


Como as extensas cadeias de processamento de sinal fazem os assistentes de voz 'simplesmente trabalharem'
Alto-falantes inteligentes e dispositivos controlados por voz estão se tornando cada vez mais populares, com assistentes de voz como Alexa da Amazon e o assistente do Google, cada vez melhores para entender nossas solicitações.
Um dos principais atrativos desse tipo de interface é que "simplesmente funciona" - não há interface de usuário para aprender e podemos falar cada vez mais com um gadget em uma linguagem natural como se fosse uma pessoa e obter uma resposta útil. Mas, para atingir essa capacidade, há uma grande quantidade de processamento sofisticado em andamento.
Neste artigo, veremos a arquitetura de soluções controladas por voz e discutiremos o que está acontecendo nos bastidores e o hardware e software necessários.
Fluxo e arquitetura do sinal
Embora existam muitos tipos de dispositivos controlados por voz, os princípios básicos e o fluxo do sinal são semelhantes. Vamos considerar um alto-falante inteligente, como o Amazon’s Echo, e olhar para os principais subsistemas e módulos de processamento de sinal envolvidos.
A Figura 1 mostra a cadeia de sinal geral em um alto-falante inteligente.
clique para ampliar a imagem
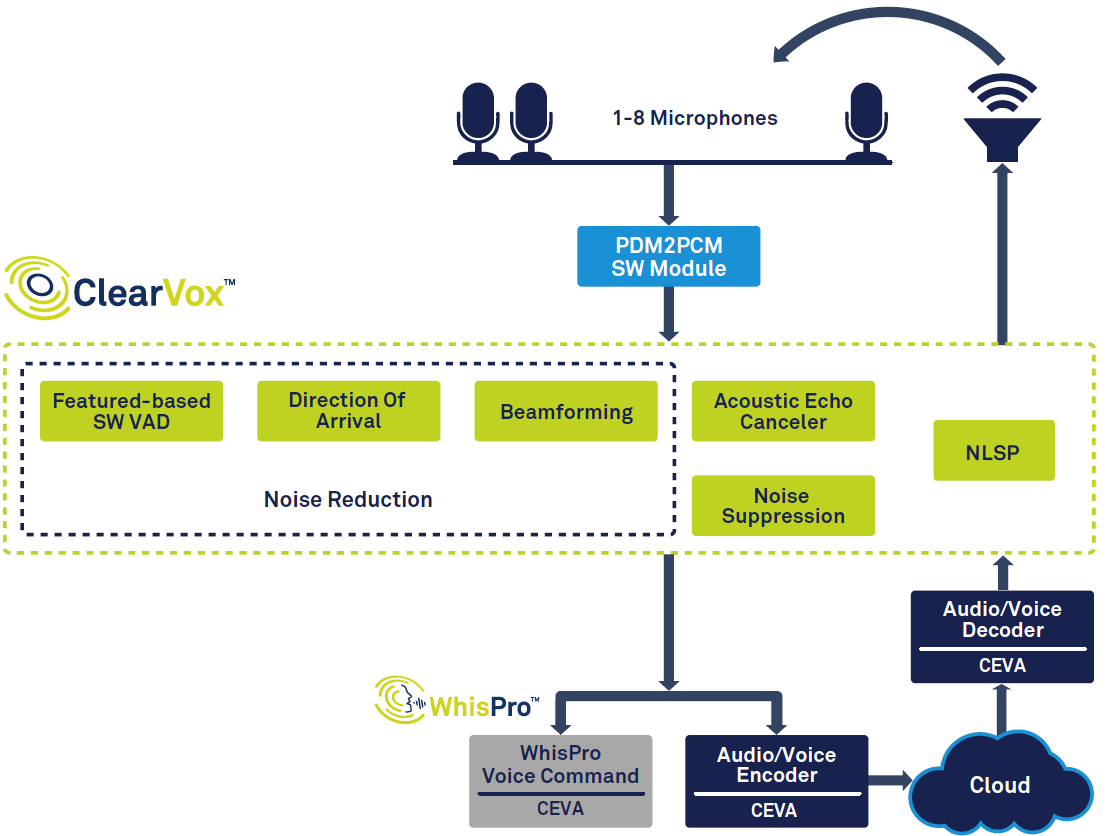
Figura 1:Cadeia de sinal para assistente de voz, com base no ClearVox e WhisPro da CEVA. (Fonte:CEVA)
Começando à esquerda do diagrama, você pode ver que, uma vez que uma voz é detectada usando a detecção de atividade de voz (VAD), ela é digitalizada e passa por vários estágios de processamento de sinal para melhorar a clareza da voz do locutor principal desejado direção de chegada. Os dados de voz processados digitalizados são então passados para o processamento de voz de back-end, que pode ocorrer parcialmente na borda (no dispositivo) e parcialmente na nuvem. Finalmente, uma resposta, se necessária, é criada e emitida pelo alto-falante, o que requer decodificação e conversão digital para analógico.
Para outras aplicações, pode haver algumas diferenças e prioridades variáveis - por exemplo, uma interface de voz no veículo precisaria ser otimizada para lidar com o ruído de fundo típico em carros. Há também uma tendência geral para baixo consumo de energia e custos reduzidos, impulsionada pela demanda por dispositivos menores, como aparelhos auditivos intra-auriculares e eletrodomésticos de baixo custo.
Processamento de sinal de front-end
Depois que uma voz é detectada e digitalizada, várias tarefas de processamento de sinal são necessárias. Além do ruído externo, também precisamos levar em consideração os sons gerados pelo dispositivo de escuta, por exemplo, um alto-falante inteligente emitindo música ou uma conversa com uma pessoa falando do outro lado da linha. Para suprimir esses sons, o dispositivo usa cancelamento de eco acústico (AEC), para que o usuário possa interferir e interromper um alto-falante inteligente, mesmo quando ele já está tocando música ou falando. Uma vez que esses ecos são removidos, algoritmos de supressão de ruído são usados para limpar o ruído externo.
Embora existam muitas aplicações diferentes, podemos generalizá-los em dois grupos para dispositivos controlados por voz:captação de voz de campo próximo e campo distante. Dispositivos de campo próximo, como fones de ouvido, auriculares e vestíveis, são mantidos ou usados perto da boca do usuário, enquanto dispositivos de campo distante, como alto-falantes inteligentes e TVs são projetados para ouvir a voz do usuário do outro lado da sala.
Dispositivos de campo próximo normalmente usam um ou dois microfones, mas dispositivos de campo distante geralmente usam algo entre três e oito. A razão para isso é que o dispositivo de campo distante enfrenta mais desafios do que o campo próximo:conforme o usuário se afasta, sua voz chegando aos microfones torna-se progressivamente mais baixa, enquanto o ruído de fundo permanece no mesmo nível. Ao mesmo tempo, o dispositivo também deve separar o sinal de voz direto dos reflexos nas paredes e outras superfícies, também conhecido como reverberação.
Para lidar com esses problemas, os dispositivos de campo distante empregam uma técnica chamada beamforming. Ele usa vários microfones e calcula a direção da fonte de som com base nas diferenças de tempo entre os sinais de som que chegam em cada microfone. Isso permite que o dispositivo ignore reflexos e outros sons e apenas escute o usuário - bem como rastreie seus movimentos e amplie a voz correta onde houver várias pessoas falando.
Para alto-falantes inteligentes, outra tarefa importante é reconhecer a palavra ‘gatilho’, como ‘Alexa’. Como o locutor está sempre ouvindo, esse reconhecimento de gatilho levanta problemas de privacidade - se o áudio do usuário está sempre sendo enviado para a nuvem, mesmo quando ele não diz a palavra de gatilho, ele se sente confortável com a Amazon ou o Google ouvindo todas as suas conversas? Em vez disso, pode ser preferível lidar com o reconhecimento do acionador, bem como com muitos comandos populares, como “aumentar o volume” localmente no próprio alto-falante inteligente, com o áudio apenas sendo enviado para a nuvem depois que o usuário iniciar um comando mais complexo.
Finalmente, a amostra de voz limpa deve ser codificada antes de ser enviada ao back-end da nuvem para processamento posterior.
Soluções especializadas
É claro pela descrição acima que o processamento de voz front-end deve ser capaz de lidar com muitas tarefas. Ele deve fazer isso com rapidez e precisão e, para dispositivos alimentados por bateria, o consumo de energia deve ser mínimo - mesmo quando o dispositivo está sempre ouvindo uma palavra de gatilho.
Para atender a essas demandas, processadores de sinal digital de uso geral (DSPs) ou microprocessadores provavelmente não estarão à altura do trabalho - em termos de custo, desempenho de processamento, tamanho e consumo de energia. Em vez disso, é provável que uma solução melhor seja um DSP específico do aplicativo, com funções de processamento de áudio dedicadas e software otimizado. A escolha de uma solução de hardware / software que já está otimizada para as tarefas de entrada de voz também reduzirá os custos de desenvolvimento e reduzirá substancialmente o tempo de lançamento no mercado, além de reduzir os custos gerais.
Por exemplo, o ClearVox da CEVA é um pacote de software de algoritmos de processamento de entrada de voz, que pode lidar com diferentes cenários acústicos e configurações de microfone, incluindo a direção de chegada da voz do alto-falante, formação de feixe multi-mic, supressão de ruído e cancelamento de eco acústico. ClearVox é otimizado para funcionar com eficiência em DSPs de som CEVA, para fornecer uma solução econômica e de baixo consumo de energia.
Assim como o processamento de voz, o dispositivo de borda precisará ser capaz de lidar com a detecção de palavras de gatilho. Uma solução especializada, como o WhisPro da CEVA, é uma excelente maneira de atingir a precisão e o baixo consumo de energia necessários (consulte a Figura 2). WhisPro é um pacote de software de reconhecimento de voz baseado em rede neural, disponível exclusivamente para DSPs da CEVA, que permite aos OEMs adicionar ativação por voz a seus produtos habilitados para voz. Ele pode lidar com a audição sempre ativa necessária, enquanto um processador principal permanece inativo até ser necessário, reduzindo significativamente o consumo geral de energia do sistema.
clique para ampliar a imagem
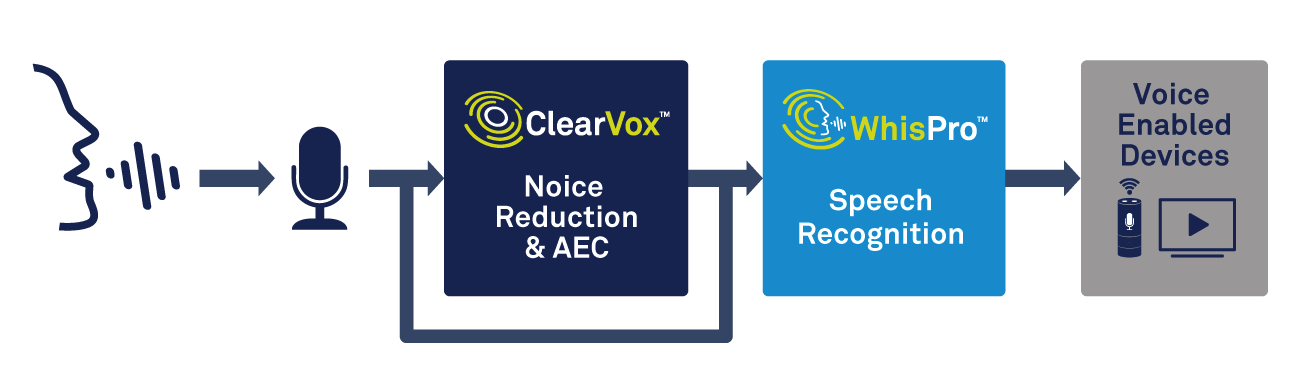
Figura 2:usando processamento de voz e reconhecimento de voz para ativação de voz. (Fonte:CEVA)
O WhisPro pode atingir uma taxa de reconhecimento de mais de 95% e pode suportar várias frases de gatilho, bem como palavras de gatilho personalizadas. Como qualquer pessoa que já usou um alto-falante inteligente pode testemunhar, fazer com que ele responda de maneira confiável à palavra de ativação - mesmo em um ambiente barulhento - às vezes pode ser uma experiência frustrante. Obter esse recurso certo pode fazer uma grande diferença na forma como os consumidores percebem a qualidade de um produto controlado por voz.
Reconhecimento de voz:local ou nuvem
Depois que a voz foi digitalizada e processada, precisamos de algum tipo de capacidade de reconhecimento automático de fala (ASR). Existe uma ampla gama de tecnologias ASR, desde a simples detecção de palavras-chave, que exige que o usuário diga palavras-chave específicas, até o sofisticado processamento de linguagem natural (PNL), em que um usuário pode falar normalmente como se estivesse se dirigindo a outra pessoa.
A detecção de palavras-chave tem muitos usos, mesmo que seu vocabulário seja extremamente limitado. Por exemplo, um dispositivo doméstico inteligente simples, como um interruptor de luz ou termostato, pode apenas responder a alguns comandos, como ‘ligar’, ‘desligar’, ‘mais brilhante’, ‘dimmer’ e assim por diante. Este nível de ASR pode ser facilmente administrado localmente, no limite, sem uma conexão com a Internet - mantendo assim os custos baixos, garantindo uma resposta rápida e evitando preocupações com segurança e privacidade.
Outro exemplo seria que muitos smartphones Android podem ser instruídos a tirar uma foto dizendo ‘queijo’ ou ‘sorria’, onde enviar o comando para a nuvem simplesmente demoraria muito. E isso presumindo que uma conexão com a Internet esteja disponível, o que nem sempre será o caso de um dispositivo como um smartwatch ou audível.
Por outro lado, muitos aplicativos exigem PNL. Se quiser perguntar ao alto-falante Echo sobre o tempo ou encontrar um hotel para você hoje à noite, você pode formular sua pergunta de várias maneiras. O dispositivo precisa ser capaz de compreender as possíveis nuances e coloquialismos no comando e trabalhar com segurança o que foi solicitado. Simplificando, ele precisa ser capaz de converter a fala em significado, ao invés de apenas falar em texto.
Para tomar nossa consulta de hotel como exemplo, há uma grande variedade de fatores possíveis sobre os quais você pode querer perguntar:preço, localização, avaliações e muitos outros. O sistema PNL tem que interpretar toda essa complexidade, bem como as muitas maneiras diferentes como uma pergunta pode ser formulada e a falta de clareza da solicitação - dizer "encontre um bom valor, hotel central" significará coisas diferentes para diferentes pessoas. A obtenção de resultados precisos também exige que o dispositivo considere o contexto da pergunta e reconheça quando o usuário faz perguntas de acompanhamento conectadas ou pede várias informações em uma consulta.
Isso pode exigir uma grande quantidade de processamento, normalmente usando inteligência artificial (IA) e redes neurais, o que geralmente não é prático para processamento apenas na borda. Um dispositivo de baixo custo com um processador embutido não terá energia suficiente para lidar com as tarefas necessárias. Nesse caso, a opção certa é enviar a fala digitalizada para processamento na nuvem. Lá, ele pode ser interpretado e uma resposta apropriada enviada de volta ao dispositivo controlado por voz.
Você pode ver que há compensações entre o processamento de borda no dispositivo e o processamento remoto na nuvem. Lidar com tudo localmente pode ser mais rápido e não depende de uma conexão com a Internet, mas terá dificuldade em lidar com uma gama mais ampla de perguntas e obtenção de informações. Isso significa que para um dispositivo de uso geral, como um alto-falante inteligente em casa, é necessário enviar pelo menos algum processamento para a nuvem.
Para lidar com as desvantagens do processamento em nuvem, há desenvolvimentos nos recursos dos processadores locais e, em um futuro próximo, podemos esperar grandes melhorias em PNL e IA em dispositivos de ponta. Novas técnicas estão reduzindo a quantidade de memória necessária e os processadores continuam a ficar mais rápidos e com menos consumo de energia.
Por exemplo, a família NeuPro de processadores AI de baixa potência da CEVA fornece recursos sofisticados para a borda. Com base na experiência da CEVA em redes neurais para visão computacional, esta família oferece uma solução flexível e escalonável para processamento de voz no dispositivo.
Conclusões
As interfaces controladas por voz estão rapidamente se tornando uma parte significativa de nossa vida cotidiana e serão adicionadas a mais e mais produtos em um futuro próximo. As melhorias estão sendo impulsionadas por melhores recursos de processamento de sinal e reconhecimento de voz, bem como recursos de computação mais poderosos, tanto localmente quanto na nuvem.
Para atender aos requisitos dos OEMs, os componentes usados para processamento de áudio e reconhecimento de voz precisam atender a alguns desafios difíceis, em termos de desempenho, custo e potência. Para muitos designers, as soluções que foram otimizadas especificamente para as tarefas em questão podem ser a melhor abordagem - atendendo às demandas do cliente final e reduzindo o tempo de chegada ao mercado.
Qualquer que seja a tecnologia em que se baseiam, as interfaces de voz ficarão mais precisas e fáceis de falar na linguagem do dia-a-dia, enquanto seus custos decrescentes os tornarão mais atraentes para os fabricantes. Vai ser uma jornada interessante para ver o que eles serão usados a seguir.
Integrado
- As tecnologias aprimoradas irão acelerar a aceitação de assistentes de voz
- Como fazer fibra de vidro
- Como tirar o melhor proveito de sua cadeia de suprimentos agora mesmo
- Como funcionam os sistemas SCADA?
- Como fazer uma bússola usando Arduino e IDE de processamento
- Como fazer um protótipo
- Como funcionam os secadores de ar?
- Como fazer os eletrônicos de amanhã usando grafeno impresso a jato de tinta
- Como funcionam os freios elétricos
- Como fazer um programa de segurança abrangente funcionar