


Como criar um buffer de anel FIFO em VHDL
Buffers circulares são construções populares para criar filas em linguagens de programação sequenciais, mas também podem ser implementados em hardware. Neste artigo, vamos criar um ring buffer em VHDL para implementar um FIFO na RAM do bloco.
Existem muitas decisões de projeto que você terá que tomar ao implementar um FIFO. Que tipo de interface você precisa? Você está limitado por recursos? Deve ser resiliente a leitura e sobregravação? A latência é aceitável? Essas são algumas das perguntas que surgem em minha mente quando solicitado a criar um FIFO.
Existem muitas implementações FIFO gratuitas online, bem como geradores FIFO como o Xilinx LogiCORE. Mas ainda assim, muitos engenheiros preferem implementar seus próprios FIFOs. Porque, embora todos executem as mesmas tarefas básicas de fila e desenfileiramento, eles podem ser muito diferentes ao levar em consideração os detalhes.
Como funciona um buffer de anel
Um buffer de anel é uma implementação FIFO que usa memória contígua para armazenar os dados em buffer com um mínimo de embaralhamento de dados. Novos elementos permanecem no mesmo local de memória desde o momento da escrita até que sejam lidos e removidos do FIFO.
Dois contadores são usados para acompanhar a localização e o número de elementos no FIFO. Esses contadores referem-se a um deslocamento desde o início do espaço de memória onde os dados são armazenados. Em VHDL, isso será um índice para uma célula de matriz. No restante deste artigo, nos referiremos a esses contadores como ponteiros .
Esses dois ponteiros são a cabeça e cauda ponteiros. A cabeça sempre aponta para o slot de memória que conterá os próximos dados gravados, enquanto a cauda se refere ao próximo elemento que será lido do FIFO. Existem outras variantes, mas esta é a que vamos usar.
Estado vazio
Se a cabeça e a cauda apontarem para o mesmo elemento, significa que o FIFO está vazio. A imagem acima mostra um exemplo de FIFO com oito slots. Tanto o ponteiro de cabeça quanto o de cauda estão apontando para o elemento 0, indicando que o FIFO está vazio. Este é o estado inicial do buffer de anel.
Observe que o FIFO ainda estaria vazio se ambos os ponteiros estivessem em outro índice, por exemplo, 3. Para cada gravação, o ponteiro de cabeça avança uma posição. O ponteiro de cauda é incrementado toda vez que o usuário do FIFO lê um elemento.
Quando um dos ponteiros estiver no índice mais alto, a próxima gravação ou leitura fará com que o ponteiro volte para o índice mais baixo. Esta é a beleza do buffer de anel, os dados não se movem, apenas os ponteiros.
Cabeça leva cauda

A imagem acima mostra o mesmo buffer de anel após cinco gravações. O ponteiro da cauda ainda está no slot número 0, mas o ponteiro da cabeça foi movido para o slot número 5. Os slots que contêm dados são coloridos em azul claro na ilustração. O ponteiro de cauda estará no elemento mais antigo, enquanto a cabeça aponta para o próximo slot livre.
Quando a cabeça tem um índice maior que a cauda, podemos calcular o número de elementos no buffer de anel subtraindo a cauda da cabeça. Na imagem acima, isso gera uma contagem de cinco elementos.
Cauda conduz a cabeça

Subtrair a cabeça da cauda só funciona se a cabeça liderar a cauda. Na imagem acima, a cara está no índice 2 enquanto a cauda está no índice 5. Assim, se realizarmos esse cálculo simples, obtemos 2 – 5 =-3, o que não faz sentido.
A solução é compensar a cabeça com o número total de slots no FIFO, 8 neste caso. O cálculo agora produz (2 + 8) – 5 =5, que é a resposta correta.
A cauda estará sempre perseguindo a cabeça, é assim que um buffer de anel funciona. Metade das vezes a cauda terá um índice maior que a cabeça. Os dados são armazenados entre os dois, conforme indicado pela cor azul clara na imagem acima.
Estado completo

Um buffer de anel completo terá a cauda apontando para o índice logo após a cabeça. Uma consequência desse esquema é que nunca podemos usar todos os slots para armazenar dados, deve haver pelo menos um slot livre. A imagem acima mostra uma situação em que o buffer de anel está cheio. O slot aberto, mas inutilizável, é de cor amarela.
Um sinal dedicado vazio/cheio também pode ser usado para indicar que o buffer de anel está cheio. Isso permitiria que todos os slots de memória armazenassem dados, mas requer lógica adicional na forma de registradores e tabelas de pesquisa (LUTs). Portanto, vamos usar o manter um aberto esquema para nossa implementação do FIFO de buffer de anel, pois isso apenas desperdiça RAM de bloco mais barata.
A implementação FIFO do buffer de anel
Como você define os sinais de interface para e de seu FIFO vai limitar o número de implementações possíveis de seu buffer de anel. Em nosso exemplo, usaremos uma variação da clássica habilitação de leitura/gravação e da interface vazia/cheia/válida.
Haverá um dados de gravação barramento no lado de entrada que transporta os dados a serem enviados para o FIFO. Haverá também uma ativação de gravação sinal, que quando ativado, fará com que o FIFO faça uma amostragem dos dados de entrada.
O lado de saída terá um leitura de dados e uma leitura válida sinal controlado pelo FIFO. Ele também terá uma ativação de leitura sinal controlado pelo usuário a jusante do FIFO.
O vazio e completo os sinais de controle fazem parte da interface FIFO clássica, nós também os usaremos. Eles são controlados pelo FIFO e seu objetivo é comunicar o estado do FIFO ao leitor e ao escritor.
Pressão de retorno
O problema de esperar até que o FIFO esteja vazio ou cheio antes de agir é que a lógica de interface não terá tempo de reagir. A lógica sequencial funciona em um ciclo de clock para ciclo de clock, as bordas ascendentes do clock separam efetivamente os eventos em seu projeto em etapas de tempo.

Uma solução é incluir
Em nossa implementação, os sinais anteriores serão nomeados
empty_next e full_next , simplesmente porque prefiro pós-fixar em vez de prefixar nomes. 
A entidade
A imagem abaixo mostra a entidade do nosso buffer de anel FIFO. Além dos sinais de entrada e saída na porta, possui duas constantes genéricas. O
RAM_WIDTH generic define o número de bits nas palavras de entrada e saída, o número de bits que cada slot de memória conterá. O
RAM_DEPTH generic define o número de slots que serão reservados para o buffer de anel. Como um slot é reservado para indicar que o buffer de anel está cheio, a capacidade do FIFO será RAM_DEPTH – 1. O RAM_DEPTH A constante deve corresponder à profundidade de RAM no FPGA de destino. RAM não utilizada dentro de uma primitiva de bloco de RAM será desperdiçada, não pode ser compartilhada com outra lógica no FPGA.
entity ring_buffer is
generic (
RAM_WIDTH : natural;
RAM_DEPTH : natural
);
port (
clk : in std_logic;
rst : in std_logic;
-- Write port
wr_en : in std_logic;
wr_data : in std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Read port
rd_en : in std_logic;
rd_valid : out std_logic;
rd_data : out std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Flags
empty : out std_logic;
empty_next : out std_logic;
full : out std_logic;
full_next : out std_logic;
-- The number of elements in the FIFO
fill_count : out integer range RAM_DEPTH - 1 downto 0
);
end ring_buffer;
Além do relógio e da reinicialização, a declaração da porta incluirá portas clássicas de dados/habilitação de leitura e gravação. Eles são usados pelos módulos upstream e downstream para enviar novos dados para o FIFO e para remover o elemento mais antigo dele.
O
rd_valid sinal é afirmado pelo FIFO quando o rd_data porta contém dados válidos. Este evento é atrasado por um ciclo de clock após um pulso no rd_en sinal. Falaremos mais sobre por que tem que ser assim no final deste artigo. Em seguida, vêm os sinalizadores vazios/completos definidos pelo FIFO. O
empty_next sinal será afirmado quando houver 1 ou 0 elementos restantes, enquanto empty só está ativo quando há 0 elementos no FIFO. Da mesma forma, o full_next sinal indicará que há espaço para mais 1 ou 0 elementos, enquanto full somente afirma quando o FIFO não pode acomodar outro elemento de dados. Finalmente, há um
fill_count resultado. Este é um número inteiro que refletirá o número de elementos atualmente armazenados no FIFO. Incluí este sinal de saída simplesmente porque o usaremos internamente no módulo. Quebrá-lo através da entidade é essencialmente gratuito, e o usuário pode optar por deixar este sinal desconectado ao instanciar este módulo. A região declarativa
Na região declarativa do arquivo VHDL, declararemos um tipo personalizado, um subtipo, uma série de sinais e um procedimento para uso interno no módulo de buffer de anel.
type ram_type is array (0 to RAM_DEPTH - 1) of
std_logic_vector(wr_data'range);
signal ram : ram_type;
subtype index_type is integer range ram_type'range;
signal head : index_type;
signal tail : index_type;
signal empty_i : std_logic;
signal full_i : std_logic;
signal fill_count_i : integer range RAM_DEPTH - 1 downto 0;
-- Increment and wrap
procedure incr(signal index : inout index_type) is
begin
if index = index_type'high then
index <= index_type'low;
else
index <= index + 1;
end if;
end procedure;
Primeiro, declaramos um novo tipo para modelar nossa RAM. O
ram_type type é uma matriz de vetores, dimensionada pelas entradas genéricas. O novo tipo é usado na próxima linha para declarar o ram sinal que manterá os dados no buffer de anel. No próximo bloco de código, declaramos
index_type , um subtipo de inteiro. Seu alcance será governado indiretamente pelo RAM_DEPTH genérico. Abaixo da declaração do subtipo, estamos usando o tipo de índice para declarar dois novos sinais, os ponteiros head e tail. Em seguida, segue um bloco de declarações de sinal que são cópias internas de sinais de entidade. Eles têm os mesmos nomes de base que os sinais de entidade, mas são pós-fixados com
_i para indicar que são para uso interno. Estamos usando essa abordagem porque é considerado um estilo ruim usar inout modo em sinais de entidade, embora isso tenha o mesmo efeito. Por fim, declaramos um procedimento chamado
incr que leva um index_type sinal como parâmetro. Este subprograma será usado para incrementar os ponteiros de cabeça e cauda, e envolvê-los de volta a 0 quando estiverem no valor mais alto. O head e tail são subtipos de integer, que normalmente não suportam o comportamento de encapsulamento. Usaremos o procedimento para contornar esse problema. Declarações simultâneas
No topo da arquitetura, declaramos nossas declarações simultâneas. Prefiro reunir essas atribuições de sinal de uma linha antes dos processos normais porque são facilmente ignoradas. Uma declaração simultânea é na verdade uma forma de processo, você pode ler mais sobre declarações simultâneas aqui:
Como criar uma declaração simultânea em VHDL
-- Copy internal signals to output empty <= empty_i; full <= full_i; fill_count <= fill_count_i; -- Set the flags empty_i <= '1' when fill_count_i = 0 else '0'; empty_next <= '1' when fill_count_i <= 1 else '0'; full_i <= '1' when fill_count_i >= RAM_DEPTH - 1 else '0'; full_next <= '1' when fill_count_i >= RAM_DEPTH - 2 else '0';
No primeiro bloco de atribuições simultâneas, estamos copiando as versões internas dos sinais de entidade para a saída. Essas linhas garantirão que os sinais da entidade sigam as versões internas exatamente ao mesmo tempo, mas com um atraso de ciclo delta na simulação.
O segundo e último bloco de instruções simultâneas é onde atribuímos os sinalizadores de saída, sinalizando o estado cheio/vazio do buffer de anel. Estamos baseando os cálculos no
RAM_DEPTH genérico e no fill_count sinal. A profundidade da RAM é uma constante que não mudará. Portanto, os sinalizadores serão alterados apenas como resultado de uma contagem de preenchimento atualizada. Atualizando o ponteiro de cabeça
A função básica do ponteiro de cabeça é incrementar sempre que o sinal de habilitação de gravação for ativado do lado de fora deste módulo. Estamos fazendo isso passando o
head sinal para o incr mencionado anteriormente procedimento.
PROC_HEAD : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
head <= 0;
else
if wr_en = '1' and full_i = '0' then
incr(head);
end if;
end if;
end if;
end process;
Nosso código contém um
and full_i = '0' adicional declaração para proteger contra sobregravações. Essa lógica pode ser omitida se você tiver certeza de que a fonte de dados nunca tentará gravar no FIFO enquanto estiver cheio. Sem essa proteção, uma substituição fará com que o buffer de anel fique vazio novamente. Se o ponteiro de cabeça for incrementado enquanto o buffer de anel estiver cheio, a cabeça estará apontando para o mesmo elemento que a cauda. Assim, o módulo irá “esquecer” os dados contidos, e o preenchimento FIFO parece estar vazio.
Ao avaliar o
full_i sinal antes de incrementar o ponteiro de cabeça, ele apenas esquecerá o valor sobrescrito. Acho essa solução mais bonita. Mas de qualquer forma, se as substituições acontecerem, é indicativo de um mau funcionamento fora deste módulo. Atualizando o ponteiro de cauda
O ponteiro de cauda é incrementado de maneira semelhante ao ponteiro de cabeça, mas o
read_en entrada é usada como o gatilho. Assim como com as substituições, estamos protegendo contra leituras excessivas incluindo and empty_i = '0' na expressão booleana.
PROC_TAIL : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
tail <= 0;
rd_valid <= '0';
else
rd_valid <= '0';
if rd_en = '1' and empty_i = '0' then
incr(tail);
rd_valid <= '1';
end if;
end if;
end if;
end process;
Além disso, estamos pulsando o
rd_valid sinal em cada leitura válida. Os dados lidos são sempre válidos no ciclo de clock após rd_en foi afirmado, se o FIFO não estava vazio. Com esse conhecimento, não há realmente nenhuma necessidade desse sinal, mas vamos incluí-lo por conveniência. O rd_valid O sinal será otimizado em síntese se for deixado desconectado quando o módulo for instanciado. Inferindo RAM do bloco
Para fazer a ferramenta de síntese inferir o bloco RAM, temos que declarar as portas de leitura e escrita em um processo síncrono sem reset. Vamos ler e escrever na RAM em cada ciclo de clock e deixar os sinais de controle lidarem com o uso desses dados.
PROC_RAM : process(clk)
begin
if rising_edge(clk) then
ram(head) <= wr_data;
rd_data <= ram(tail);
end if;
end process;
Esse processo não sabe quando a próxima gravação acontecerá, mas não precisa saber. Em vez disso, estamos apenas escrevendo continuamente. Quando o
head sinal é incrementado como resultado de uma gravação, começamos a gravar no próximo slot. Isso bloqueará efetivamente o valor que foi gravado. Atualizando a contagem de preenchimento
O
fill_count O sinal é usado para gerar os sinais cheios e vazios, que por sua vez são usados para evitar a sobregravação e a sobreleitura do FIFO. O contador de preenchimento é atualizado por um processo combinacional que é sensível ao ponteiro inicial e final, mas esses sinais são atualizados apenas na borda ascendente do relógio. Portanto, a contagem de preenchimento também mudará imediatamente após a transição do relógio.
PROC_COUNT : process(head, tail)
begin
if head < tail then
fill_count_i <= head - tail + RAM_DEPTH;
else
fill_count_i <= head - tail;
end if;
end process;
A contagem de preenchimento é calculada simplesmente subtraindo a cauda da cabeça. Se o índice da cauda for maior que o da cabeça, temos que adicionar o valor do
RAM_DEPTH constante para obter o número correto de elementos que estão atualmente no buffer de anel. O código VHDL completo para o buffer de anel FIFO
library ieee;
use ieee.std_logic_1164.all;
entity ring_buffer is
generic (
RAM_WIDTH : natural;
RAM_DEPTH : natural
);
port (
clk : in std_logic;
rst : in std_logic;
-- Write port
wr_en : in std_logic;
wr_data : in std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Read port
rd_en : in std_logic;
rd_valid : out std_logic;
rd_data : out std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Flags
empty : out std_logic;
empty_next : out std_logic;
full : out std_logic;
full_next : out std_logic;
-- The number of elements in the FIFO
fill_count : out integer range RAM_DEPTH - 1 downto 0
);
end ring_buffer;
architecture rtl of ring_buffer is
type ram_type is array (0 to RAM_DEPTH - 1) of
std_logic_vector(wr_data'range);
signal ram : ram_type;
subtype index_type is integer range ram_type'range;
signal head : index_type;
signal tail : index_type;
signal empty_i : std_logic;
signal full_i : std_logic;
signal fill_count_i : integer range RAM_DEPTH - 1 downto 0;
-- Increment and wrap
procedure incr(signal index : inout index_type) is
begin
if index = index_type'high then
index <= index_type'low;
else
index <= index + 1;
end if;
end procedure;
begin
-- Copy internal signals to output
empty <= empty_i;
full <= full_i;
fill_count <= fill_count_i;
-- Set the flags
empty_i <= '1' when fill_count_i = 0 else '0';
empty_next <= '1' when fill_count_i <= 1 else '0';
full_i <= '1' when fill_count_i >= RAM_DEPTH - 1 else '0';
full_next <= '1' when fill_count_i >= RAM_DEPTH - 2 else '0';
-- Update the head pointer in write
PROC_HEAD : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
head <= 0;
else
if wr_en = '1' and full_i = '0' then
incr(head);
end if;
end if;
end if;
end process;
-- Update the tail pointer on read and pulse valid
PROC_TAIL : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
tail <= 0;
rd_valid <= '0';
else
rd_valid <= '0';
if rd_en = '1' and empty_i = '0' then
incr(tail);
rd_valid <= '1';
end if;
end if;
end if;
end process;
-- Write to and read from the RAM
PROC_RAM : process(clk)
begin
if rising_edge(clk) then
ram(head) <= wr_data;
rd_data <= ram(tail);
end if;
end process;
-- Update the fill count
PROC_COUNT : process(head, tail)
begin
if head < tail then
fill_count_i <= head - tail + RAM_DEPTH;
else
fill_count_i <= head - tail;
end if;
end process;
end architecture;
O código acima mostra o código completo para o buffer de anel FIFO. Você pode preencher o formulário abaixo para que os arquivos do projeto ModelSim, bem como o testbench, sejam enviados a você instantaneamente.
A bancada de teste
O FIFO é instanciado em um testbench simples para demonstrar como ele funciona. Você pode baixar o código fonte do testbench junto com o projeto ModelSim usando o formulário abaixo.
As entradas genéricas foram definidas para os seguintes valores:
- RAM_WIDTH:16
- RAM_DEPTH:256
O testbench primeiro redefine o FIFO. Quando o reset é liberado, o testbench grava valores sequenciais (1-255) no FIFO até que esteja cheio. Finalmente, o FIFO é esvaziado antes da conclusão do teste.
Podemos ver a forma de onda para a execução completa do testbench na imagem abaixo. O
fill_count sinal é exibido como um valor analógico na forma de onda para melhor ilustrar o nível de preenchimento do FIFO. 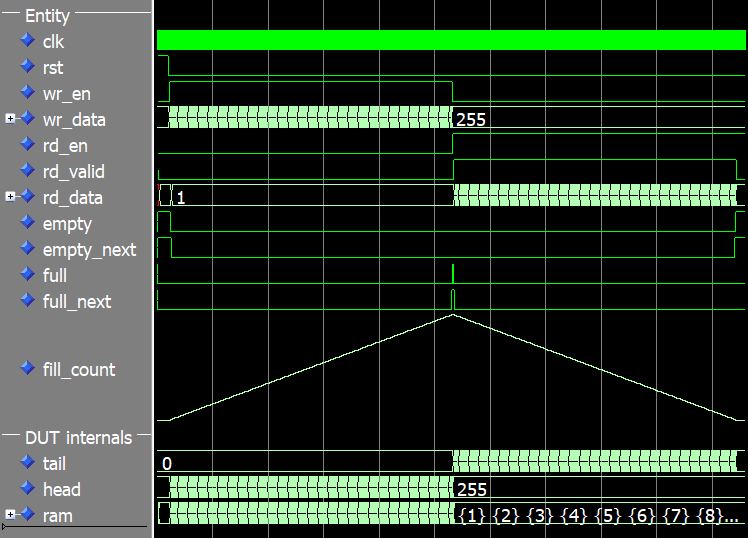
A cabeça, a cauda e a contagem de preenchimento são 0 no início da simulação. No ponto em que o
full sinal é afirmado, a cabeça tem o valor 255, assim como o fill_count sinal. A contagem de preenchimento só vai até 255, embora tenhamos uma profundidade de RAM de 256. Isso porque estamos usando o manter um aberto método para distinguir entre cheio e vazio, como discutimos anteriormente neste artigo. No ponto de virada em que paramos de escrever no FIFO e começamos a ler a partir dele, o valor da cabeça congela enquanto a contagem de cauda e preenchimento começam a diminuir. Finalmente, ao final da simulação quando o FIFO está vazio, tanto a cabeça quanto a cauda têm o valor 255 enquanto a contagem de preenchimento é 0.
Este banco de testes não deve ser considerado adequado para nada além de fins de demonstração. Ele não possui nenhum comportamento ou lógica de autoverificação para verificar se a saída do FIFO está correta.
Usaremos este módulo no artigo da próxima semana quando nos aprofundarmos no assunto da verificação aleatória restrita . Esta é uma estratégia de teste diferente dos testes direcionados mais comumente usados. Em suma, o testbench realizará interações aleatórias com o DUT (dispositivo em teste), e o comportamento do DUT deve ser verificado por um processo de testbench separado. Finalmente, quando ocorrerem vários eventos predefinidos, o teste estará concluído.
Clique aqui para ler a postagem do blog de acompanhamento:
Verificação aleatória restrita
Sintetizando no Vivado
Sintetizei o ring buffer no Xilinx Vivado porque é a ferramenta de implementação de FPGA mais popular. No entanto, ele deve funcionar em todas as arquiteturas FPGA que possuem RAM de bloco de porta dupla.
Temos que atribuir alguns valores às entradas genéricas para poder implementar o buffer de anel como um módulo autônomo. Isso é feito no Vivado usando as Configurações → Geral → Genéricos/Parâmetros menu, como mostra a imagem abaixo.
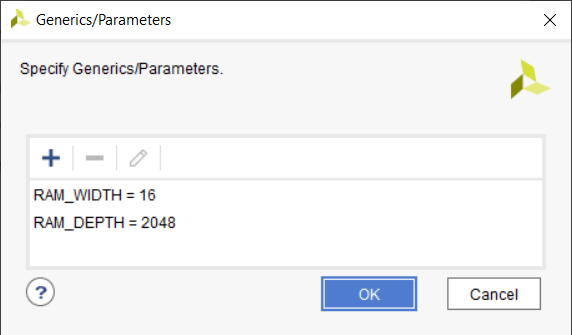
O valor para o
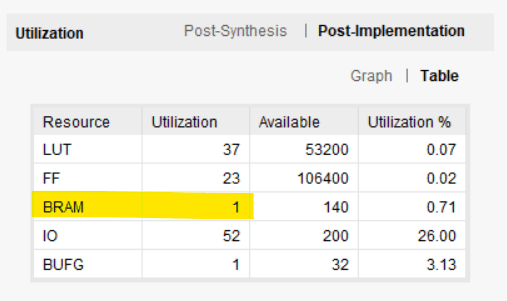
RAM_WIDTH é definido como 16, que é o mesmo que na simulação. Mas eu configurei o RAM_DEPTH para 2048 porque esta é a profundidade máxima da primitiva RAMB36E1 na arquitetura Xilinx Zynq que escolhi. Poderíamos ter selecionado um valor menor, mas ainda assim usaria o mesmo número de RAMs de bloco. Um valor mais alto resultaria em mais de um bloco de RAM sendo usado. A imagem abaixo mostra o uso de recursos pós-implementação, conforme relatado pelo Vivado. Nosso buffer de anel realmente consumiu um bloco de RAM e um punhado de LUTs e flip-flops.
Abandonando o sinal válido
Você pode estar se perguntando se o atraso de um ciclo de clock entre o
rd_en e o rd_valid sinal realmente é necessário. Afinal, os dados já estão presentes em rd_data quando afirmamos o rd_en sinal. Não podemos simplesmente usar esse valor e deixar o buffer de anel pular para o próximo elemento no próximo ciclo de clock enquanto lemos do FIFO? 
Estritamente falando, não precisamos do
valid sinal. Eu incluí este sinal apenas por conveniência. A parte crucial é que temos que esperar até o ciclo de clock depois que declaramos o rd_en sinal, caso contrário, a RAM não terá tempo de reagir. Block RAM em FPGAs são componentes totalmente síncronos, eles precisam de um clock edge tanto para ler quanto para gravar dados. O relógio de leitura e gravação não precisa vir da mesma fonte de relógio, mas deve haver bordas de relógio. Além disso, não pode haver lógica entre a saída da RAM e o próximo registro (flip-flops). Isso ocorre porque o registrador que é usado para cronometrar a saída RAM está dentro da primitiva RAM do bloco.

A imagem acima mostra no diagrama de tempo de como um valor se propaga do
wr_data entrada em nosso buffer de anel, através da RAM, e finalmente aparece no rd_data resultado. Como cada sinal é amostrado na borda ascendente do clock, são necessários três ciclos de clock desde que começamos a direcionar a porta de gravação antes que ela apareça na porta de leitura. E um ciclo de clock adicional passa antes que o módulo receptor possa utilizar esses dados. Reduzindo a latência
Existem formas de mitigar este problema, mas isso vem ao custo de recursos adicionais utilizados no FPGA. Vamos tentar um experimento para cortar um atraso do ciclo de clock da porta de leitura do nosso buffer de anel. No snippet de código abaixo, alteramos o
rd_data saída de um processo síncrono para um processo combinacional que é sensível ao ram e tail sinal.
PROC_READ : process(ram, tail)
begin
rd_data <= ram(tail);
end process;
Infelizmente, este código não pode ser mapeado para bloquear RAM porque pode haver lógica combinacional entre a saída da RAM e o primeiro registro downstream no
rd_data sinal. A imagem abaixo mostra o uso do recurso conforme relatado pelo Vivado. O bloco RAM foi substituído por LUTRAM; uma forma de RAM distribuída implementada em LUTs. O uso de LUT disparou de 37 LUTs para 947. Tabelas de pesquisa e flip-flops são mais caros do que RAM de bloco, essa é a razão pela qual temos RAM de bloco em primeiro lugar.
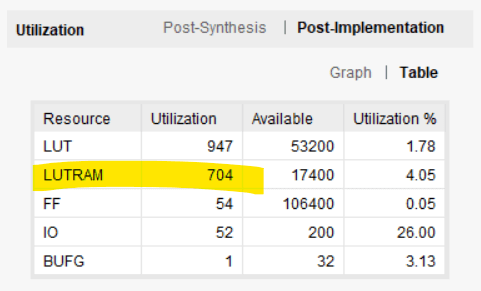
Há muitas maneiras de implementar um buffer de anel FIFO na RAM do bloco. Você pode economizar o ciclo de clock extra usando outro design, mas isso custará na forma de lógica de suporte extra. Para a maioria dos aplicativos, o buffer de anel apresentado neste artigo será suficiente.
Atualização:
Como criar um buffer de anel FIFO na RAM do bloco usando o handshake AXI pronto/válido
Na próxima postagem do blog, criaremos um testbench melhor para o módulo de buffer de anel usando verificação aleatória restrita .
Clique aqui para ler a postagem do blog de acompanhamento:
Verificação aleatória restrita
VHDL
- Como criar uma lista de strings em VHDL
- Como criar um testbench orientado por Tcl para um módulo de bloqueio de código VHDL
- Como parar a simulação em um testbench VHDL
- Como criar um controlador PWM em VHDL
- Como gerar números aleatórios em VHDL
- Como criar um testbench de autoverificação
- Como criar uma lista vinculada em VHDL
- Como usar um procedimento em um processo em VHDL
- Como usar uma função impura em VHDL
- Como usar uma função em VHDL