, para os sistemas mais críticos em todos os setores, se o processo de desenvolvimento deve resistir ao escrutínio mais detalhado e aderir às melhores práticas, a cobertura do teste de unidade de nível de origem deve ser complementada por OCV. É razoável presumir que ele atende aos critérios de projeto, mas esses critérios não incluem considerações de segurança funcional. A verificação do código do objeto atualmente representa a abordagem mais garantida para o mundo da segurança funcional, onde os comportamentos do compilador estão em conformidade com os padrões, mas mesmo assim pode ter um impacto negativo significativo.
Integrado
- A Importância da Segurança Elétrica
- O Mundo dos Corantes Têxteis
- Aplicação de corantes ácidos no mundo dos tecidos
- Uma olhada no mundo dos corantes
- Os muitos usos dos cestos de segurança
- O mundo de simulação em rápida evolução
- As capitais mundiais da manufatura
- 5 das dicas de segurança mais importantes para guindastes
- A importância dos materiais de fricção nos sistemas de segurança
- Segurança nas fábricas:uma fonte de melhoria contínua