


Pesquisadores mostram chip AI com treinamento de precisão reduzida
No ISSCC, a IBM Research apresentou um chip de teste que representa a manifestação de hardware de seus anos de trabalho em treinamento de IA de baixa precisão e algoritmos de inferência. O chip de 7 nm suporta treinamento de 16 e 8 bits, bem como inferência de 4 e 2 bits (treinamento de 32 ou 16 bits e inferência de 8 bits são o padrão da indústria hoje).
Reduzir a precisão pode reduzir a quantidade de computação e energia necessária para computação de IA, mas a IBM tem alguns outros truques arquitetônicos na manga que também ajudam na eficiência. O desafio é reduzir a precisão sem afetar negativamente o resultado do cálculo, algo em que a IBM vem trabalhando há vários anos no nível do algoritmo.
O AI Hardware Center da IBM foi criado em 2019 para apoiar a meta da empresa de aumentar o desempenho de computação de AI 2,5x por ano, com uma meta geral ambiciosa de melhoria de 1000x de eficiência de desempenho (FLOPS / W) até 2029. Metas ambiciosas de desempenho e energia são necessárias desde o tamanho dos modelos de IA e a quantidade de computação necessária para treiná-los estão crescendo rapidamente. Os modelos de Processamento de Linguagem Natural (PNL) em particular agora são gigantes de trilhões de parâmetros, e a pegada de carbono que acompanha o treinamento dessas feras não passou despercebida.
Este último chip de teste da IBM Research mostra o progresso que a IBM fez até agora. Para treinamento de 8 bits, o chip de 4 núcleos é capaz de 25,6 TFLOPS, enquanto o desempenho de inferência é 102,4 TOPS para computação inteira de 4 bits (esses números são para uma frequência de clock de 1,6 GHz e uma tensão de alimentação de 0,75 V). Reduzir a frequência do clock para 1 GHz e a tensão de alimentação para 0,55 V aumenta a eficiência energética para 3,5 TFLOPS / W (FP8) ou 16,5 TOPS / W (INT4).
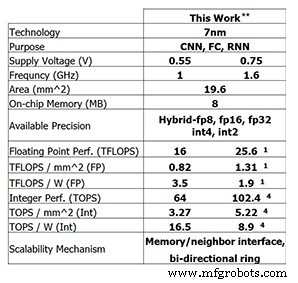
Desempenho do chip de teste da IBM Research (Imagem:IBM Research) ** Desempenho relatado em 0% de dispersão. (1) FP8. (4) INT4.
Treinamento de baixa precisão
Esse desempenho se baseia em anos de trabalho algorítmico em treinamento de baixa precisão e técnicas de inferência. O chip é o primeiro a suportar o formato de ponto flutuante híbrido de 8 bits especial da IBM (FP8 híbrido), que foi apresentado pela primeira vez no NeurIPS 2019. Este novo formato foi desenvolvido especialmente para permitir o treinamento de 8 bits, reduzindo pela metade a computação necessária para 16 bits treinamento, sem afetar negativamente os resultados (leia mais sobre formatos de número para processamento de IA aqui).
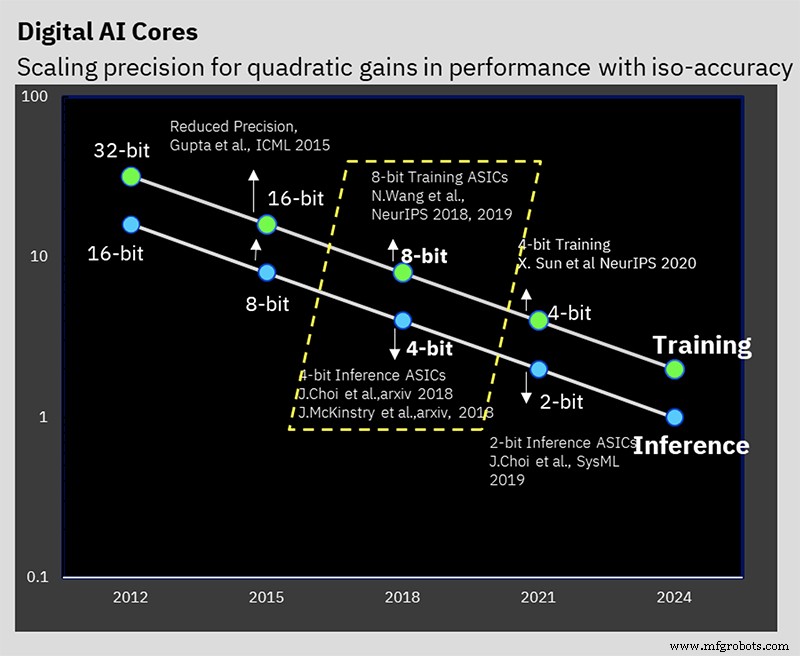
A IBM Research tem trabalhado para resolver o problema de manter a precisão enquanto reduz a precisão (Imagem:IBM)
“O que aprendemos em nossos vários estudos ao longo dos anos é que o treinamento de baixa precisão é muito desafiador, mas você pode fazer o treinamento de 8 bits se tiver os formatos de número corretos”, Kailash Gopalakrishnan, IBM Fellow e gerente sênior de arquiteturas de aceleradores e aprendizado de máquina na IBM Research disse ao EE Times . “A compreensão dos formatos numéricos corretos e colocá-los nos tensores corretos no aprendizado profundo foi uma parte crítica disso.”
Hybrid FP8 é na verdade uma combinação de dois formatos diferentes. Um formato é usado para pesos e ativações na passagem para frente do aprendizado profundo e outro é usado na passagem para trás. A inferência usa apenas o passe para frente, enquanto o treinamento requer as fases para frente e para trás.
“O que aprendemos é que você precisa de mais fidelidade, mais precisão, em termos de representação de pesos e ativações na passagem para frente do aprendizado profundo”, disse Gopalakrishnan. “Por outro lado [a fase de retrocesso], os gradientes têm uma alta faixa dinâmica e é aí que reconhecemos a necessidade de ter um expoente [maior] ... esta é a compensação entre como alguns tensores em aprendizagem profunda precisam mais precisão, representação de maior fidelidade, enquanto outros tensores precisam de uma faixa dinâmica mais ampla. Esta é a gênese do formato FP8 híbrido que apresentamos no final de 2019, que agora foi traduzido em hardware. ”
O trabalho da IBM determinou que a melhor maneira de dividir os 8 bits entre o expoente e a mantissa é 1-4-3 (um bit de sinal, um expoente de quatro bits e uma mantissa de três bits) para a fase direta, com uma alternativa 5- versão do expoente de bits para a fase de retrocesso, que dá uma faixa dinâmica de 2
32
. O hardware com capacidade para FP8 híbrido foi projetado para oferecer suporte a esses dois formatos.
Acumulação hierárquica
Uma inovação que os pesquisadores chamam de “acumulação hierárquica” permite que a acumulação diminua em precisão ao lado dos pesos e ativações. Os esquemas de treinamento típicos do FP16 se acumulam na aritmética de 32 bits para preservar a precisão, mas o treinamento de 8 bits da IBM pode se acumular no FP16. Manter a acumulação no FP32 teria limitado as vantagens obtidas com a mudança para o FP8 em primeiro lugar.
“O que acontece na aritmética de ponto flutuante é que se você adicionar um grande conjunto de números, digamos que seja um vetor de comprimento de 10.000 e você estiver adicionando tudo junto, a precisão da representação de ponto flutuante em si começa a limitar a precisão de seu soma ”, explicou Gopalakrishnan. “Concluímos que a melhor maneira de fazer isso não é fazer a adição de forma sequencial, mas tendemos a quebrar o longo acúmulo em grupos, o que chamamos de chunks. E então adicionamos os pedaços uns aos outros, e isso minimiza a probabilidade de ter esses tipos de erros. ”
Inferência de baixa precisão
A maioria das inferências de AI usa o formato inteiro de 8 bits (INT8) hoje. O trabalho da IBM mostrou que o número inteiro de 4 bits é o estado da arte em termos de quão baixa a precisão pode ir sem perder a precisão de previsão significativa. Após a quantização (o processo de conversão do modelo para números de precisão inferior), o treinamento com reconhecimento de quantização é executado. Este é efetivamente um esquema de retreinamento que mitiga quaisquer erros resultantes da quantização. Este novo treinamento pode minimizar a perda de precisão; A IBM pode quantizar para aritmética inteira de 4 bits “facilmente” com perda de apenas meio por cento na precisão, o que Gopalakrishnan disse ser “muito aceitável” para a maioria dos aplicativos.
Anel no chip
Além do foco na aritmética de baixa precisão, existem outras inovações de hardware que contribuem para a eficiência do chip.
Uma é a comunicação em anel no chip, uma rede no chip otimizada para aprendizado profundo que permite que cada um dos núcleos transmita dados para os outros. A comunicação multicast é crítica para o aprendizado profundo, uma vez que os núcleos precisam compartilhar pesos e comunicar os resultados a outros núcleos. Ele também permite que os dados carregados da memória fora do chip sejam transmitidos para vários núcleos. Isso reduz o número de vezes que a memória precisa ser lida e a quantidade geral de dados enviados, minimizando a largura de banda da memória necessária.
“Percebemos que poderíamos executar os núcleos mais rápido do que os anéis, porque os anéis envolvem muitos fios longos”, disse Ankur Agrawal, membro da equipe de pesquisa em aprendizado de máquina e arquiteturas de acelerador da IBM Research. “Nós dissociamos a frequência de operação do anel da frequência de operação dos núcleos ... o que nos permite otimizar de forma independente o desempenho do anel em relação aos núcleos.”
Gerenciamento de energia
Outra inovação da IBM foi introduzir um esquema de escalonamento de frequência para maximizar a eficiência.
“Cargas de trabalho de aprendizado profundo são um pouco especiais, porque mesmo durante a fase de compilação, você sabe quais fases de computação encontrará nesta carga de trabalho muito grande”, disse Agrawal. “Podemos fazer uma pré-configuração para descobrir como será o perfil de energia em diferentes partes da computação.”
O perfil de poder do aprendizado profundo normalmente tem grandes picos (para operações de computação pesada, como convolução) e baixas (talvez para funções de ativação).
O esquema da IBM define a voltagem e frequência de operação inicial do chip de forma bastante agressiva, de modo que mesmo para os modos de energia mais baixos, o chip está quase no limite de seu envelope de energia. Então, quando mais energia é necessária, a frequência de operação é reduzida.
“O resultado líquido é um chip que opera quase na potência de pico durante o cálculo, mesmo nas diferentes fases”, explicou Agrawal. “No geral, por não ter essas fases de baixo consumo de energia, você consegue fazer tudo mais rápido. Você traduziu qualquer queda no consumo de energia em ganhos de desempenho, mantendo seu consumo de energia quase no pico de consumo de energia em todas as fases de operação. ”
A escala de tensão não é usada porque é mais difícil de fazer na hora; o tempo necessário para estabilizar na nova tensão é muito longo para o cálculo de aprendizado profundo. Portanto, a IBM geralmente opta por executar o chip na tensão de alimentação mais baixa possível para esse nó de processo.
Chip de teste
O chip de teste da IBM tem quatro núcleos, em parte para permitir o teste de todos os diferentes recursos. Gopalakrishnan descreveu como o tamanho do núcleo é deliberadamente escolhido para ser um ótimo; uma arquitetura de milhares de núcleos minúsculos é complexa para se conectar, enquanto dividir o problema entre núcleos grandes também pode ser difícil. Este núcleo intermediário foi projetado para atender às necessidades da IBM e de seus parceiros no AI Hardware Center, encontrando um ponto ideal em termos de tamanho.
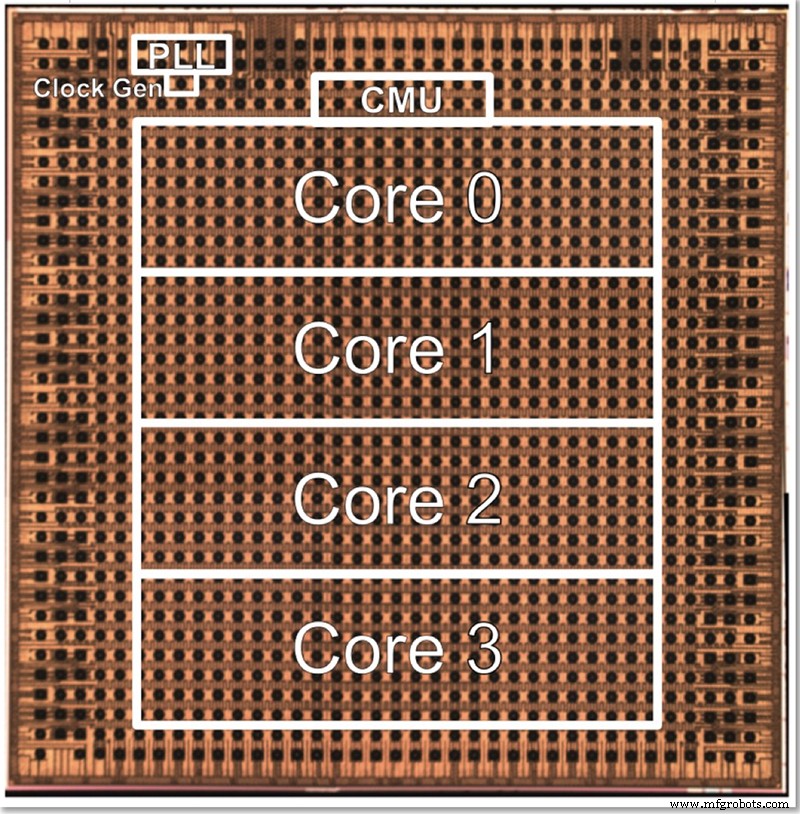
Uma foto para o chip de teste de 4 núcleos de baixa precisão da IBM (Imagem:IBM)
A arquitetura pode ser ampliada ou reduzida alterando o número de núcleos. Eventualmente, Gopalakrishnan imagina que 1-2 chips de núcleo seriam adequados para dispositivos de ponta, enquanto chips de 32-64 núcleos poderiam funcionar no data center. O fato de suportar vários formatos (FP16, FP8 híbrido, INT4 e INT2) também o torna versátil o suficiente para a maioria das aplicações, disse ele.
“Diferentes domínios [de aplicação] teriam diferentes requisitos de eficiência energética e precisão e assim por diante”, disse ele. “Nosso canivete suíço de precisão, cada um deles individualmente otimizado, nos permite direcionar esses núcleos em vários domínios, sem necessariamente abrir mão de qualquer eficiência energética nesse processo.”
Junto com o hardware, a IBM Research também desenvolveu uma pilha de ferramentas (“Deep Tools”) cujo compilador permite alta utilização do chip (60-90%).
EE Times A entrevista anterior com a IBM Research revelou que o treinamento de IA de baixa precisão e os chips de inferência baseados nesta arquitetura devem chegar ao mercado em cerca de dois anos.
>> Este artigo foi publicado originalmente em nosso site irmão, EE Times.
Conteúdos Relacionados:
- Os chips de IA mantêm a precisão com redução de modelo
- Modelos de treinamento de IA no limite
- A corrida para a IA no limite já começou
- Edge AI desafia a tecnologia de memória
- Grupo de engenharia busca levar IA de 1mW até o limite
- Aplicativo de redes neurais para tarefas de pequena escala
- A pesquisa AI IC explora arquiteturas alternativas
Para obter mais informações sobre o Embedded, assine o boletim informativo semanal da Embedded por e-mail.
Integrado
- Projetando com Bluetooth Mesh:Chip ou módulo?
- Os pesquisadores criam uma pequena etiqueta de identificação de autenticação
- Lidando com uma equipe de manutenção reduzida
- A aliança Rockwell com a faculdade de Minnesota expande o acesso ao treinamento de automação
- Pesquisadores mostram como explorar as falhas de segurança do Bluetooth Classic
- Como o IBM Watson está capacitando todos os outros negócios com IA
- Eleve seus esforços de marketing para executar com precisão de agência
- Eleve seus esforços de marketing para desempenhar com precisão de agência
- IBM:Garantindo proativamente confiabilidade e segurança com EAM
- Construindo sistemas hidráulicos superiores com usinagem de precisão