


Observação importante sobre aprendizado de máquina e seus quatro tipos principais para iniciantes
Não há dúvida de que Big Data é uma parte importante do desenvolvimento tecnológico futuro. No entanto, o aprendizado de máquina (ML) e a Inteligência Artificial (A.I) desempenham um papel importante nesse desenvolvimento. A relação entre esses três é brevemente explicada:Big data é para materiais, aprendizado de máquina é para método e inteligência artificial é para resultados.
O que é aprendizado de máquina?
Aprendizado de máquina (ML) é um dos tipos de inteligência artificial (IA) em que os algoritmos são escritos de tal maneira que o sistema recebe a capacidade de aprender, adaptar e melhorar automaticamente através da experiência sem ser explicitamente programado .
Os algoritmos de aprendizado de máquina constroem um modelo exemplar que se baseia no tipo de dados que se pretende aprender, esse tipo de dados é chamado de “dados de treinamento”.
Tipos de aprendizado de máquina?
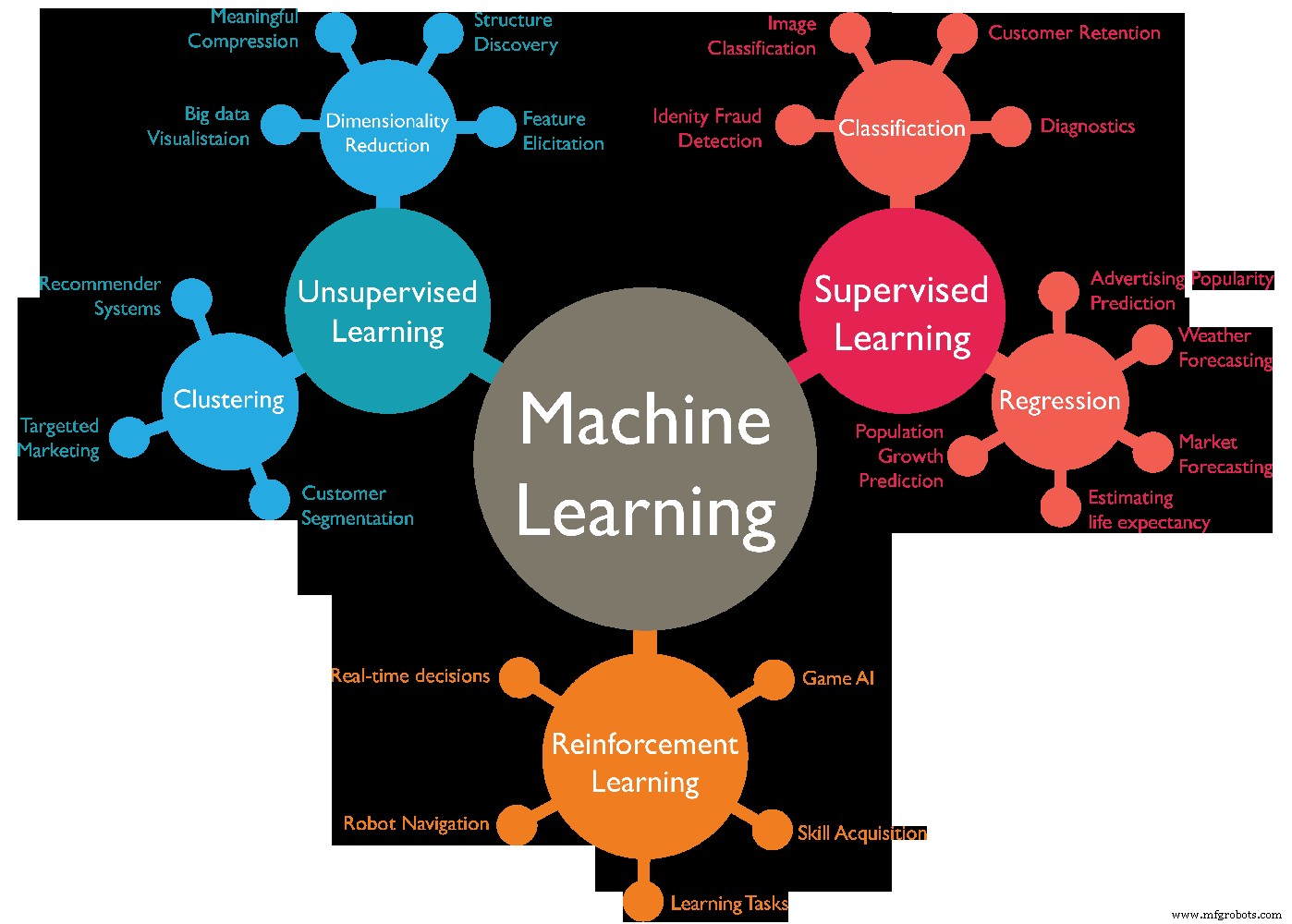
Existem vários tipos de algoritmos de aprendizado de máquina, geralmente podem ser divididos em 4 categorias, diferentes tipos de aprendizado de máquina são os seguintes:-
- Aprendizado supervisionado.
- Aprendizado não supervisionado.
- Aprendizado semissupervisionado.
- Aprendizagem por reforço.
Aprendizado supervisionado
Quando a máquina está sendo supervisionada enquanto está em seu estágio de “aprendizagem”, esse tipo de treinamento é chamado de aprendizado supervisionado. O que realmente queremos dizer quando dizemos que uma máquina está sendo supervisionada ?. O que realmente significa aplicar algoritmos de tal forma que permita que a máquina aprenda a usar seus dados antigos (dados fornecidos no passado) e use-os para fazer previsões de eventos futuros em torno do tipo de dados inseridos, ou seja, dados antigos.
A análise é iniciada e todos os materiais no conjunto de dados de treinamento e rotulados se correlacionam com a máquina de forma que ela possa fazer uma previsão dos valores de saída corretos. Isso significa que fornecemos à máquina muitas informações sobre um caso específico e, em seguida, fornece um resultado do caso. O resultado é chamado de dados rotulados, enquanto o restante das informações é usado como recursos de entrada. O sistema também pode fornecer alvos para novas entradas após treinamento suficiente. O algoritmo pode comparar sua saída com a saída pretendida e encontrar diferenças para alterar o modelo de acordo.
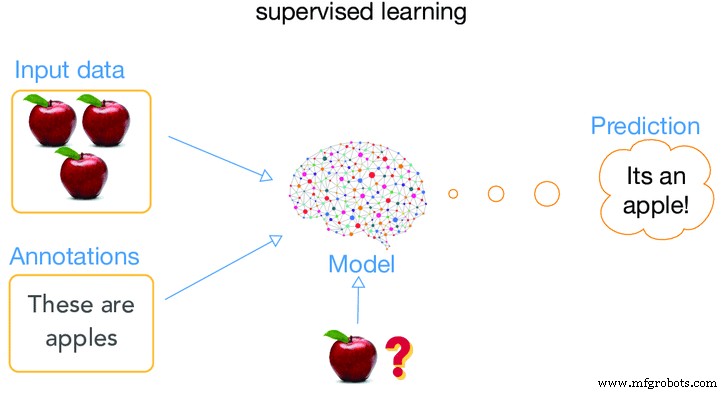
imagem Cortesia artificialintelligence.oodles.io/
Esse método é principalmente de classificação manual, que é o mais fácil de executar para um computador e o mais difícil para humanos. Um exemplo desse método é dizer à máquina as respostas padrão, e quando a máquina for testada, a máquina sempre responderá de acordo com a resposta padrão e, portanto, sua confiabilidade também será maior.
Aprendizado não supervisionado
Ao contrário do aprendizado supervisionado, os algoritmos de aprendizado não supervisionado são usados quando as informações usadas para treinar a máquina não são classificadas nem rotuladas, como o nome sugere, no aprendizado não supervisionado, nenhuma ajuda é oferecida do usuário ao computador para ajudar isso aprende.
O material fornecido não possui etiqueta, e a máquina então corresponde às características dos dados e classifica os materiais. Devido à falta de conjuntos de treinamento rotulados, a máquina identifica padrões nos dados que não são tão óbvios para os humanos.
image Cortesia data-flair.training/
Neste método, não há nenhuma classificação manual, que é a mais fácil para humanos, mas mais difícil para o computador e pode causar muito mais erros. O sistema geralmente não descobre a saída pretendida, mas pesquisa os dados fornecidos e pode traçar relações de conjuntos de dados para descrever estruturas ocultas de dados não rotulados. Portanto, reconhecer padrões no aprendizado não supervisionado de dados é extremamente útil e também nos ajuda a tomar decisões.
Aprendizado semi-supervisionado
A aprendizagem semi-supervisionada é diferente da aprendizagem supervisionada e da aprendizagem não supervisionada em que, ou não há rótulos presentes para todas as observações de dados ou rótulos estão presentes.
Em semi-supervisionado, os dados rotulados (supervisionados) e não rotulados (não supervisionados) são usados para treinamento. SSL é uma mistura dos dois tipos de aprendizagem em que uma pequena quantidade de dados é rotulada e grandes quantidades de dados não são rotuladas. A máquina é obrigada a encontrar recursos através de dados rotulados e, em seguida, usando o modelo básico, classifica outros dados de acordo. Os sistemas SSL podem melhorar consideravelmente não apenas a precisão do aprendizado, mas também fazer previsões mais precisas.
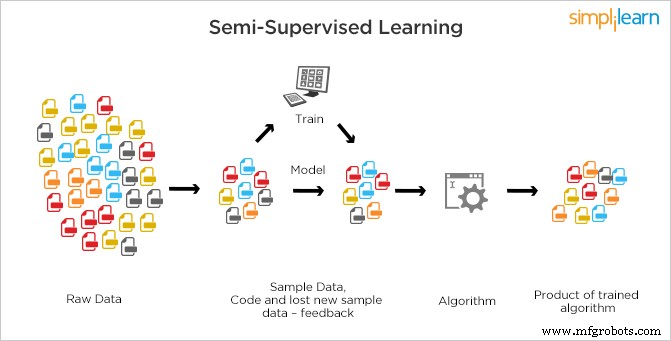
É o método mais comumente usado porque o custo para rotular é alto, pois são necessários especialistas humanos qualificados. Requer recursos relevantes para treiná-lo e aprender com ele, enquanto a aquisição de dados não rotulados geralmente não requer recursos adicionais. Devido à falta de rótulos na maioria das observações, mas a presença de algumas poucas, os algoritmos semi-supervisionados são os melhores candidatos para a construção de um modelo.
Esses métodos se beneficiam da ideia de que, embora os membros do grupo sejam desconhecidos porque os dados não rotulados são mais gerais, as informações sobre os parâmetros ainda são transportadas no rotulado e podem ser encontradas usando-o.
Aprendizagem por reforço
A aprendizagem por reforço é a mais próxima de como nós, humanos, aprendemos. Os algoritmos RML são um método de aprendizado no qual a máquina interage repetidamente com seu ambiente construindo novas ações e descobre erros ou recompensas. Ele usa um sistema baseado em recompensas positivas ou negativas.
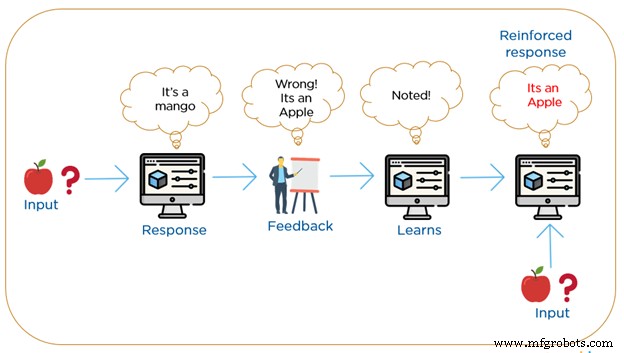
A busca por tentativa e erro com recompensa atrasada é a característica mais relevante do aprendizado por reforço. A máquina constrói um comportamento usando observações coletadas da interação com o ambiente e toma ações que maximizariam a recompensa ou minimizariam o risco. Este método permite que as máquinas determinem automaticamente o comportamento ideal dentro de um determinado contexto para aumentar seu desempenho. No aprendizado por reforço, não há materiais rotulados, mas, em vez disso, requer um feedback simples de qual etapa está correta e qual etapa está errada, isso é conhecido como sinal de reforço.

De acordo com o padrão de feedback, a máquina revisa gradualmente sua classificação até obter o resultado correto. A integração do aprendizado por reforço é necessária para alcançar um certo nível de precisão no aprendizado não supervisionado,
O RML é provavelmente o mais difícil de produzir e executar em um ambiente de negócios, mas está sendo comumente usado para carros autônomos.
Tecnologia industrial
- A Cadeia de Suprimentos e o Aprendizado de Máquina
- Quatro questões-chave para desbloquear o poder dos dados de campo ao vivo
- Elementary Robotics arrecada US$ 13 milhões para suas ofertas de aprendizado de máquina e visão computacional para a indústria
- Aprendizado de máquina em campo
- O papel da análise de dados para proprietários de ativos no setor de petróleo e gás
- Os muitos tipos de poliuretano e para que são usados
- AWS fortalece suas ofertas de IA e aprendizado de máquina
- O que é uma fresadora e para que ela é usada?
- Kepware vs. MachineMetrics:Qual é a melhor solução para coleta de dados de máquina?
- Os 9 aplicativos de aprendizado de máquina que você deve conhecer