


Data Lake vs. Big Data para aplicações industriais
Lago de dados e big data são dois termos modernos muitas vezes mal interpretados e usados incorretamente. Devido aos grandes volumes de dados implícitos, esses termos às vezes são usados indistintamente. No entanto, data lake e big data são diferentes, embora suas definições atuais ainda não estejam totalmente estabelecidas.

Figura 1. Os dados modernos podem vir de muitas fontes e ser de tipos diferentes. Imagem usada cortesia de Analytics Vidhya
Vejamos primeiro um breve contexto histórico. No final dos anos 2000, com o crescimento explosivo das plataformas de mídia social, como Facebook e Twitter, muitos cientistas de dados começaram a perceber o potencial de tais plataformas para gerar grandes quantidades de dados pessoais valiosos. Consequentemente, novos aplicativos de software foram desenvolvidos para facilitar o processamento e a análise de dados. Um exemplo proeminente é o Apache Hadoop, essencialmente um kit de ferramentas de aplicativos de código aberto que podem processar níveis de informações de big data.
Na década seguinte, a Internet das Coisas (IoT) entrou em cena. Isso abriu as portas para milhões de outras fontes de dados que poderiam fornecer insights sobre as preferências e padrões de uma pessoa, ao mesmo tempo que enviavam informações sobre o próprio produto.
Simultaneamente, o aprendizado de máquina estava fazendo avanços importantes e encontrando aplicações mais práticas no cenário industrial. Isso resultou em uma maior necessidade de lidar com grandes volumes de dados nas indústrias, especialmente em processos automatizados.
Todas as projeções indicam que a quantidade total de dados disponíveis no mundo continuará a se expandir a taxas aceleradas nos próximos anos. Para referência, em 2016, o mundo ultrapassou a marca de 1 Zetabyte de tráfego anual de internet gerado. Um Zetabyte equivale a 1 trilhão de Gigabytes.
O tráfego anual da Internet deve ultrapassar 3 zetabytes em 2021. Essas projeções, junto com os recursos expandidos da computação em nuvem, indicam que o valor e os usos de big data (e data lakes) talvez estejam apenas começando.
O que é Big Data?
Quando olhamos simplesmente da perspectiva do volume, a definição de big data é um alvo móvel. Conforme a quantidade de dados e espaço de armazenamento disponível continua a crescer, o mesmo acontece com o benchmark do que é considerado uma grande quantidade de informações.
Hoje, um repositório de dados de 100 Terabytes ou mais é geralmente considerado na faixa de big data. Grandes repositórios de dados, como aqueles de plataformas de mídia social, podem estar na faixa de vários Petabytes.
Outra referência usada para definir big data é quando a quantidade de informações não pode ser tratada por ferramentas de computador tradicionais, como SQL. Por exemplo, hoje, não é incomum que os bancos de dados alcancem 1 Terabyte de tamanho anualmente. Mas, com os aplicativos SQL se tornando mais poderosos, essa magnitude do banco de dados ainda pode ser gerenciada; portanto, eles normalmente não são considerados big data.
Modelo 4V de Big Data
Até agora, examinamos a definição de big data da perspectiva do volume. Existem três outros fatores importantes a serem considerados:velocidade, variedade e veracidade. Estes, juntamente com o volume, formam o modelo 4V.
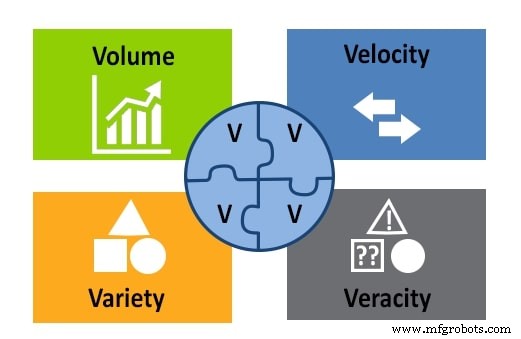
Figura 2. O modelo 4V de big data:volume, velocidade, variedade e veracidade. Imagem usada cortesia de APSense
Variedade se refere a todos os diferentes tipos de dados armazenados em um repositório de big data:texto, imagens, som, vídeo, etc. Também se refere ao fato de que os dados podem vir de várias fontes.
A velocidade é uma consideração importante no big data porque as informações estão constantemente fluindo. A velocidade está relacionada à velocidade com que os dados são coletados, gerados e distribuídos.
A veracidade mede a precisão e a qualidade dos dados para avaliar se um cientista de dados pode usá-los para análise e para tirar conclusões a partir deles.
Agora que entendemos o big data, vamos revisar os data lakes antes de nos aprofundarmos em como usá-los em um sistema de controle.
O que é um Data Lake?
Data lakes são repositórios centralizados de grandes quantidades de dados brutos, que são informações que podem ou não ser valiosas no futuro e cuja finalidade ainda não é 100% conhecida. Data lakes podem armazenar bancos de dados relacionais e não relacionais, junto com outros tipos de arquivos e entidades.
Embora as informações em um data lake não sejam processadas ou organizadas, elas são estruturadas de forma que todas as entradas e saídas sejam consideradas para criar uma boa arquitetura.
Data Lake vs. Big Data
Um data lake é uma instância de um aplicativo de big data. Eles seguem os critérios descritos no modelo 4V, com algumas particularidades adicionais. Em termos de volume, os data lakes estão, em média, perto da extremidade inferior do que é considerado big data.
As informações em lagos de dados têm variedade, mas a condição é que sejam apenas dados brutos não processados. As velocidades de entrada e saída são tão relevantes quanto qualquer sistema moderno e as avaliações da qualidade dos dados são realizadas em um data lake bem projetado.
Aplicações industriais para dados
A automação avançada está gerando um rápido aumento na quantidade de informações tratadas no chão de fábrica. Graças a isso, a manufatura e outros processos industriais estão agora entrando no domínio do big data, com várias atividades de negócios agora empregando ferramentas como data lakes.
Um exemplo importante é a manutenção preditiva. A capacidade de prever uma falha mecânica ou elétrica é muito valiosa e pode proporcionar economias substanciais nos custos de reparo. Data lakes são ferramentas úteis que podem compilar informações provenientes de arquivos de log, vários sensores e dispositivos de entrada, que podem ser usados para entender tendências e prever problemas.
O aprendizado de máquina é um conceito no qual os robôs recebem informações que podem ajudá-los a se adaptar às mudanças nas condições externas. A captura de informações é semelhante à manutenção preditiva, com a etapa adicional que as avaliações e alterações no processo são alimentadas automaticamente para o controlador do sistema. Os dados de aprendizado de máquina podem ser armazenados em um data lake estruturado.
Figura 3. O aprendizado de máquina tem várias estratégias, cada uma das quais requer grandes quantidades de dados. Imagem usada cortesia de WordStream
Para concluir, um data lake é uma instância de um aplicativo de big data. Essas duas maneiras de visualizar dados podem funcionar juntas. Ao utilizar big data e data lake, um engenheiro de controle pode prever falhas, criar rotinas de manutenção, aumentar a transformação digital da instalação e muito mais.
Para que você usa big data e data lakes em seu trabalho?
Compreendendo a dinâmica dos fluidos computacionais (CFD)
Uma abordagem de software para calcular o tempo médio de reparo (MTTR) e o tempo médio entre falhas (MTBF)
Tecnologia da Internet das Coisas
- Sensores e processadores convergem para aplicações industriais
- Cervoz:escolhendo o armazenamento flash certo para aplicações industriais
- GE apresenta serviço em nuvem para dados industriais, Analytics
- Perspectivas para o desenvolvimento de IoT Industrial
- Quatro grandes desafios para a Internet das Coisas industrial
- Seis fundamentos para aplicativos bem-sucedidos informados por sensores
- Como entender big data:RTUs e aplicativos de controle de processo
- Preparando o cenário para o sucesso da ciência de dados industriais
- Para uma percepção real da Internet industrial:não apenas capture dados, use-os
- O Big Data fornecerá uma cura para tudo para orçamentos de saúde enfermos?