


A inicialização embala 1000 núcleos RISC-V no chip acelerador AI
Coincidindo com a conferência Hot Chips, a startup Esperanto saiu do modo furtivo esta semana com o chip comercial RISC-V de maior desempenho até hoje - um acelerador AI de mil núcleos projetado para data centers em hiperescala. Embora o chip possa ser executado em uma série de perfis de tensão e potência entre 10 e 60 W, seu "ponto ideal" é 20 W de potência por chip, uma configuração que permite que seis chips sejam montados em uma placa aceleradora Glacier Point, mantendo consumo total abaixo de 120 W. O desempenho total de seis chips é de aproximadamente 800 TOPS.
O ET-SoC-1 do Esperanto é anunciado como tendo o maior número de núcleos RISC-V já construídos em um único chip:1.093. A contagem inclui 1.088 núcleos RISC-V personalizados ET-Minion que funcionam como motores de aceleração AI com eficiência energética. Também estão incluídos quatro núcleos ET-Maxion RISC-V e um processador de serviço RISC-V. Todo o design é voltado para a eficiência energética.
Ahead of Hot Chips, EE Times conversou com o veterano da indústria Dave Ditzel, fundador e presidente executivo do Esperanto. (As credenciais de Ditzel incluem a coautoria com David Patterson do artigo seminal, "The Case for the Reduced Instruction Set Computer" publicado em 1980.)

Dave Ditzel (Fonte:Esperanto)
“Somos os primeiros a colocar mil núcleos RISC-V em um único chip”, disse Ditzel. “As pessoas falam sobre CPU de vários núcleos há anos, mas não vimos muito disso. A maior parte do material RISC-V que existe é para incorporado.
“Dissemos:‘ Vamos mostrar a eles que o RISC-V pode ser de última geração ... Mostraremos a eles o que designers de CPU realmente experientes podem fazer aqui ’.”
Requisitos do cliente
A equipe de designers de CPU de Ditzel conseguiu extrair detalhes de operadores de data center em hiperescala sobre seus requisitos.
“Eles não queriam um chip de treinamento, eles não tinham problemas com o treinamento”, disse Ditzel. O treinamento de IA muitas vezes é um problema offline, e a enorme capacidade da CPU x86 dos hiperescaladores nem sempre está no pico de carga. Portanto, essa capacidade pode ser usada para treinamento, quando disponível. “O verdadeiro problema deles é a inferência”, acrescentou Ditzel. “É isso que impulsiona a publicidade. Eles precisam de uma resposta em 10 milissegundos ou menos. ”
Conseqüentemente, acelerar o mecanismo de inferência de recomendações para publicidade online tornou-se o foco do chip do data center. Os requisitos dos hiperescalonadores para acelerar este tipo de modelo eram bastante explícitos.
“Nossos clientes queriam 100 megabytes de memória no chip - todas as coisas que eles queriam fazer com a inferência cabem em 100 megabytes”, disse ele. Os clientes também queriam uma interface externa para memória fora do chip. “O verdadeiro problema é quanto você pode segurar no cartão acelerador”, explicou Ditzel. “Pense no cartão como a unidade de computação, não como o chip. Uma vez que você pode obter memória na placa, você pode acessar as coisas muito mais rápido do que atravessar o barramento PCIe para o host. ”
clique para imagem em tamanho real

O Esperanto encaixou seis cartas M.2 duplas, cada uma com um chip, em uma placa aceleradora de Ponto Glaciar. (Fonte:esperanto)
O sistema de memória on-chip tem caches L1, L2 e L3 e um sistema de memória principal completo com arquivos de registro para um total de pouco mais de 100 MB. O sistema de memória no cartão pode suportar a maioria dos pesos e ativações no modelo em cerca de 100 GB.
Os modelos de recomendação são notoriamente difíceis de acelerar, um dos motivos pelos quais eles ainda funcionam em servidores de CPU existentes.
“Quando você está escolhendo entre 100 milhões de clientes e o que eles compraram recentemente, você tem que acessar esta ... memória no cartão, e você está fazendo todos os tipos de acessos de memória aleatórios, então os caches não trabalhos. Você realmente precisa mais de um computador clássico ”, disse Ditzel. Os “servidores x86 lidam com boa quantidade de memória e têm pré-busca, e CPUs de uso geral lidam muito bem com essa carga de trabalho. Tem sido difícil para qualquer acelerador entrar no negócio de recomendação por causa disso. ”
Também é necessário o suporte para INT8 junto com os tipos de dados FP16 e FP32. O requisito para matemática de ponto flutuante origina-se tanto da necessidade de manter a maior precisão de predição possível quanto da falta de inclinação para portar ou reescrever programas para matemática de menor precisão. Ditzel disse que os principais fabricantes de chips para servidores x86 só recentemente adicionaram extensões vetoriais de 8 bits às CPUs dos servidores.
“A maior parte da inferência que ocorre em [um data center em hiperescala] em seus milhões de servidores x86 ainda é flutuante de 32 bits”, disse ele.
O chip do Esperanto em um cartão M.2 duplo é projetado para caber em slots de acelerador dentro da infraestrutura de servidor de CPU x86 existente. Isso resulta em um limite de potência de 120 W, exigindo resfriamento a ar.
Ditzel disse que o design do Esperanto não compete diretamente com esforços internos como Google TPUs ou Amazon Web Services ’Inferentia. Os hiper-dimensionadores “estão tentando fazer com que toda a comunidade crie chips aceleradores para eles. Muitas dessas empresas acreditam em computação aberta e no [Open Compute Project]. ” Conseqüentemente, “eles compram servidores OCP e gostariam que materiais padronizados fossem incluídos lá. Se houver competição, eles adoram ... eles estão tentando encorajar a competição e mostrar às pessoas o que é possível. ”
Ainda assim, a startup insiste que os operadores de grandes centros de dados precisam de fornecedores externos para chips aceleradores. “Ainda é sempre uma decisão de fazer versus comprar.” Por exemplo, um cliente Esperanto não tinha acesso a chips desenvolvidos internamente e usados por outra divisão. “Se você vencer o que eles têm, o ingresso em qualquer uma dessas empresas é possível.”
Nova abordagem
O Esperanto adotou a abordagem oposta aos gigantes aceleradores de chips famintos por energia dos concorrentes, oferecendo um chip de menor consumo que pode ser usado em múltiplos. A abordagem atende aos requisitos de largura de banda de memória, uma vez que mais pinos podem ser usados para E / S de memória sem ter que recorrer ao caro HBM.
O hardware do Esperanto também é projetado como um computador de uso geral; apesar do foco em modelos de recomendação, o chip pode acelerar o processamento paralelo, de acordo com Ditzel. Uma placa aceleradora de seis chips inclui cerca de 6.000 núcleos paralelos, e cada núcleo pode executar dois threads, que podem ser "lançados em qualquer problema arbitrário".
Outro truque na manga do Esperanto é um design agressivo de eficiência energética. Os requisitos do cliente definem o orçamento de energia em 120 W no total, enquanto o espaço máximo estabelecido em uma placa Glacier Point era de seis chips, ou 20 W por chip. Em comparação, os aceleradores de inferência de IA operam em mais de dez vezes esse valor.
O Esperanto abordou a questão de vários ângulos. A frequência do clock foi reduzida a um nível ótimo de cerca de 1 GHz. A tensão de alimentação foi reduzida para cerca de 0,4 V, além do limite das SRAMs. A capacitância de comutação foi auxiliada pelo uso de núcleos RISC-V enxutos com o menor conjunto de instruções comercialmente viável para reduzir o número de transistores. Uma tecnologia de processo avançada, mas estável, TSMC 7nm, foi escolhida.
clique para imagem em tamanho real
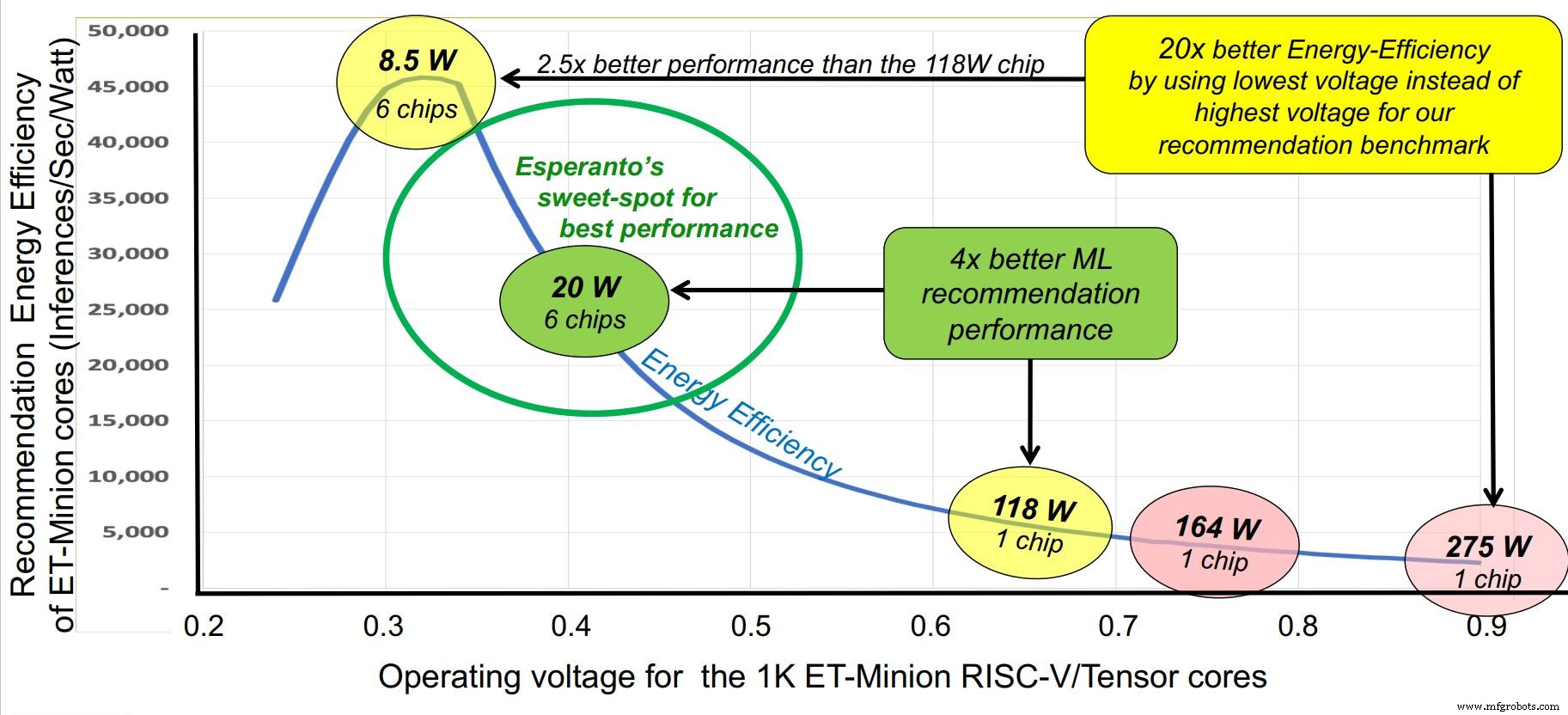
O Esperanto identificou um “ponto ideal” para operação em torno de 1 GHz. (Fonte:esperanto)
Projeto central
O chip do Esperanto inclui 1.088 núcleos ET-Minion, que processam a carga de trabalho de IA. Os núcleos são processadores RISC-V de 64 bits em ordem, com o vetor otimizado para IA do próprio Esperanto e unidade de tensor ocupando grande parte do espaço do chip. Os MACs de ponto flutuante dominam a configuração. Excepcionalmente, os MACs inteiros têm o dobro da largura de processamento do ponto flutuante (de acordo com os requisitos do cliente, observou Ditzel). Também há suporte para instruções transcendentais de vetor, como funções sigmóides comuns em modelos de aprendizado profundo. Como os núcleos funcionam em um único domínio de baixa tensão, mais transistores foram usados com SRAM no pequeno cache L1 para garantir um desempenho robusto.
clique para imagem em tamanho real
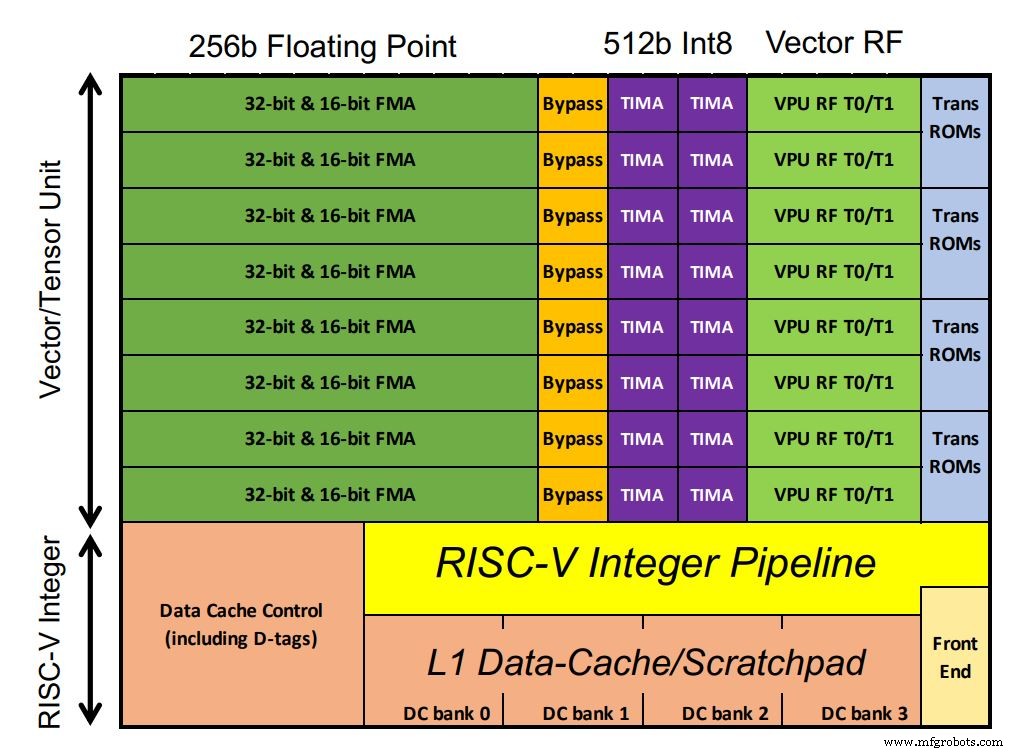
O chip do Esperanto contém 1.088 núcleos ET-Minion (clique na imagem para ampliar) (Fonte:Esperanto)
Cada núcleo é capaz de 128 GOPS por GHz. Uma instrução de tensor multi-ciclo personalizada realiza grandes multiplicações de matrizes com um controlador separado assumindo e executando até 512 ciclos usando a largura total de 512 bits. Isso permite que a instrução de tensor único execute mais de 64.000 operações aritméticas antes que o controlador busque a próxima instrução RISC-V. Isso reduz a largura de banda da instrução, pois a maior parte da carga de trabalho usa a instrução tensor. Conseqüentemente, apenas uma instrução por 512 ciclos de clock é necessária.
Oito núcleos de ET-Minion constituem uma “vizinhança” e as instruções modificadas tiram proveito de sua proximidade física. Outro recurso chamado “cargas cooperativas” permite que os núcleos transfiram dados diretamente uns dos outros sem uma busca de cache. Essa configuração economiza energia. Os oito núcleos também compartilham um grande cache L2 para eficiência energética.
Ampliando novamente, quatro bairros de 8 núcleos formam um “Condado de Minion”, com 34 condados em cada chip, totalizando 1.088 núcleos. (A computação com apenas 1.024 núcleos para melhorar o rendimento também é possível, disse Ditzel). Quatro núcleos ET-Maxion, cada um com desempenho quase comparável a um Arm A-72, destinam-se a futuras operações autônomas, em vez da configuração atual do acelerador.
A variação de tensão limite é mitigada fornecendo a cada Shire sua própria fonte de tensão para que as tensões individuais possam ser ajustadas com precisão.
Sistema de memória
Cada chip possui quatro interfaces DDR de 64 bits - na verdade, cada interface representa quatro canais de 16 bits - para um total de 96 canais de 16 bits. O design usa LPDDR4x desenvolvido como memória de baixo consumo de energia para smartphones. A energia por bit é aproximadamente equivalente ao HBM, mas manter o total em 1.536 bits na interface de memória para a placa aceleradora de seis chips resulta em maior largura de banda de memória total.
O Esperanto montou seus chips em cartões M.2 de soquete duplo; seis se encaixam em uma placa aceleradora OCP Glacier Point v2 (três na frente, três atrás). Isso oferece cerca de 800 TOPS com os chips funcionando a 1 GHz. Eles também podem ser montados em placas PCIe de baixo perfil (meia altura, meio comprimento) que aumentam o orçamento de energia de cada chip para cerca de 60 W. Os chips podem operar entre 300 MHz e 2 GHz, dependendo da aplicação.
Com base nos resultados da emulação de hardware, Ditzel afirmou que seis chips Esperanto em um cartão Glacier Point podem superar os concorrentes. A vantagem da inicialização é pronunciada para benchmarks de recomendação quando o design do sistema de memória e os valores de desempenho por watt são considerados, uma consequência do foco em um design de baixa tensão.
Versões futuras podem incluir uma versão reduzida do ET-SoC-1 para aplicativos de ponta. Ditzel disse que a versão atual deve ser lançada “nos próximos meses”.
>> Este artigo foi publicado originalmente em nosso site irmão, EE Vezes.
Conteúdos Relacionados:
- SoCs habilitados para IA lidam com vários streams de vídeo
- Xilinx visa o descarregamento do data center com hardware ‘combinável’
- Computação de conjunto de operação reduzida (ROSC) para cobertura funcional NNA
- A arquitetura híbrida acelera IA e cargas de trabalho de visão
- Aceleradores de hardware atendem a aplicativos de IA
Para obter mais informações sobre o Embedded, assine o boletim informativo semanal da Embedded por e-mail.
Integrado
- Revólver
- Uma perspectiva brilhante para a EDA na nuvem
- Cimeira RISC-V:destaques da agenda
- Arm permite instruções personalizadas para núcleos Cortex-M
- Projetando com Bluetooth Mesh:Chip ou módulo?
- A arquitetura do chip AI visa o processamento do gráfico
- Módulo Tiny Bluetooth 5.0 integra antena de chip
- Os pesquisadores criam uma pequena etiqueta de identificação de autenticação
- Processador de radar de imagem automotiva de 30 fps estreia
- Chip de radar de baixa potência usa redes neurais com pico