


Como treinar uma rede neural Perceptron multicamadas
Podemos melhorar bastante o desempenho de um Perceptron adicionando uma camada de nós ocultos, mas esses nós ocultos também tornam o treinamento um pouco mais complicado.
Até agora, na série AAC sobre redes neurais, você aprendeu sobre classificação de dados usando redes neurais, especialmente da variedade Perceptron.
Acompanhe a série abaixo ou mergulhe nesta nova entrada que explicará os fundamentos da rede neural multicamadas Perceptron (MLP).
- Como realizar a classificação usando uma rede neural:o que é o Perceptron?
- Como usar um exemplo de rede neural simples Perceptron para classificar dados
- Como treinar uma rede neural Perceptron básica
- Compreendendo o treinamento de rede neural simples
- Uma introdução à teoria de treinamento para redes neurais
- Compreendendo a taxa de aprendizagem em redes neurais
- Aprendizado de máquina avançado com o Multilayer Perceptron
- A função de ativação sigmóide:ativação em redes neurais multicamadas Perceptron
- Como treinar uma rede neural multicamadas Perceptron
- Noções básicas sobre fórmulas de treinamento e retropropagação para percepções multicamadas
- Arquitetura de rede neural para uma implementação Python
- Como criar uma rede neural multicamadas Perceptron em Python
- Processamento de sinais usando redes neurais:validação no projeto de redes neurais
- Conjuntos de dados de treinamento para redes neurais:como treinar e validar uma rede neural Python
O que é uma rede neural multicamadas Perceptron?
O artigo anterior demonstrou que um Perceptron de camada única simplesmente não pode produzir o tipo de desempenho que esperamos de uma arquitetura de rede neural moderna. Um sistema que é limitado a funções linearmente separáveis não será capaz de aproximar as relações complexas de entrada e saída que ocorrem em cenários de processamento de sinal da vida real. A solução é um Perceptron multicamadas (MLP), como este:
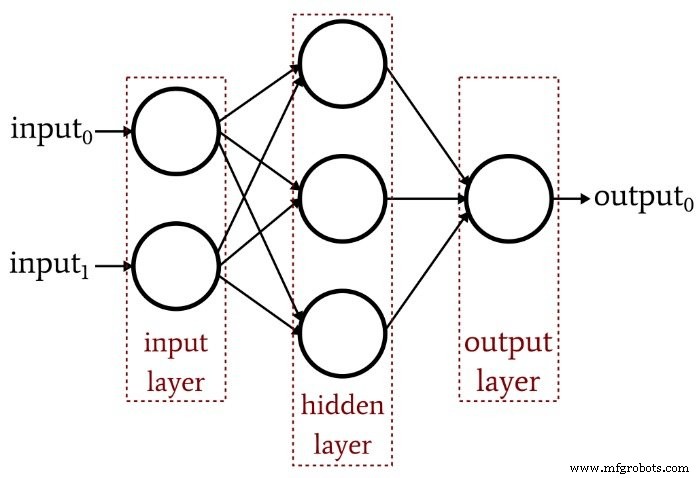
Ao adicionar essa camada oculta, transformamos a rede em um “aproximador universal” que pode alcançar uma classificação extremamente sofisticada. Mas devemos sempre lembrar que o valor de uma rede neural depende totalmente da qualidade de seu treinamento. Sem dados de treinamento abundantes e diversos e um procedimento de treinamento eficaz, a rede nunca “aprenderá” como classificar as amostras de entrada.
Por que a camada oculta complica o treinamento?
Vejamos a regra de aprendizado que usamos para treinar um Perceptron de camada única em um artigo anterior:
\ [w_ {new} =w + (\ alpha \ times (output_ {esperado} -output_ {calculado}) \ times input) \]
Observe a suposição implícita nesta equação:Atualizamos os pesos com base na saída observada, portanto, para que isso funcione, os pesos no Perceptron de camada única devem influenciar diretamente o valor de saída. É como escolher a temperatura da água da torneira girando os dois botões para quente e fria. A relação entre a temperatura geral e a ação dos botões é bastante direta, e mesmo quem não gosta de matemática pode encontrar a temperatura desejada da água mexendo nos botões por um tempo.
Mas agora imagine que o fluxo de água pelos canos quente e frio está relacionado à posição do botão de uma maneira complexa e altamente não linear. Você gira lenta e continuamente o botão para água quente, mas a taxa de fluxo resultante está variando erraticamente. Você experimenta o botão para água fria e faz a mesma coisa. Estabelecer a temperatura ideal da água sob essas condições - especialmente porque a “saída” deve ser alcançada por meio de uma combinação de duas relações de controle confusas - seria muito mais difícil.
É assim que entendo o dilema da camada oculta. Os pesos que conectam os nós de entrada aos nós ocultos são conceitualmente análogos aos botões mecanicamente erráticos - porque os pesos de entrada para ocultos não têm um caminho direto para a camada de saída, a relação entre esses pesos e a saída da rede é tão complexo que a regra de aprendizagem simples mostrada acima não seja eficaz.
Um novo paradigma de treinamento
Como a regra de aprendizado original do Perceptron não pode ser aplicada a redes multicamadas, precisamos repensar nossa estratégia de treinamento. O que vamos fazer é incorporar a descida do gradiente e a minimização de uma função de erro.
Uma coisa a ter em mente é que esse procedimento de treinamento não é específico para redes neurais multicamadas. O gradiente descendente vem da teoria geral de otimização, e o procedimento de treinamento que empregamos para MLPs também se aplica a redes de camada única. No entanto, pelo que entendi, a descida gradiente no estilo MLP é (pelo menos teoricamente) desnecessária para um Perceptron de camada única, porque a regra mais simples mostrada acima acabará por realizar o trabalho.
Derivar as equações reais de atualização de peso para um MLP envolve um pouco de matemática intimidante que não tentarei explicar de forma inteligente neste momento. Meu objetivo para o resto deste artigo é fornecer uma introdução conceitual a dois aspectos principais do treinamento MLP - descida gradiente e a função de erro - e então continuaremos esta discussão no próximo artigo, incorporando uma nova função de ativação.
Gradiente de descida
Como o nome indica, a descida gradiente é um meio de descer em direção ao mínimo de uma função de erro com base na inclinação. O diagrama abaixo mostra a maneira pela qual um gradiente nos fornece informações sobre como modificar os pesos - a inclinação de um ponto na função de erro nos diz em que direção precisamos ir e a que distância estamos do mínimo.
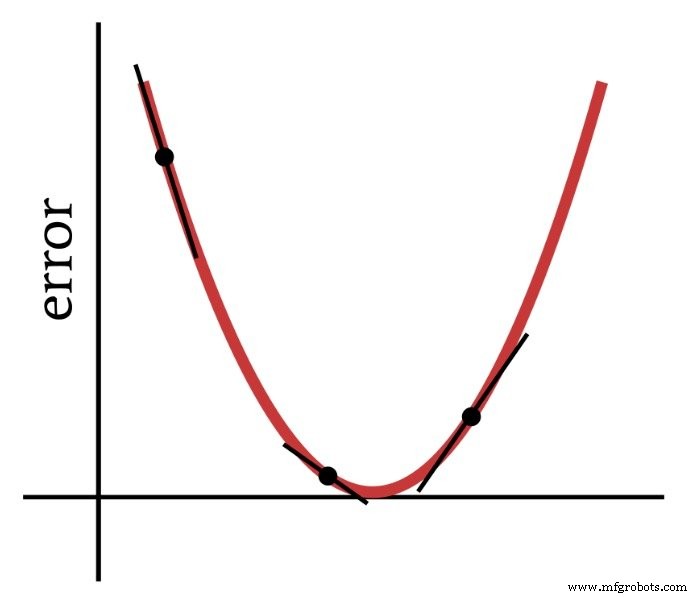
Portanto, a derivada da função de erro é um elemento importante dos cálculos que usamos para treinar um Perceptron multicamadas. Na verdade, precisaremos de parcial derivados aqui. Quando implementamos a descida de gradiente, tornamos cada modificação de peso proporcional à inclinação da função de erro em relação ao peso que está sendo modificado.
A função de erro (também conhecida como função de perda)
Um método comum de quantificar o erro de uma rede neural é elevar ao quadrado a diferença entre o valor esperado (ou "alvo") e o valor calculado para cada nó de saída e, em seguida, somar todas essas diferenças quadradas. Você pode chamar isso de "soma da diferença quadrada" ou "erro quadrático somado" ou talvez várias outras coisas, e você também verá a abreviatura LMS, que significa mínimos quadrados, porque o objetivo do treinamento é minimizar a média erro quadrado. Esta função de erro (denotada por E) pode ser expressa matematicamente da seguinte forma:
\ [E =\ frac {1} {2} \ sum_k (t_k-o_k) ^ 2 \]
onde k indica o intervalo de nós de saída, t é o valor de saída de destino e o é o valor de saída calculado.
Conclusão
Estabelecemos as bases para o treinamento bem-sucedido de um Perceptron multicamadas e continuaremos explorando esse tópico interessante no próximo artigo.
Robô industrial
- Topologia de rede
- Como treinar para se tornar um eletricista automotivo
- Como fortalecer seus dispositivos para evitar ataques cibernéticos
- CEVA:processador AI de segunda geração para cargas de trabalho de rede neural profunda
- Como o ecossistema de rede está mudando o futuro da fazenda
- O que é uma rede inteligente e como ela pode ajudar sua empresa?
- O que é uma chave de segurança de rede? Como encontrar?
- Rede neural artificial pode melhorar a comunicação sem fio
- Quão segura é a sua rede de chão de fábrica?
- Como a indústria 4.0 treina a força de trabalho de amanhã?