


Como treinar um algoritmo para detectar e prevenir a cegueira precoce
Um dispositivo médico portátil capaz de detectar com precisão os diferentes estágios da retinopatia diabética, sem a necessidade de uma conexão com a internet, reduziria muito o número de casos de cegueira por retinopatia em todo o mundo. Com o aprendizado de máquina incorporado, agora é possível desenvolver algoritmos que podem ser executados diretamente em dispositivos médicos alimentados por bateria e realizar detecção ou diagnóstico. Neste artigo, fornecemos um passo a passo das etapas necessárias para treinar rapidamente um algoritmo para fornecer esse recurso usando uma plataforma de software do Edge Impulse.
A retinopatia diabética é uma condição na qual ocorrem danos aos vasos sanguíneos dos tecidos localizados na parte posterior do olho. Pode ocorrer em indivíduos diabéticos e cujo açúcar no sangue é mal administrado. Em casos crônicos extremos, a retinopatia diabética pode levar à cegueira.
Mais de dois em cada cinco americanos com diabetes têm alguma forma de retinopatia diabética. Isso torna crítico pegá-lo cedo, momento em que estilo de vida ou intervenção médica pode ser realizada. Para áreas rurais em todo o mundo onde o acesso aos cuidados com a visão é limitado, os estágios da retinopatia são ainda mais difíceis de detectar mais cedo, antes que o caso se torne grave. Usando a detecção de retinopatia diabética como objetivo, buscamos obter dados médicos disponíveis publicamente e treinar um modelo de aprendizado de máquina no Edge Impulse que pudesse executar inferência diretamente em um dispositivo de borda. Idealmente, o algoritmo seria capaz de avaliar a gravidade da retinopatia diabética entre imagens de olhos tiradas por uma câmera de retina. O conjunto de dados que usamos para este projeto pode ser encontrado aqui.
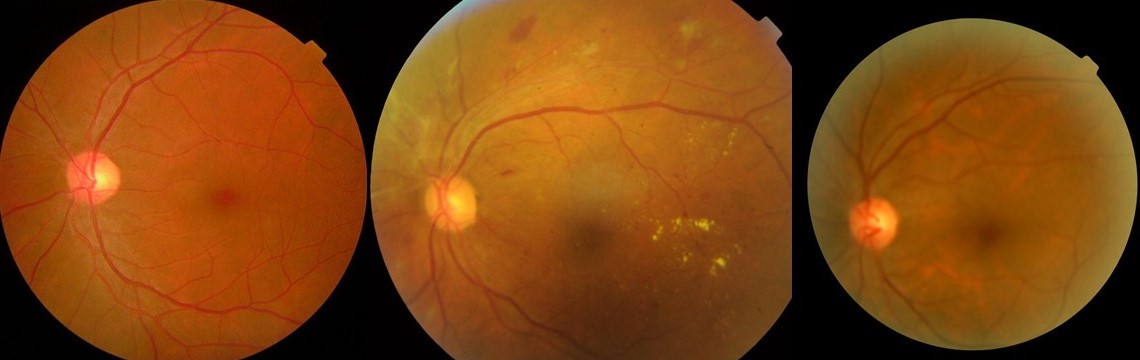
Para este algoritmo, dividimos as classes em cinco conjuntos de dados diferentes:
- Sem retinopatia diabética (Sem DR)
- DR moderado
- DR moderado
- DR grave
- DR proliferativa
Tal como acontece com muitos conjuntos de dados disponíveis publicamente, alguma limpeza e rotulagem de dados tiveram que ser feitas.
Para proteger as identidades dos pacientes, cada imagem no conjunto de dados recebeu simplesmente um id_code e um diagnóstico de 0 a 5, sendo 0 a gravidade mais baixa de Sem DR e 5 a pior, ou DR proliferativa.
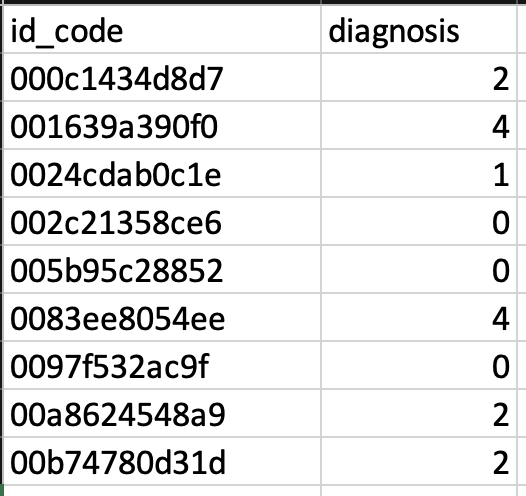
Para inserir os dados no Edge Impulse, algum particionamento das imagens precisava ocorrer. Dada a natureza simples de como os dados foram divididos, decidi escrever um script VBA para ler a imagem id_code do Excel, pegar a imagem associada e colocá-la em sua respectiva pasta. O script para mover esses arquivos está vinculado aqui. Para aqueles com melhores habilidades em Python ou outras linguagens de script, há muitas maneiras de fazer isso que podem ser até mais simples.
O Edge Impulse tem outros recursos de ingestão de dados, como integração de repositório de dados em nuvem ou coleta de dados de dispositivos, mas o upload de dados foi o método que utilizei aqui. Usando a opção de upload de dados, consegui trazer em minhas 5 classes diferentes uma série de cinco uploads. Cada upload consistia em eu rotular os dados como uma das 5 classes e enviar as imagens associadas contidas em cada pasta.
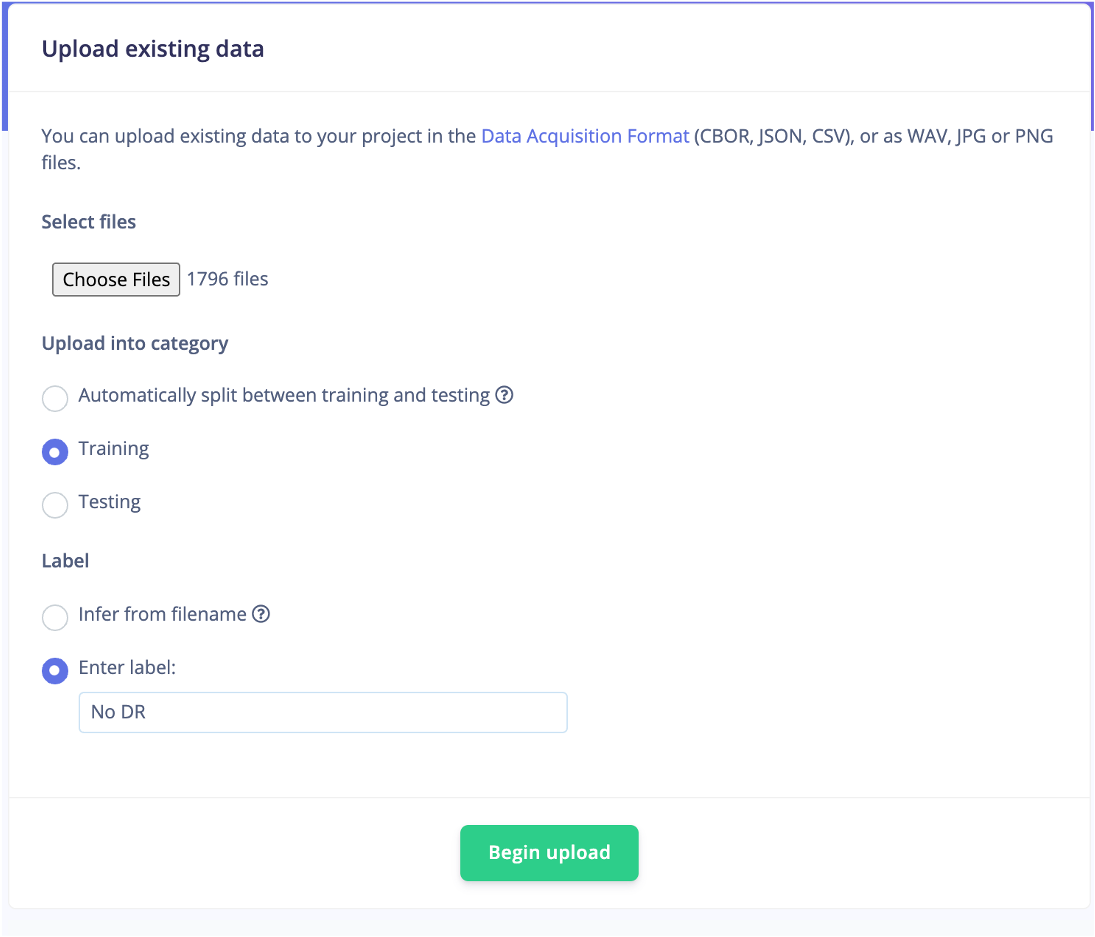
O Edge Impulse tem a opção de dividir automaticamente os dados em dados de treinamento ou teste com uma divisão 80/20. No entanto, adicionei manualmente cerca de 500 imagens em diferentes classes ao conjunto de dados de teste.
Em seguida, era hora de configurar meu modelo e escolher o bloco de processamento de sinal e o bloco de rede neural para este modelo. Para este modelo, alimentei o bloco de imagem em um bloco de aprendizagem de transferência com o objetivo de diferenciar entre cinco classes diferentes.
A partir daqui, fui treinar a rede neural. Brincando com as configurações da rede neural, a melhor precisão que consegui foi em torno de 74%. Não é ruim, mas o modelo estava travando quando se tratava de alguns dos casos extremos. Por exemplo, a RD grave às vezes era classificada como RD leve. O modelo não era muito preciso conforme o DR progredia, como você pode ver na captura de tela abaixo.
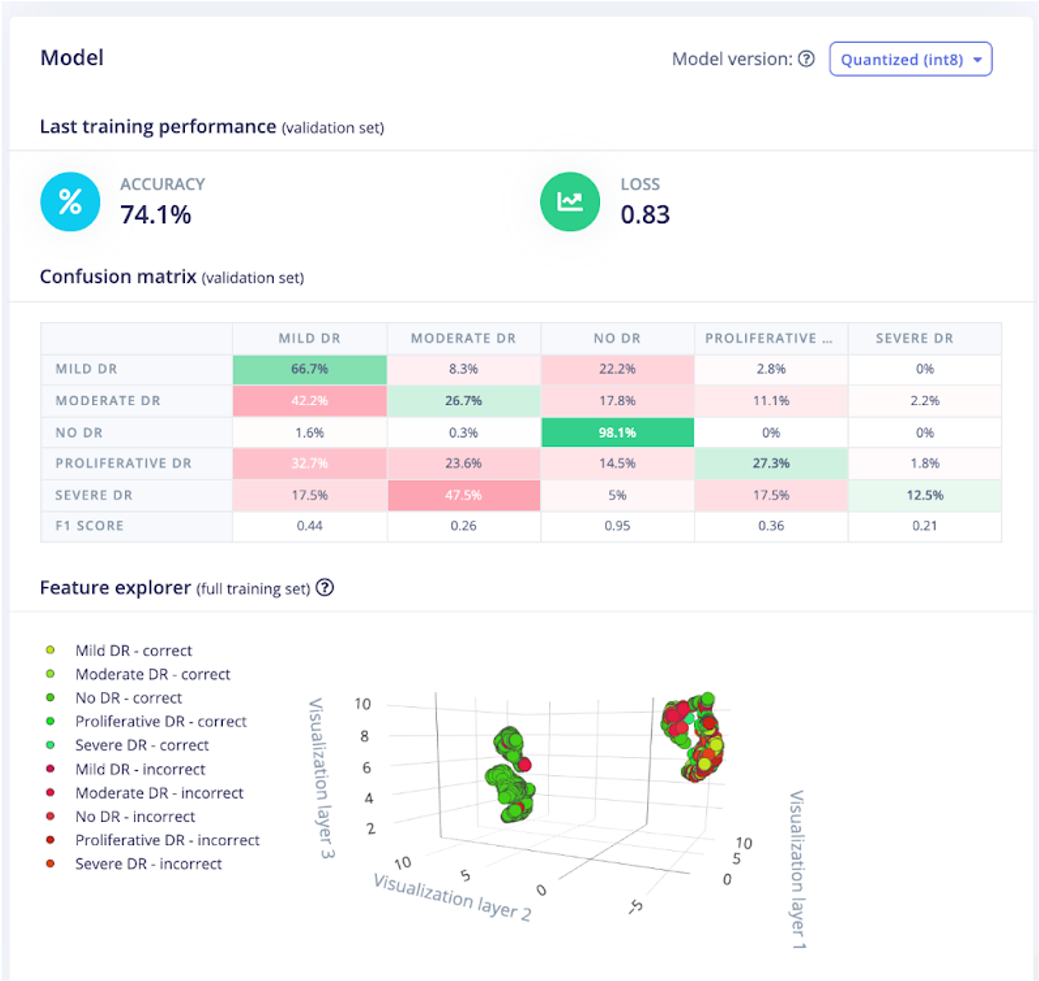
Isso me fez pensar sobre as aplicações da vida real de um projeto como este e se esse nível de precisão seria aceitável. Idealmente, algum tipo de câmera de imagem retinal portátil (em um ambiente de baixa conectividade sem fio) poderia executar um algoritmo como este no próprio dispositivo. Quando a foto é tirada, processada e o resultado é gerado, a pessoa que está aplicando o exame oftalmológico pode dizer ao paciente que ele precisa procurar ajuda ou intervenção médica adicional, dependendo do resultado.
Para esta aplicação, é mais importante capturar a RD em todos os estágios para que o paciente possa iniciar algum tratamento preventivo ou, para casos mais graves, procurar ajuda médica imediata. Dado este caso de uso, o modelo realmente atende sua aplicação potencial relativamente bem.
Pensando bem, existem algumas mudanças ou melhorias que eu poderia fazer no modelo, que podem tornar a saída resultante mais precisa em termos de diagnóstico da gravidade de DR:
- Mais dados é sempre melhor. No entanto, dado este conjunto de dados limitado, seria necessária mais coleta de dados.
- Uma ideia poderia ser combinar classes, criando uma classe leve - moderada e uma classe proliferativa - severa. Eu me pergunto se isso pode ajudar o algoritmo a classificar melhor, dadas as semelhanças entre certos casos de DR leve e moderado, que agora cairiam todos no mesmo grupo.
Brinque com o número de camadas dentro da rede neural (NN), bem como com o dropout.

Do ponto de vista da implantação, este modelo treinado ocupava uma área maior em termos de memória, ocupando cerca de 306kB de Flash e 236kB de RAM. Dependendo do dispositivo selecionado para executar a inferência, a quantidade de tempo necessária para que um resultado de inferência seja fornecido de volta foi de 0,8 segundos a 6 segundos, ao fazer o benchmarking em um Cortex-M4 a 80 MHz ou Cortex-M7 a 216 MHz. Dado que este produto final precisaria de imagens, no entanto, prevejo que algo como os recursos de processamento do Cortex-M7 ou superior seria necessário.
Em resumo, usando um conjunto de dados de código aberto, fomos capazes de treinar um modelo de aprendizado de máquina relativamente funcional para detectar várias formas de retinopatia diabética (RD). O objetivo final seria implantar modelos como este diretamente no microcontrolador embutido ou dispositivo Linux e fazer com que mais dispositivos médicos como o mostrado abaixo executassem inferência na extremidade. Isso abre novas possibilidades para os serviços de saúde, ao fornecer tecnologia médica que pode ser usada em áreas rurais, sem conectividade sem fio para fornecer testes a populações com baixo acesso aos cuidados de saúde.
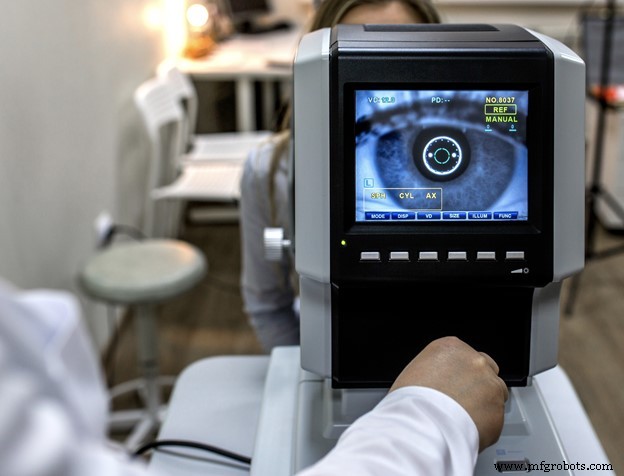
De fato, há uma boa oportunidade para a implantação de aprendizado de máquina incorporado (ML) em dispositivos médicos. Mais detalhes sobre este projeto, incluindo potencial de melhoria adicional, estão disponíveis aqui.
Projeto de exploração confiável e fluxo de verificação para segurança de IoT
O XANDAR visa a geração de código em design multi-core de segurança crítica
Integrado
- Como o titânio foi descoberto e usado por humanos?
- Nuvem e como ela está mudando o mundo da TI
- Quatro tipos de ataques cibernéticos e como evitá-los
- Como evitar problemas comuns de máquinas e equipamentos pesados
- O que é porosidade de soldagem e como evitá-la?
- O que é ferrugem e como evitar ferrugem? Um guia completo
- Principais causas de falha de máquina e como evitá-las
- O que é interoperabilidade e como minha empresa pode alcançá-la?
- Armadilhas de proteção de máquina e como evitá-las
- Como detectar vazamentos e corrigi-los