


Aproveitando FPGAs para aprendizado profundo
Recentemente, participei do Fórum de Desenvolvimento Xilinx (XDF) 2018 no Vale do Silício. Enquanto estava neste fórum, fui apresentado a uma empresa chamada Mipsology, uma startup no campo de inteligência artificial (IA) que afirma ter resolvido os problemas relacionados à IA associados a matrizes de portas programáveis em campo (FPGAs). A Mipsology foi fundada com a grande visão de acelerar a computação de qualquer rede neural (NN) com o mais alto desempenho possível em FPGAs sem as restrições inerentes à sua implantação.
A Mipsology demonstrou a capacidade de executar mais de 20.000 imagens por segundo, rodando nas recém-anunciadas placas Alveo da Xilinx e processando uma coleção de NNs, incluindo ResNet50, InceptionV3, VGG19, entre outros.
Apresentando as redes neurais e o aprendizado profundo
Vagamente modelada na teia de neurônios do cérebro humano, uma rede neural está na base do aprendizado profundo (DL), um sistema matemático complexo que pode aprender tarefas por conta própria. Observando muitos exemplos ou associações, um NN pode aprender conexões e relacionamentos mais rápidos do que um programa de reconhecimento tradicional. O processo de configuração de um NN para realizar uma tarefa específica com base no aprendizado milhões de amostras do mesmo tipo são chamadas de treinamento .
Por exemplo, um NN pode ouvir muitos samples vocais e usar DL para aprender a “reconhecer” os sons de palavras específicas. Este NN poderia então vasculhar uma lista de novas amostras vocais e identificar corretamente as amostras contendo palavras que aprendeu, usando uma técnica chamada inferência .
Apesar de sua complexidade, o DL é baseado na realização de operações simples - principalmente adições e multiplicações - na casa dos bilhões ou trilhões. A demanda computacional para realizar tais operações é assustadora. Mais especificamente, as necessidades de computação para executar inferências DL são maiores do que para o treinamento DL. Enquanto o treinamento de DL deve ser realizado apenas uma vez, um NN, uma vez treinado, deve realizar inferências repetidas vezes para cada nova amostra que receber.
Quatro opções para acelerar a inferência de aprendizado profundo
Com o tempo, a comunidade de engenheiros recorreu a quatro dispositivos de computação diferentes para processar NNs. Em ordem crescente de potência de processamento e consumo de energia, e em ordem decrescente de flexibilidade / adaptabilidade, esses dispositivos abrangem:unidades de processamento central (CPUs), unidades de processamento gráfico (GPUs), FPGAs e circuitos integrados de aplicativos específicos (ASICs). A tabela abaixo resume as principais diferenças entre os quatro dispositivos de computação.
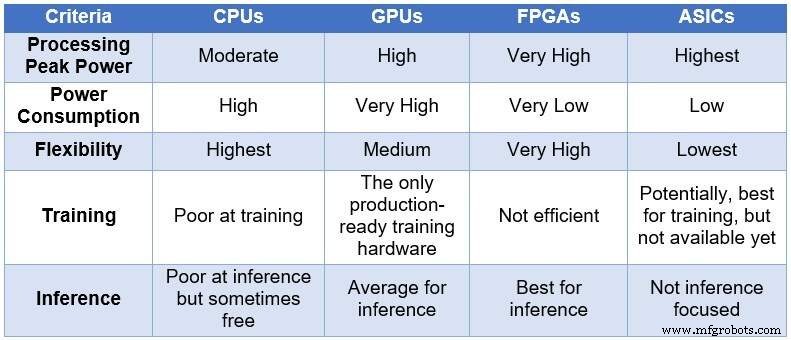
Comparação de CPUs, GPUs, FPGAs e ASICs para computação DL (Fonte:Lauro Rizzatti)
CPUs são baseadas na arquitetura Von Neuman. Embora flexíveis (a razão de sua existência), as CPUs são afetadas pela longa latência por causa dos acessos à memória que consomem vários ciclos de clock para executar uma tarefa simples. Quando aplicados a tarefas que se beneficiam das latências mais baixas, como computação NN e, especificamente, treinamento e inferência de DL, eles são a pior escolha.
As GPUs fornecem alta taxa de transferência de computação ao custo de menor flexibilidade. Além disso, as GPUs consomem energia significativa que exige resfriamento, tornando-as menos que ideais para implantação em data centers.
Embora ASICs personalizados possam parecer a solução ideal, eles têm seu próprio conjunto de problemas. O desenvolvimento de um ASIC leva anos. DL e NN estão evoluindo rapidamente com avanços contínuos, tornando a tecnologia do ano passado irrelevante. Além disso, para competir com uma CPU ou GPU, um ASIC precisaria usar uma grande área de silício usando a tecnologia de nó de processo mais fina. Isso torna o investimento inicial caro, sem qualquer garantia de relevância a longo prazo. Tudo considerado, os ASICs são eficazes para tarefas específicas.
Os dispositivos FPGA surgiram como a melhor escolha possível para inferência. Eles são rápidos, flexíveis, eficientes em termos de energia e oferecem uma boa solução para processamento de dados em data centers, especialmente no mundo dinâmico de DL, na borda da rede e sob a mesa de cientistas de IA.
Os maiores FPGAs disponíveis hoje incluem milhões de operadores booleanos simples, milhares de memórias e DSPs e vários núcleos ARM de CPU. Todos esses recursos funcionam em paralelo - cada tique do relógio aciona até milhões de operações simultâneas - resultando em trilhões de operações realizadas a cada segundo. O processamento exigido pelo DL mapeia muito bem os recursos FPGA.
FPGAs têm outras vantagens sobre CPUs e GPUs usados para DL, incluindo o seguinte:
-
Eles não estão limitados a certos tipos de dados. Eles podem lidar com baixa precisão não padronizada, mais adequada para fornecer maior rendimento para DL.
-
Eles usam menos energia do que CPUs ou GPUs - geralmente cinco a 10 vezes menos energia média para o mesmo cálculo NN. Seu custo recorrente em data centers é menor.
-
Eles podem ser reprogramados para caber em qualquer tarefa, mas ser genéricos o suficiente para acomodar vários empreendimentos. DL está evoluindo rapidamente e o mesmo FPGA atenderá aos novos requisitos sem a necessidade do silício de última geração (o que é típico dos ASICs), reduzindo assim o custo de propriedade.
-
Eles variam de dispositivos grandes a pequenos. Eles podem ser usados em centros de dados ou em um nó da Internet das coisas (IoT). A única diferença é o número de blocos que eles contêm.
Nem tudo que reluz é ouro
O alto poder computacional, o baixo consumo de energia e a flexibilidade de um FPGA têm um preço - dificuldade de programar.
Tecnologia da Internet das Coisas
- CEVA:processador AI de segunda geração para cargas de trabalho de rede neural profunda
- Argumentando sobre chips neuromórficos para computação IA
- ICP:placa aceleradora baseada em FPGA para inferência de aprendizagem profunda
- IA terceirizada e aprendizagem profunda no setor de saúde - A privacidade de dados está em risco?
- Como a indústria de alta tecnologia está alavancando a IA para o crescimento exponencial dos negócios
- Inteligência Artificial vs Aprendizado de Máquina vs Aprendizado Profundo | A diferença
- Equipe da Apple e IBM Watson para aprendizado de máquina móvel empresarial
- Deep Learning e seus muitos aplicativos
- Solução de estabilidade de ferramenta para furação profunda
- Como o aprendizado profundo automatiza a inspeção para o setor de ciências biológicas