


Computação em nuvem e borda para IoT:um breve histórico
A computação de ponta está ganhando cada vez mais popularidade no domínio IoT. Em 2018, foi uma das principais tendências de tecnologia, formando a base para a próxima geração de negócios digitais. Paralelamente, dada a grande quantidade de dados e a necessidade de otimizar recursos computacionais, também vemos uma tendência crescente de envio de dados para a nuvem.
Embora a computação em nuvem e a borda sejam frequentemente vistas como abordagens mutuamente exclusivas, projetos maiores de IoT frequentemente requerem uma combinação de ambas. Para entender a visão atual da IoT e os caracteres complementares da computação em nuvem e de ponta, queremos voltar no tempo e dar uma olhada em sua evolução nas últimas décadas.
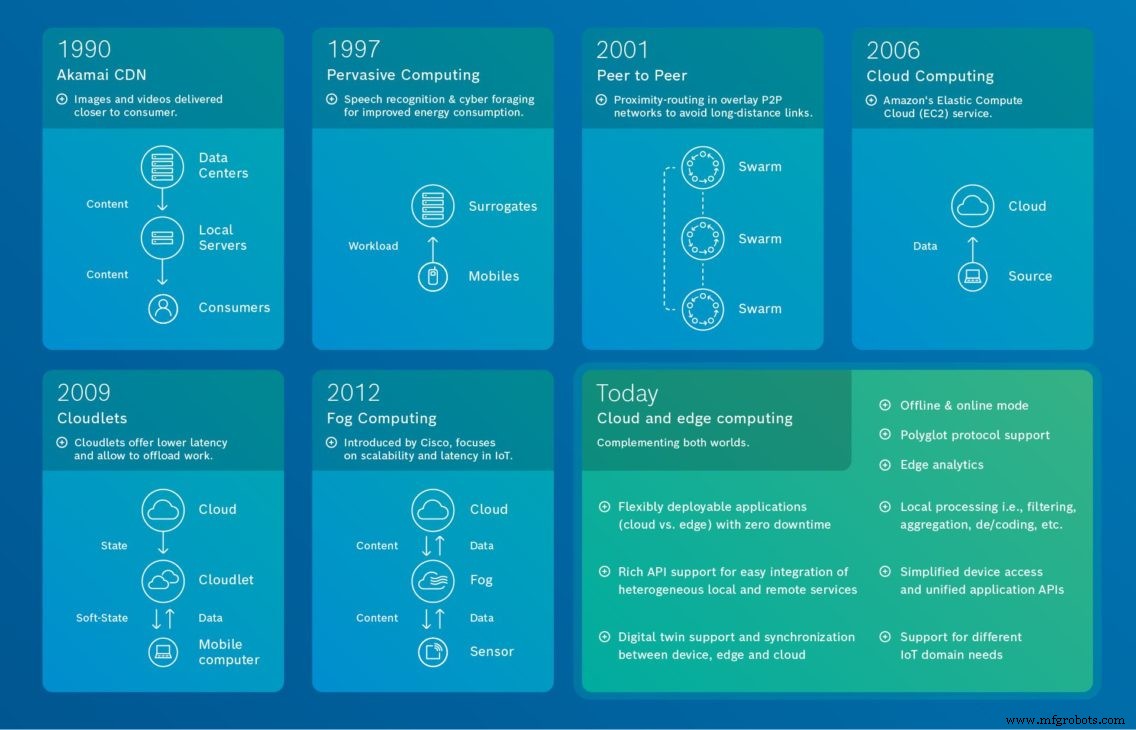 Fonte:Bosch.IO Uma retrospectiva da história da comunicação e dos sistemas distribuídos revela que a computação de ponta como tal não é nova. Nosso gráfico mostra a evolução da computação de ponta e termina com nossa visão de como a computação de ponta e a nuvem podem ser combinadas para fornecer o melhor valor.
Fonte:Bosch.IO Uma retrospectiva da história da comunicação e dos sistemas distribuídos revela que a computação de ponta como tal não é nova. Nosso gráfico mostra a evolução da computação de ponta e termina com nossa visão de como a computação de ponta e a nuvem podem ser combinadas para fornecer o melhor valor. O início da computação descentralizada
A origem da computação de ponta pode ser rastreada até a década de 1990 , quando a Akamai lançou sua rede de distribuição de conteúdo (CDN) . A ideia na época era introduzir nós em locais geograficamente mais próximos do usuário final para a entrega de conteúdo em cache, como imagens e vídeos.
Em 1997 , em seu trabalho “Adaptação ágil para mobilidade com base em aplicativos”, Nobel et al. demonstrou como diferentes tipos de aplicativos (navegadores da web, vídeo e reconhecimento de voz) executados em dispositivos móveis com recursos limitados podem descarregar certas tarefas em servidores poderosos (substitutos). O objetivo era aliviar a carga sobre os recursos de computação. E, como proposto em um trabalho posterior, para melhorar a vida útil da bateria - de dispositivos móveis. Hoje, por exemplo, os serviços de reconhecimento de voz do Google, Apple e Amazon funcionam de maneira semelhante. Em 2001 , com referência à computação difusa , Satyanarayanan et al. generalizou essa abordagem em seu artigo “Computação difusa:visão e desafios”.
Em 2001 aplicativos escaláveis e descentralizados distribuídos usados, conforme proposto, diferentes ponto a ponto (as chamadas tabelas de hash distribuídas) redes de sobreposição. Essas redes de sobreposição auto-organizáveis permitem roteamento eficiente e tolerante a falhas, localização de objetos e balanceamento de carga. Além disso, esses sistemas também permitem explorar a proximidade da rede de conexões físicas subjacentes na Internet, evitando assim links de longa distância entre pares. Isso não apenas diminui a carga geral da rede, mas também melhora a latência dos aplicativos.
Computação em nuvem
Computação em nuvem é um grande influenciador na história da computação de ponta e, portanto, merece menção especial. Ele atraiu atenção especial em 2006. O ano em que a Amazon promoveu pela primeira vez sua “Elastic Compute Cloud”. Isso abriu uma série de novas oportunidades em termos de computação, visualização e capacidade de armazenamento.
No entanto, a computação em nuvem como tal não foi a solução em todos os casos de uso. Com o advento dos carros autônomos e da IoT (industrial), por exemplo, houve uma ênfase crescente no processamento local de informações para permitir a tomada de decisão instantânea.
Cloudlets e computação com névoa
Em 2009 , Satyanarayanan et al. introduziu o termo cloudlet em seu artigo “The case for VM-based cloudlets in mobile computing.” Neste trabalho, o foco principal está na latência. Especificamente, o artigo propõe uma arquitetura de duas camadas. A primeira camada é conhecida como nuvem (alta latência) e a segunda como nuvem (menor latência). Os últimos são componentes de infraestrutura de Internet descentralizados e amplamente dispersos. Seus ciclos de computação e recursos de armazenamento podem ser aproveitados por computadores móveis próximos. Além disso, um cloudlet armazena apenas um estado suave, como cópias em cache de dados.
Em 2012 , A Cisco introduziu o termo computação em névoa para infraestruturas de nuvem dispersas. O objetivo era promover a escalabilidade da IoT, ou seja, lidar com um grande número de dispositivos IoT e grandes volumes de dados para aplicativos de baixa latência em tempo real.
Nuvem e computação de ponta para aplicativos de IoT em grande escala
Hoje , uma solução de IoT deve cobrir um escopo muito mais amplo de requisitos. Vemos que, na maioria dos casos, as organizações optam por uma combinação de nuvem e computação de ponta para soluções de IoT complexas. A computação em nuvem normalmente entra em ação quando as organizações precisam de capacidade de armazenamento e computação para executar determinados aplicativos e processos e para visualizar dados de telemetria de qualquer lugar. A computação de borda, por outro lado, é a escolha certa em casos com baixa latência, ações autônomas locais, tráfego de back-end reduzido e quando dados confidenciais estão envolvidos.
Você está interessado em aprender mais sobre como as empresas se beneficiam da nuvem e da computação de ponta ao implementar soluções de IoT? Leia nosso guia “Edge computing for IoT.”
Baixar white paper
Como aproveitar ao máximo seus dados
Gerenciamento de dados IoT:um guia sobre como implementar projetos
Tecnologia da Internet das Coisas
- Dicas e truques de computação em nuvem
- Padrões e ferramentas de programação para computação em nuvem
- Computação em nuvem para pequenas e médias empresas
- 10 coisas que devemos e não devemos fazer para uma carreira de computação em nuvem de sucesso
- Como a nuvem híbrida fornece a base para Edge Computing
- Por que a computação de borda para IoT?
- Aproveitamento de dados IoT da borda para a nuvem e vice-versa
- Economia da IoT - Lições para provedores de serviços e empresas
- A IoT e a computação em nuvem são o futuro dos dados?
- Benefícios do Edge Computing para cristalização de IA