


Arquitetura de rede neural para uma implementação Python
Este artigo discute a configuração do Perceptron que usaremos em nossos experimentos com treinamento e classificação de redes neurais, e também examinaremos o tópico relacionado de nós de polarização.
Bem-vindo à série de artigos técnicos de rede neural All About Circuits. Na série até agora - com link abaixo - cobrimos um pouco da teoria em torno das redes neurais.
- Como realizar a classificação usando uma rede neural:o que é o Perceptron?
- Como usar um exemplo de rede neural simples Perceptron para classificar dados
- Como treinar uma rede neural Perceptron básica
- Compreendendo o treinamento de rede neural simples
- Uma introdução à teoria de treinamento para redes neurais
- Compreendendo a taxa de aprendizagem em redes neurais
- Aprendizado de máquina avançado com o Multilayer Perceptron
- A função de ativação sigmóide:ativação em redes neurais multicamadas Perceptron
- Como treinar uma rede neural multicamadas Perceptron
- Noções básicas sobre fórmulas de treinamento e retropropagação para percepções multicamadas
- Arquitetura de rede neural para uma implementação Python
- Como criar uma rede neural multicamadas Perceptron em Python
- Processamento de sinais usando redes neurais:validação no projeto de redes neurais
- Conjuntos de dados de treinamento para redes neurais:como treinar e validar uma rede neural Python
Agora estamos prontos para começar a converter este conhecimento teórico em um sistema de classificação Perceptron funcional.
Primeiro, quero apresentar as características gerais da rede que implementaremos em uma linguagem de programação de alto nível; Estou usando Python, mas o código será escrito de uma forma que facilite a tradução para outras linguagens como C. O próximo artigo fornece uma explicação detalhada do código Python e, depois disso, exploraremos diferentes maneiras de treinamento , usando e avaliando esta rede.
A arquitetura de rede neural Python
O software corresponde ao Perceptron representado no diagrama a seguir.
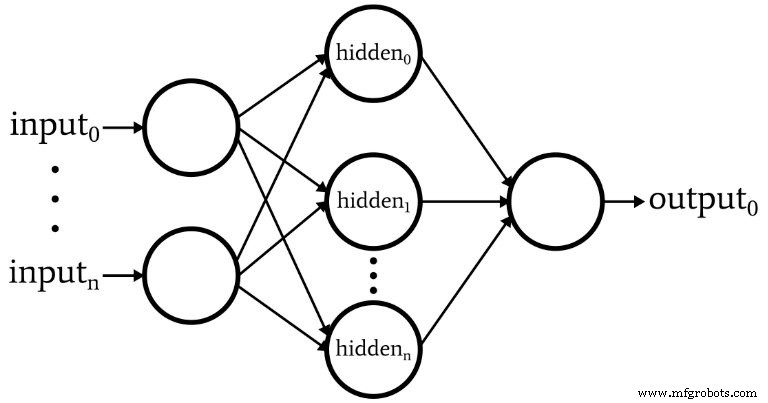
Aqui estão as características básicas da rede:
- O número de nós de entrada é variável. Isso é essencial se quisermos uma rede que tenha algum grau significativo de flexibilidade, porque a dimensionalidade de entrada deve corresponder à dimensionalidade das amostras que queremos classificar.
- O código não oferece suporte a várias camadas ocultas. Neste ponto, não há necessidade - uma camada oculta é suficiente para uma classificação extremamente poderosa.
- O número de nós em uma camada oculta é variável. Encontrar o número ideal de nós ocultos envolve algumas tentativas e erros, embora existam diretrizes que podem nos ajudar a escolher um ponto de partida razoável. Exploraremos a questão da dimensionalidade da camada oculta em um artigo futuro.
- O número de nós de saída está atualmente fixado em um. Essa limitação tornará nosso programa inicial um pouco mais simples e podemos incorporar dimensionalidade de saída variável em uma versão aprimorada.
- A função de ativação para nós ocultos e de saída será o relacionamento sigmóide logístico padrão:
\ [f (x) =\ frac {1} {1 + e ^ {- x}} \]
O que é um nó de polarização? (Também conhecido como preconceito é bom se você for um perceptor)
Enquanto estamos discutindo a arquitetura de rede, devo salientar que as redes neurais geralmente incorporam algo chamado de nó de polarização (ou você pode chamá-lo apenas de "polarização", sem "nó"). O valor numérico associado a um nó de polarização é uma constante escolhida pelo designer. Por exemplo:
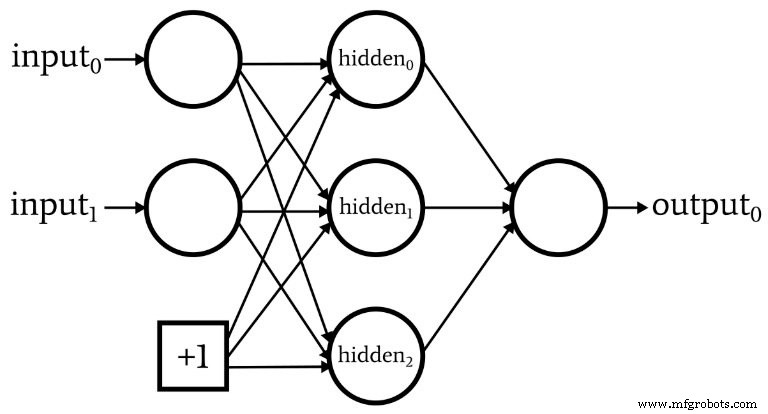
Nós de polarização podem ser incorporados à camada de entrada ou à camada oculta, ou ambas. Seus pesos são como quaisquer outros pesos e são atualizados usando o mesmo procedimento de retropropagação.
O uso de nós de polarização é uma razão importante para escrever código de rede neural que permite alterar facilmente o número de nós de entrada ou nós ocultos - mesmo se você estiver interessado apenas em uma tarefa de classificação específica, dimensão variável de entrada e camada oculta garante que você possa experimentar convenientemente o uso de nós de polarização.
Na Parte 10, eu indiquei que o sinal de pré-ativação de um nó é calculado realizando um produto escalar - ou seja, você multiplica os elementos correspondentes de duas matrizes (ou vetores, se preferir) e, em seguida, soma todos os produtos individuais. O primeiro array contém os valores de pós-ativação da camada anterior e o segundo array contém os pesos que conectam a camada anterior à camada atual. Assim, se a matriz de pós-ativação da camada anterior for denotada por xe o vetor de peso for denotado por w, um valor de pré-ativação é calculado da seguinte forma:
\ [S_ {preA} =w \ cdot x =sum (w_1x_1 + w_2x_2 + \ cdots + w_nx_n) \]
Você deve estar se perguntando o que diabos isso tem a ver com nós de polarização. Bem, o viés (denotado por b) modifica este procedimento da seguinte forma:
\ [S_ {preA} =(w \ cdot x) + b =sum (w_1x_1 + w_2x_2 + \ cdots + w_nx_n) + b \]
Uma polarização desloca o sinal que é processado pela função de ativação e pode, assim, tornar a rede mais flexível e robusta. O uso da letra b para denotar o valor de polarização é uma reminiscência do "intercepto y" na equação padrão para uma linha reta:y =mx + b . E isso não é uma coincidência inútil. A polarização é de fato como uma interceptação y, e você também deve ter notado que a matriz de pesos é equivalente a uma inclinação:
\ [S_ {preA} =(w \ cdot x) + b \]
\ [y =mx + b \]
Pesos, polarização e ativação
Se pensarmos sobre os valores numéricos entregues à função de ativação de um nó durante o treinamento, os pesos aumentam ou diminuem a inclinação dos dados de entrada e a tendência muda os dados de entrada verticalmente. Mas como isso afeta a saída do nó? Bem, vamos supor que estejamos usando a função logística padrão para ativação:
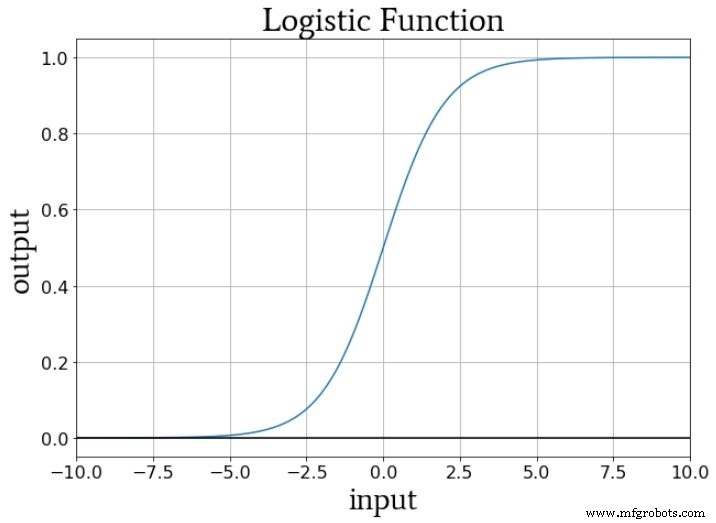
A transição de f A (x) =0 a f A (x) =1 é centrado em um valor de entrada de x =0. Assim, ao usar um viés para aumentar ou diminuir o sinal de pré-ativação, podemos influenciar a ocorrência da transição e, assim, deslocar a função de ativação para a esquerda ou direita . Os pesos, por outro lado, determinam a “rapidez” com que o valor de entrada passa por x =0, e isso influencia a inclinação da transição na função de ativação.
Conclusão
Discutimos os nós de polarização e as características salientes da primeira rede neural que implementaremos no software. Agora estamos prontos para ver o código real e é exatamente o que faremos no próximo artigo.
Robô industrial
- 5 métricas de rede para um mundo em nuvem
- Introdução à arquitetura de rede na nuvem AWS
- Python para loop
- Uma análise da arquitetura NB-IoT para arquitetos de IoT
- Procurando por uma alternativa Z-Wave?
- CEVA:processador AI de segunda geração para cargas de trabalho de rede neural profunda
- A infraestrutura de rede é fundamental para carros sem motorista
- Python - Programação de Rede
- 5 dicas básicas de segurança de rede para pequenas empresas
- Explicador:Por que o 5G é altamente importante para a IoT?