


O que é Hadoop? Processamento de Big Data Hadoop
A evolução do big data produziu novos desafios que necessitavam de novas soluções. Como nunca antes na história, os servidores precisam processar, classificar e armazenar grandes quantidades de dados em tempo real.
Esse desafio levou ao surgimento de novas plataformas, como o Apache Hadoop, que podem lidar com grandes conjuntos de dados com facilidade.
Neste artigo, você aprenderá o que é o Hadoop, quais são seus principais componentes e como o Apache Hadoop ajuda no processamento de big data.
O que é Hadoop?
A biblioteca de software Apache Hadoop é uma estrutura de código aberto que permite gerenciar e processar big data com eficiência em um ambiente de computação distribuído.
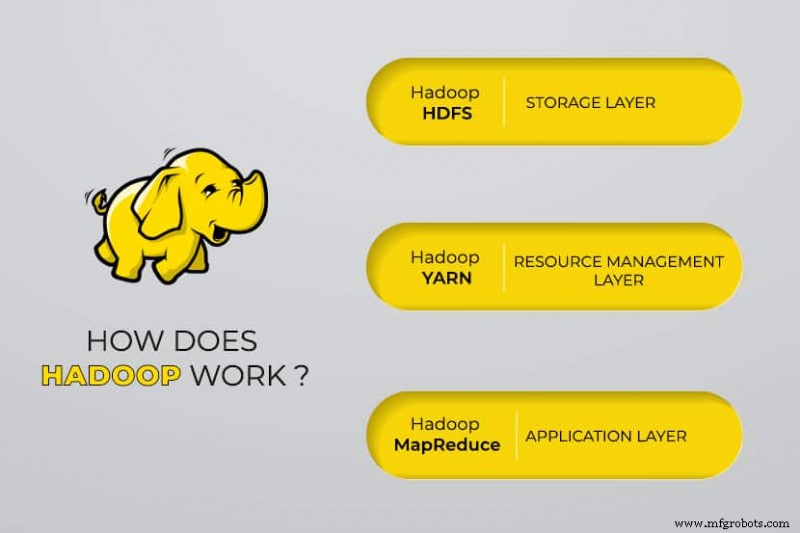
O Apache Hadoop consiste em quatro módulos principais :
Sistema de Arquivos Distribuídos Hadoop (HDFS)
Os dados residem no Sistema de Arquivos Distribuídos do Hadoop, que é semelhante ao de um sistema de arquivos local em um computador típico. O HDFS oferece melhor taxa de transferência de dados quando comparado aos sistemas de arquivos tradicionais.
Além disso, o HDFS oferece excelente escalabilidade. Você pode escalar de uma única máquina para milhares com facilidade e em hardware comum.
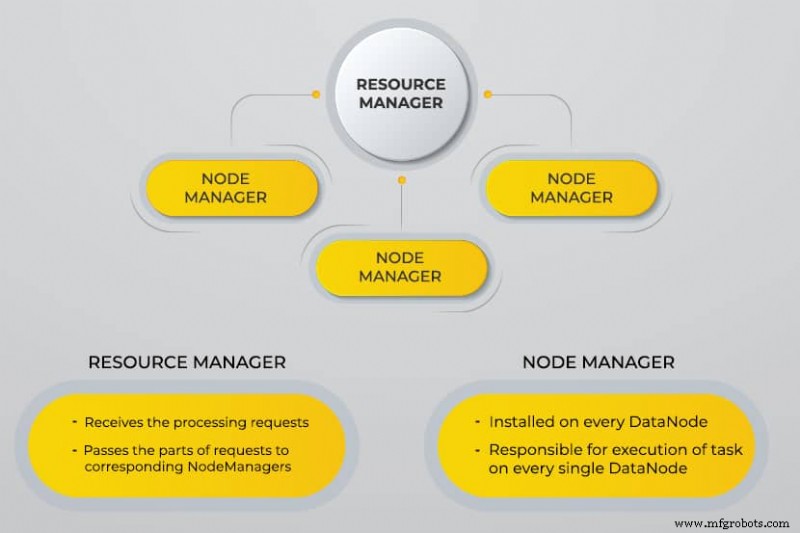
Mais um negociador de recursos (YARN)
O YARN facilita tarefas agendadas, gerenciamento completo e monitoramento de nós de cluster e outros recursos.
MapReduce
O módulo Hadoop MapReduce ajuda os programas a realizar cálculos de dados paralelos. A tarefa Map do MapReduce converte os dados de entrada em pares chave-valor. As tarefas de redução consomem a entrada, agregam e produzem o resultado.
Comum Hadoop
O Hadoop Common usa bibliotecas Java padrão em todos os módulos.
Por que o Hadoop foi desenvolvido?
A World Wide Web cresceu exponencialmente durante a última década e agora consiste em bilhões de páginas. A busca de informações online tornou-se difícil devido à sua quantidade significativa. Esses dados se tornaram big data e consistem em dois problemas principais:
- Dificuldade em armazenar todos esses dados de maneira eficiente e fácil de recuperar
- Dificuldade no processamento dos dados armazenados
Os desenvolvedores trabalharam em muitos projetos de código aberto para retornar resultados de pesquisa na Web com mais rapidez e eficiência, abordando os problemas acima. A solução foi distribuir dados e cálculos em um cluster de servidores para obter processamento simultâneo.
Eventualmente, o Hadoop veio a ser uma solução para esses problemas e trouxe muitos outros benefícios, incluindo a redução dos custos de implantação de servidores.
Como funciona o processamento de Big Data do Hadoop?
Usando o Hadoop, utilizamos a capacidade de armazenamento e processamento de clusters e implementamos o processamento distribuído para big data. Essencialmente, o Hadoop fornece uma base sobre a qual você cria outros aplicativos para processar big data.
Os aplicativos que coletam dados em diferentes formatos os armazenam no cluster do Hadoop por meio da API do Hadoop, que se conecta ao NameNode. O NameNode captura a estrutura do diretório de arquivos e o posicionamento dos “pedaços” para cada arquivo criado. O Hadoop replica esses fragmentos em DataNodes para processamento paralelo.
MapReduce realiza consulta de dados. Ele mapeia todos os DataNodes e reduz as tarefas relacionadas aos dados no HDFS. O próprio nome “MapReduce” descreve o que ele faz. As tarefas de mapeamento são executadas em cada nó para os arquivos de entrada fornecidos, enquanto os redutores são executados para vincular os dados e organizar a saída final.
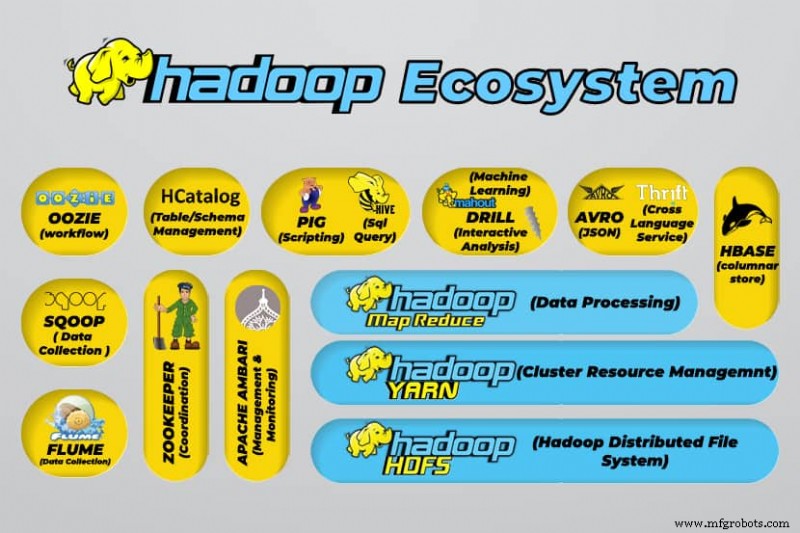
Ferramentas de Big Data do Hadoop
O ecossistema do Hadoop suporta uma variedade de ferramentas de big data de código aberto. Essas ferramentas complementam os principais componentes do Hadoop e aprimoram sua capacidade de processar big data.
As ferramentas de processamento de big data mais úteis incluem:
- Apache Hive
Apache Hive é um data warehouse para processar grandes conjuntos de dados armazenados no sistema de arquivos do Hadoop.
- Apache Zookeeper
O Apache Zookeeper automatiza os failovers e reduz o impacto de um NameNode com falha.
- Apache HBase
O Apache HBase é um banco de dados não relacional de código aberto para o Hadoop.
- Apache Flume
O Apache Flume é um serviço distribuído para streaming de dados de grandes quantidades de dados de log.
- Apache Sqoop
Apache Sqoop é uma ferramenta de linha de comando para migrar dados entre o Hadoop e bancos de dados relacionais.
- Porco Apache
O Apache Pig é a plataforma de desenvolvimento do Apache para desenvolver trabalhos executados no Hadoop. A linguagem do software em uso é Pig Latin.
- Apache Oozie
Apache Oozie é um sistema de agendamento que facilita o gerenciamento de tarefas do Hadoop.
- Apache HCatalog
Apache HCatalog é uma ferramenta de armazenamento e gerenciamento de tabelas para classificar dados de diferentes ferramentas de processamento de dados.
Vantagens do Hadoop
O Hadoop é uma solução robusta para processamento de big data e é uma ferramenta essencial para empresas que lidam com big data.
Os principais recursos e vantagens do Hadoop são detalhados abaixo:
- Armazenamento e processamento mais rápidos de grandes quantidades de dados
A quantidade de dados a serem armazenados aumentou drasticamente com a chegada das mídias sociais e da Internet das Coisas (IoT). O armazenamento e o processamento desses conjuntos de dados são essenciais para as empresas que os possuem. - Flexibilidade
A flexibilidade do Hadoop permite que você salve tipos de dados não estruturados, como texto, símbolos, imagens e vídeos. Em bancos de dados relacionais tradicionais, como RDBMS, você precisará processar os dados antes de armazená-los. No entanto, com o Hadoop, o pré-processamento de dados não é necessário, pois você pode armazenar os dados como estão e decidir como processá-los posteriormente. Em outras palavras, ele se comporta como um banco de dados NoSQL. - Poder de processamento
O Hadoop processa big data por meio de um modelo de computação distribuída. Seu uso eficiente do poder de processamento o torna rápido e eficiente. - Custo reduzido
Muitas equipes abandonaram seus projetos antes da chegada de frameworks como o Hadoop, devido aos altos custos incorridos. O Hadoop é uma estrutura de código aberto, de uso gratuito e usa hardware de commodity barato para armazenar dados. - Escalabilidade
O Hadoop permite dimensionar rapidamente seu sistema sem muita administração, apenas alterando o número de nós em um cluster. - Tolerância a falhas
Uma das muitas vantagens de usar um modelo de dados distribuído é sua capacidade de tolerar falhas. O Hadoop não depende de hardware para manter a disponibilidade. Se um dispositivo falhar, o sistema redireciona automaticamente a tarefa para outro dispositivo. A tolerância a falhas é possível porque os dados redundantes são mantidos salvando várias cópias de dados no cluster. Em outras palavras, a alta disponibilidade é mantida na camada de software.
Os três principais casos de uso
Processamento de big data
Recomendamos o Hadoop para grandes quantidades de dados, geralmente na faixa de petabytes ou mais. É mais adequado para grandes quantidades de dados que exigem enorme poder de processamento. O Hadoop pode não ser a melhor opção para uma organização que processa quantidades menores de dados na faixa de várias centenas de gigabytes.
Armazenamento de um conjunto diversificado de dados
Uma das muitas vantagens de usar o Hadoop é que ele é flexível e suporta vários tipos de dados. Independentemente de os dados consistirem em texto, imagens ou dados de vídeo, o Hadoop pode armazená-los com eficiência. As organizações podem escolher como processam os dados, dependendo de seus requisitos. O Hadoop tem as características de um data lake, pois oferece flexibilidade sobre os dados armazenados.
Processamento paralelo de dados
O algoritmo MapReduce usado no Hadoop orquestra o processamento paralelo de dados armazenados, o que significa que você pode executar várias tarefas simultaneamente. No entanto, operações conjuntas não são permitidas, pois confundem a metodologia padrão no Hadoop. Ele incorpora paralelismo desde que os dados sejam independentes uns dos outros.
Para que serve o Hadoop no mundo real
Empresas de todo o mundo usam sistemas de processamento de big data Hadoop. Alguns dos muitos usos práticos do Hadoop estão listados abaixo:
- Compreendendo os requisitos do cliente
Nos dias atuais, o Hadoop provou ser muito útil para entender os requisitos do cliente. As principais empresas do setor financeiro e de mídia social usam essa tecnologia para entender os requisitos dos clientes, analisando big data em relação à sua atividade.
As empresas usam esses dados para fornecer ofertas personalizadas aos clientes. Você pode ter experimentado isso por meio de anúncios exibidos em mídias sociais e sites de comércio eletrônico com base em nossos interesses e atividades na Internet. - Otimização de processos de negócios
O Hadoop ajuda a otimizar o desempenho das empresas analisando melhor suas transações e dados de clientes. A análise de tendências e a análise preditiva podem ajudar as empresas a personalizar seus produtos e estoques para aumentar as vendas. Essa análise facilitará uma melhor tomada de decisão e levará a maiores lucros.
Além disso, as empresas usam o Hadoop para melhorar seu ambiente de trabalho, monitorando o comportamento dos funcionários e coletando dados sobre suas interações entre si. - Melhorar os serviços de saúde
Instituições do setor médico podem usar o Hadoop para monitorar a grande quantidade de dados sobre problemas de saúde e resultados de tratamentos médicos. Os pesquisadores podem analisar esses dados para identificar problemas de saúde, prever medicamentos e decidir sobre planos de tratamento. Essas melhorias permitirão que os países melhorem seus serviços de saúde rapidamente. - Negociação financeira
O Hadoop possui um algoritmo sofisticado para escanear dados de mercado com configurações predefinidas para identificar oportunidades de negociação e tendências sazonais. As empresas financeiras podem automatizar a maioria dessas operações por meio dos recursos robustos do Hadoop. - Usando o Hadoop para IoT
Os dispositivos IoT dependem da disponibilidade de dados para funcionar com eficiência. Fabricantes e inventores usam o Hadoop como o data warehouse para bilhões de transações. Como a IoT é um conceito de streaming de dados, o Hadoop é uma solução adequada e prática para gerenciar as grandes quantidades de dados que ela abrange.
O Hadoop é atualizado continuamente, o que nos permite melhorar as instruções usadas com plataformas IoT.
Outros usos práticos do Hadoop incluem melhorar o desempenho do dispositivo, melhorar a quantificação pessoal e a otimização do desempenho, melhorar esportes e pesquisas científicas.
Quais são os desafios de usar o Hadoop?
Cada aplicação vem com vantagens e desafios. O Hadoop também apresenta vários desafios:
- O algoritmo MapReduce nem sempre é a solução
O algoritmo MapReduce não suporta todos os cenários. É adequado para solicitações de informações simples e problemas que são divididos em unidades independentes, mas não para tarefas iterativas.
O MapReduce é ineficiente para computação analítica avançada, pois algoritmos iterativos exigem intercomunicação intensiva e cria vários arquivos na fase MapReduce. - Gerenciamento de dados totalmente desenvolvido
O Hadoop não fornece ferramentas abrangentes para gerenciamento de dados, metadados e governança de dados. Além disso, carece das ferramentas necessárias para padronização de dados e determinação da qualidade. - Falta de talentos
Devido à curva de aprendizado íngreme do Hadoop, pode ser difícil encontrar programadores iniciantes com habilidades em Java que sejam suficientes para serem produtivos com o MapReduce. Essa intensidade é a principal razão pela qual os provedores estão interessados em colocar a tecnologia de banco de dados relacional (SQL) no topo do Hadoop, porque é muito mais fácil encontrar programadores com conhecimento sólido em SQL do que habilidades em MapReduce.
A administração do Hadoop é uma arte e uma ciência, exigindo conhecimento de baixo nível de sistemas operacionais, hardware e configurações do kernel do Hadoop. - Segurança de dados
O protocolo de autenticação Kerberos é um passo significativo para tornar os ambientes Hadoop seguros. A segurança dos dados é fundamental para proteger os sistemas de big data de problemas de segurança de dados fragmentados.
Conclusão
O Hadoop é altamente eficaz para lidar com o processamento de big data quando implementado de forma eficaz com as etapas necessárias para superar seus desafios. É uma ferramenta versátil para empresas que lidam com grandes quantidades de dados.
Uma de suas principais vantagens é que ele pode ser executado em qualquer hardware e um cluster Hadoop pode ser distribuído entre milhares de servidores. Essa flexibilidade é particularmente significativa em ambientes de infraestrutura como código.
On-Premise vs Cloud:Qual é o certo para o seu negócio?
30 ferramentas de monitoramento de nuvem:o guia definitivo para 2021
Computação em Nuvem
- Big Data e computação em nuvem:uma combinação perfeita
- O que é segurança em nuvem e por que é necessária?
- Qual é a relação entre big data e computação em nuvem?
- Uso de Big Data e computação em nuvem nos negócios
- O que esperar das plataformas IoT em 2018
- Manutenção preditiva - O que você precisa saber
- O que exatamente é RAM DDR5? Recursos e disponibilidade
- O que é IIoT?
- Big Data x Inteligência Artificial
- Criando Big Data a partir de Little Data