


Edge AI desafia a tecnologia de memória
Com o surgimento da IA no limite, vem uma série de novos requisitos para sistemas de memória. As tecnologias de memória de hoje podem atender às demandas rigorosas deste novo aplicativo desafiador, e o que as tecnologias de memória emergentes prometem para a IA de ponta a longo prazo?
A primeira coisa a perceber é que não existe um aplicativo padrão de “IA de ponta”; a vanguarda em sua interpretação mais ampla cobre todos os sistemas eletrônicos habilitados para IA fora da nuvem. Isso pode incluir “near edge”, que geralmente cobre data centers corporativos e servidores locais.
Mais adiante estão aplicativos como a visão computacional para a direção autônoma. O equipamento de gateway para fabricação realiza inferência de IA para verificar se há falhas nos produtos da linha de produção. As “caixas de ponta” 5G em postes de serviços públicos analisam fluxos de vídeo para aplicativos de cidades inteligentes, como gerenciamento de tráfego. E a infraestrutura 5G usa IA na ponta para algoritmos de formação de feixes complexos, mas eficientes.
Na “extremidade distante”, a IA é compatível com dispositivos como telefones celulares - pense em filtros Snapchat - controle de voz de aparelhos e nós de sensores de IoT em fábricas que executam a fusão de sensores antes de enviar os resultados para outro dispositivo de gateway.
A função da memória em sistemas de IA de ponta - armazenar pesos de rede neural, código de modelo, dados de entrada e ativações intermediárias - é a mesma para a maioria das aplicações de IA. As cargas de trabalho devem ser aceleradas para maximizar a capacidade de computação de IA para permanecer eficiente, portanto, as demandas de capacidade e largura de banda são geralmente altas. No entanto, as demandas específicas da aplicação são muitas e variadas e podem incluir tamanho, consumo de energia, operação de baixa tensão, confiabilidade, considerações térmicas / de resfriamento e custo.
Data centers Edge
Os data centers de ponta são um mercado de ponta chave. Os casos de uso variam de imagens médicas, pesquisas e algoritmos financeiros complexos, em que a privacidade impede o upload para a nuvem. Outro são os veículos autônomos, onde a latência o impede.
Esses sistemas usam as mesmas memórias encontradas em servidores em outras aplicações.
“É importante usar DRAM de baixa latência para memória principal de nível de byte rápido em aplicativos onde algoritmos de IA estão sendo desenvolvidos e treinados”, disse Pekon Gupta, arquiteto de soluções da Smart Modular Technologies, um designer e desenvolvedor de produtos de memória. “RDIMMs ou LRDIMMs de alta capacidade são necessários para grandes conjuntos de dados. Os NVDIMMs são necessários para a aceleração do sistema - nós os usamos para gravação em cache e checkpoint em vez de SSDs mais lentos. ”

Pekon Gupta
Localizar nós de computação perto dos usuários finais é a abordagem adotada pelas operadoras de telecomunicações.
“Estamos vendo uma tendência de tornar esses servidores de ponta [telco] mais capazes de executar algoritmos complexos”, disse Gupta. Portanto, “os provedores de serviços estão adicionando mais memória e capacidade de processamento a esses servidores de borda usando dispositivos como RDIMM, LRDIMM e memória persistente de alta disponibilidade como NVDIMM”.
Gupta vê o Intel Optane, a memória não volátil 3D-Xpoint da empresa cujas propriedades estão entre DRAM e Flash, como uma boa solução para aplicativos de IA de servidor.
“Ambos Optane DIMMs e NVDIMMs estão sendo usados como aceleradores de IA”, disse ele. “Os NVDIMMs fornecem níveis de latência muito baixos, armazenamento em cache, buffer de gravação e recursos de armazenamento de metadados para aceleração de aplicativos de IA. Os DIMMs do data center Optane são usados para aceleração de banco de dados na memória, onde centenas de gigabytes a terabytes de memória persistente são usados em combinação com DRAM. Embora ambas sejam soluções de memória persistente para aplicativos de aceleração de AI / ML, elas têm casos de uso diferentes e separados. ”
Kristie Mann, diretora de marketing de produto da Intel para Optane, disse ao EE Times Optane está ganhando aplicações no segmento de IA de servidores.

Kristie Mann da Intel
“Nossos clientes já estão usando a memória persistente Optane para alimentar seus aplicativos de IA hoje”, disse ela. “Eles estão impulsionando o comércio eletrônico, os mecanismos de recomendação de vídeo e os usos de análise financeira em tempo real com sucesso. Estamos vendo uma mudança para os aplicativos in-memory devido ao aumento da capacidade disponível. ”
Os altos preços da DRAM estão cada vez mais tornando Optane uma alternativa atraente. Um servidor com dois processadores escaláveis Intel Xeon mais memória persistente Optane pode armazenar até 6 terabytes de memória para aplicativos com grande consumo de dados.
“A DRAM ainda é a mais popular, mas tem suas limitações do ponto de vista de custo e capacidade”, disse Mann. “Novas tecnologias de memória e armazenamento como a memória persistente Optane e Optane SSD estão [emergindo] como uma alternativa à DRAM devido à sua vantagem de custo, capacidade e desempenho. Os SSDs Optane são particularmente poderosos no armazenamento em cache de dados de HDD e NAND SSD para alimentar continuamente dados de aplicativos de IA. ”
Optane também se compara favoravelmente a outras memórias emergentes que não são totalmente maduras ou escaláveis hoje, ela acrescentou.

Um módulo Intel Optane série 200. A Intel afirma que o Optane já é
usado para alimentar aplicativos de IA atualmente. (Fonte:Intel)
aceleração GPU
Para data center de ponta de ponta e aplicativos de servidor de ponta, os aceleradores de computação AI, como GPUs, estão ganhando força. Bem como DRAM, as opções de memória aqui incluem GDDR, um DDR SDRAM especial projetado para alimentar GPUs de alta largura de banda, e HBM, uma tecnologia de empilhamento de dados relativamente nova que coloca vários dados de memória no mesmo pacote que a própria GPU.
Ambos são projetados para a largura de banda de memória extremamente alta exigida por aplicativos de IA.
Para o treinamento de modelo de IA mais exigente, HBM2E oferece 3,6 Gbps e fornece uma largura de banda de memória de 460 GB / s (duas pilhas HBM2E fornecem perto de 1 TB / s). Essa está entre as memórias de maior desempenho disponíveis, na menor área com o menor consumo de energia. O HBM é usado pela GPU líder Nvidia em todos os seus produtos de data center.
O GDDR6 também é usado para aplicativos de inferência de IA no limite, disse Frank Ferro, diretor sênior de marketing de produto para IP Cores da Rambus. Ferro disse que o GDDR6 pode atender aos requisitos de velocidade, custo e energia dos sistemas de inferência de IA de ponta. Por exemplo, o GDDR6 pode fornecer 18 Gbps e 72 GB / s. Ter quatro DRAMs GDDR6 fornece quase 300 GB / s de largura de banda de memória.
“GDDR6 é usado para aplicações de inferência AI e ADAS, acrescentou Ferro.
Ao comparar o GDDR6 ao LPDDR, a abordagem da Nvidia para a maioria das soluções de ponta que não são de datacenters, do Jetson AGX Xavier ao Jetson Nano, Ferro reconheceu que o LPDDR é adequado para inferência de IA de baixo custo na ponta ou terminal.
“A largura de banda do LPDDR é limitada a 4,2 Gbps para LPDDR4 e 6,4 Gbps para LPDDR5”, disse ele. “Conforme as demandas de largura de banda de memória aumentam, veremos um número crescente de projetos usando GDDR6. Essa lacuna de largura de banda de memória está ajudando a impulsionar a demanda por GDDR6. ”

Frank Ferro da Rambus
Apesar de ter sido projetado para caber ao lado de GPUs, outros aceleradores de processamento podem aproveitar a largura de banda do GDDR. Ferro destacou o Achronix Speedster7t, um acelerador de IA baseado em FPGA usado para inferência e alguns treinamentos básicos.
“Há espaço para as memórias HBM e GDDR em aplicações de IA de ponta”, disse Ferro. HBM “continuará a ser usado em aplicações de ponta. Apesar de todas as vantagens da HBM, o custo ainda é alto devido à tecnologia 3D e à fabricação 2.5D. Diante disso, GDDR6 é uma boa escolha entre custo e desempenho, especialmente para inferência de IA na rede. ”
O HBM é usado em ASICs AI de data centers de alto desempenho, como o Graphcore IPU. Embora ofereça um desempenho estelar, seu preço pode ser alto para algumas aplicações.
A Qualcomm está entre aqueles que usam essa abordagem. Seu Cloud AI 100 visa a aceleração de inferência de IA em data centers de ponta, “caixas de borda” 5G, ADAS / direção autônoma e infraestrutura 5G.
“Era importante para nós usar DRAM padrão em vez de algo como HBM, porque queremos manter a lista de materiais baixa”, disse Keith Kressin, gerente geral da unidade de computação e nuvem da Qualcomm. “Queríamos usar componentes padrão que você pudesse comprar de vários fornecedores. Temos clientes que desejam fazer tudo no chip e clientes que desejam usar cartões cruzados. Mas todos queriam manter o custo razoável e não ir para o HBM ou mesmo uma memória mais exótica.
“No treinamento”, ele continuou, “você tem modelos realmente grandes que iriam para [vários chips], mas para inferência [o mercado do Cloud AI 100], muitos dos modelos são mais localizados.”
A extremidade mais distante
Fora do data center, os sistemas de IA de ponta geralmente se concentram na inferência, com algumas exceções notáveis, como aprendizado federado e outras técnicas de treinamento incremental.
Alguns aceleradores de IA para aplicativos sensíveis ao consumo de energia usam memória para processamento de IA. A inferência, que é baseada na multiplicação de matrizes multidimensionais, se presta a técnicas de computação analógica com um conjunto de células de memória usadas para realizar cálculos. Usando esta técnica, os dispositivos da Syntiant são projetados para controle de voz de eletrônicos de consumo, e os dispositivos da Gyrfalcon foram projetados em um smartphone onde manipulam inferência para efeitos de câmera.
Em outro exemplo, o especialista em unidade de processamento inteligente Mythic usa operação analógica de células de memória flash para armazenar um valor inteiro de 8 bits (um parâmetro de peso) em um único transistor flash, tornando-o muito mais denso do que outras tecnologias de computação em memória. O transistor flash programado funciona como um resistor variável; as entradas são fornecidas como tensões e as saídas coletadas como correntes. Combinado com ADCs e DACs, o resultado é um mecanismo eficiente de multiplicação de matrizes.
O IP da Mythic reside nas técnicas de compensação e calibração que cancelam o ruído e permitem a computação confiável de 8 bits.
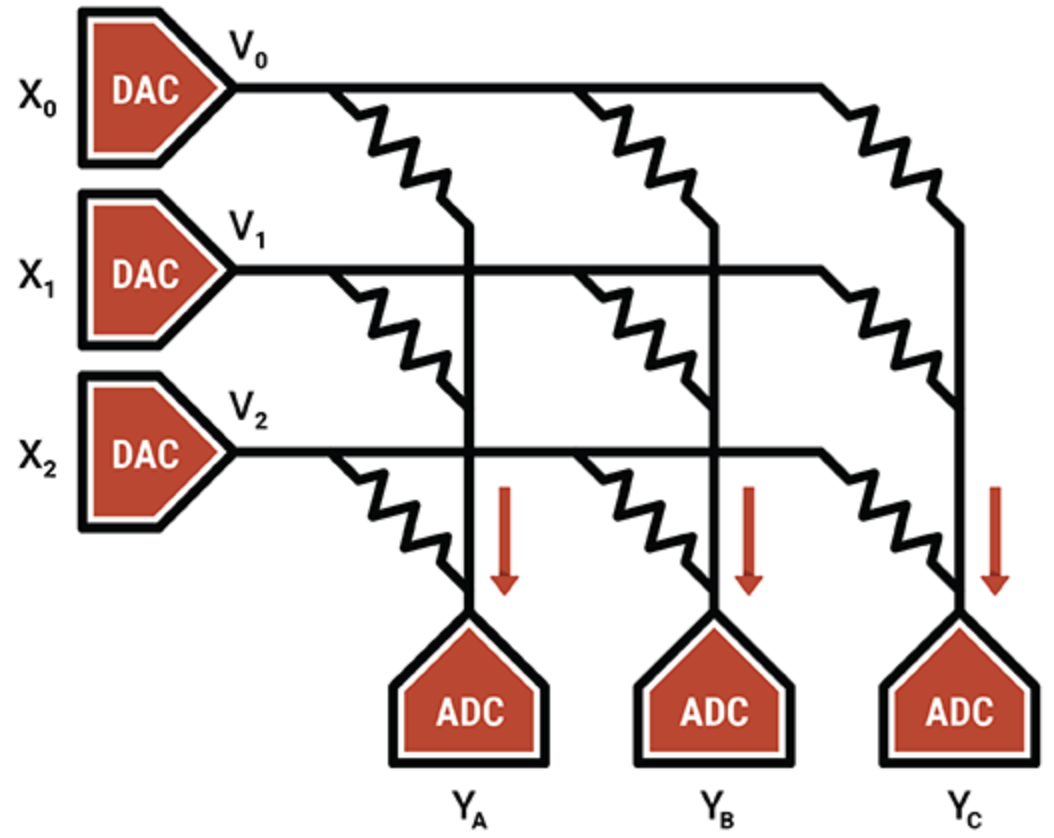
Mythic usa uma matriz de transistores de memória Flash para fazer motores densos de multiplicação-acumulação (Fonte:Mythic)
Além dos dispositivos de computação na memória, os ASICs são populares para nichos de borda específicos, particularmente para sistemas de baixa e ultrabaixa energia. Os sistemas de memória para ASICs usam uma combinação de vários tipos de memória. A SRAM local distribuída é a mais rápida, mais eficiente em termos de energia, mas não muito eficiente em área. Ter uma única SRAM em massa no chip é mais eficiente em relação à área, mas introduz gargalos de desempenho. DRAM fora do chip é mais barato, mas usa muito mais energia.
Geoff Tate, CEO da Flex Logix, disse que encontrar o equilíbrio certo entre SRAM distribuída, SRAM em massa e DRAM fora do chip para seu InferX X1 exigiu uma série de simulações de desempenho. O objetivo era maximizar o rendimento de inferência por dólar - uma função do tamanho da matriz, custo da embalagem e número de DRAMs usados.
“O ponto ideal era um único x32 LPDDR4 DRAM; 4K MACs (7,5 TOPS a 933 MHz); e cerca de 10 MB de SRAM ”, disse ele. “SRAM é rápido, mas é caro em comparação com DRAM. Usando a tecnologia de processo de 16 nm da TSMC, 1 MB de SRAM leva cerca de 1,1 mm
2
. “Nosso InferX X1 tem apenas 54 mm
2
e, devido à nossa arquitetura, os acessos DRAM são amplamente sobrepostos à computação, portanto, não há comprometimento do desempenho. Para modelos grandes, ter uma única DRAM é a compensação certa, pelo menos com nossa arquitetura ”, disse Tate.
O chip Flex Logix será usado em aplicativos de inferência de IA de ponta que requerem operação em tempo real, incluindo a análise de streaming de vídeo com baixa latência. Isso inclui sistemas ADAS, análise de imagens de segurança, imagens médicas e aplicativos de garantia / inspeção de qualidade.
Que tipo de DRAM irá junto com o InferX X1 nesses aplicativos?
“Achamos que o LPDDR será o mais popular:um único DRAM oferece mais de 10 GB / s de largura de banda ... ainda tem bits suficientes para armazenar os pesos / ativações intermediárias,” disse Tate. “Qualquer outra DRAM exigiria mais chips e interfaces e seriam necessários mais bits que não fossem usados.”
Há espaço para alguma tecnologia de memória emergente aqui?
“O custo do wafer aumenta drasticamente ao usar qualquer memória emergente, enquanto SRAM é‘ grátis ’, exceto para a área de silício”, acrescentou. “Conforme a economia muda, o ponto de inflexão também pode mudar, mas será mais adiante.”
Memórias emergentes
Apesar da economia de escala, outros tipos de memória oferecem possibilidades futuras para aplicativos de IA.
MRAM (RAM magneto-resistiva) armazena cada bit de dados por meio da orientação de ímãs controlados por uma tensão elétrica aplicada. Se a tensão for menor do que o necessário para inverter o bit, há apenas uma probabilidade de que o bit seja invertido. Essa aleatoriedade é indesejada, então o MRAM é acionado com tensões mais altas para evitá-lo. Ainda assim, alguns aplicativos de IA podem tirar vantagem dessa estocassidade inerente (que pode ser considerada como o processo de selecionar ou gerar dados aleatoriamente).
Os experimentos aplicaram os recursos de estocassidade do MRAM aos dispositivos do Gyrfalcon, uma técnica pela qual a precisão de todos os pesos e ativações é reduzida para 1 bit. Isso é usado para reduzir drasticamente os requisitos de computação e energia para aplicativos de ponta. Prováveis trade-offs com precisão, dependendo de como a rede é treinada novamente. Em geral, as redes neurais podem funcionar de forma confiável, apesar da precisão reduzida.
“As redes neurais binárias são únicas porque podem funcionar de forma confiável mesmo quando a certeza de um número ser -1 ou +1 é reduzida”, disse Andy Walker, vice-presidente de produto da Spin Memory. “Descobrimos que tais BNNs ainda podem funcionar com altos níveis de precisão, pois essa certeza é reduzida [pela] introdução do que é chamado de 'taxa de erro de bit' dos bits de memória sendo gravados incorretamente”.

Andy Walker da Spin Memory
O MRAM pode introduzir naturalmente taxas de erro de bit de maneira controlada em níveis de baixa tensão, mantendo a precisão e reduzindo ainda mais os requisitos de energia. A chave é determinar a precisão ideal na tensão mais baixa e no menor tempo. Isso se traduz na mais alta eficiência energética, disse Walker.
Embora essa técnica também se aplique a redes neurais de maior precisão, é especialmente adequada para BNNs porque a célula MRAM tem dois estados, que correspondem aos estados binários em um BNN.
Usar o MRAM na borda é outra aplicação potencial, de acordo com Walker.
“Para a IA de ponta, o MRAM tem a capacidade de funcionar com tensões mais baixas em aplicações onde a precisão de alto desempenho não é um requisito, mas as melhorias na eficiência energética e na durabilidade da memória são muito importantes”, disse ele. “Além disso, a não-volatilidade inerente do MRAM permite a conservação de dados sem energia.
Uma aplicação é a chamada memória unificada “onde esta memória emergente pode atuar como um flash embutido e substituição de SRAM, economizando área na matriz e evitando a dissipação de energia estática inerente à SRAM.”
Enquanto o MRAM da Spin Memory está prestes a ser adotado comercialmente, a implementação específica do BNN funcionaria melhor em uma variante da célula MRAM básica. Portanto, permanece em fase de pesquisa.
ReRAM neuromórfico
Outra memória emergente para aplicativos de IA de ponta é ReRAM. Uma pesquisa recente do Politécnico de Milão usando a tecnologia de óxido de silício (SiOx) ReRAM da Weebit Nano mostrou-se promissora para a computação neuromórfica. ReRAM adicionou uma dimensão de plasticidade ao hardware da rede neural; ou seja, pode evoluir conforme as condições mudam - uma qualidade útil na computação neuromórfica.
As redes neurais atuais não podem aprender sem esquecer as tarefas nas quais foram treinadas, enquanto o cérebro pode fazer isso com bastante facilidade. Em termos de IA, isso é “aprendizado não supervisionado”, em que o algoritmo realiza inferência em conjuntos de dados sem rótulos, procurando seus próprios padrões nos dados. O resultado final poderia ser sistemas de IA de borda habilitados para ReRAM que podem aprender novas tarefas in-situ e se adaptar ao ambiente ao seu redor.
No geral, os fabricantes de memória estão introduzindo tecnologias que oferecem velocidade e largura de banda necessárias para aplicativos de IA. Various memories, whether on the same chip as the AI compute, in the same package, or on separate modules, are available to suit many edge AI application.
While the exact nature of memory systems for edge AI depends on the application, GDDR, HBM and Optane are proving popular for data centers, while LPDDR competes with on-chip SRAM for endpoint applications.
Emerging memories are lending their novel properties to research designed to advance neural networks beyond the capabilities of today’s hardware to enable future power-efficient, brain-inspired systems.
>> Este artigo foi publicado originalmente em nosso site irmão, EE Times.
Integrado
- Memória somente leitura (ROM)
- Microprocessadores
- Big Data, Não Big Easy:Superando Novos Desafios na Tecnologia de Manutenção de Fábrica
- Memória de mudança de fase incorporada de amostragem ST para microcontroladores automotivos
- A tecnologia de aplicação de borda beneficia todos os setores
- 5G e Edge levantam novos desafios de segurança cibernética para 2021
- 4 dicas e desafios para um melhor gerenciamento de ativos de IIoT
- 3 exemplos principais de tecnologia de fabricação avançada de ponta
- Tecnologia de movimento linear
- Como a tecnologia conectada pode ajudar a resolver os desafios da cadeia de suprimentos