


Como Criar uma Rede Neural Perceptron Multicamadas em Python
Este artigo o conduz passo a passo por um programa Python que nos permitirá treinar uma rede neural e realizar classificações avançadas.
Esta é a 12ª entrada na série de desenvolvimento de rede neural da AAC. Veja o que mais a série oferece abaixo:
- Como realizar a classificação usando uma rede neural:o que é o Perceptron?
- Como usar um exemplo de rede neural simples Perceptron para classificar dados
- Como treinar uma rede neural Perceptron básica
- Compreendendo o treinamento de rede neural simples
- Uma introdução à teoria de treinamento para redes neurais
- Compreendendo a taxa de aprendizagem em redes neurais
- Aprendizado de máquina avançado com o Multilayer Perceptron
- A função de ativação sigmóide:ativação em redes neurais multicamadas Perceptron
- Como treinar uma rede neural multicamadas Perceptron
- Noções básicas sobre fórmulas de treinamento e retropropagação para percepções multicamadas
- Arquitetura de rede neural para uma implementação Python
- Como criar uma rede neural multicamadas Perceptron em Python
- Processamento de sinais usando redes neurais:validação no projeto de redes neurais
- Conjuntos de dados de treinamento para redes neurais:como treinar e validar uma rede neural Python
Neste artigo, vamos pegar o trabalho que fizemos em redes neurais Perceptron e aprender como implementar uma em uma linguagem familiar:Python.
Desenvolvimento de código Python compreensível para redes neurais
Recentemente, observei alguns recursos online para redes neurais e, embora haja, sem dúvida, muitas informações boas por aí, não fiquei satisfeito com as implementações de software que encontrei. Eles sempre foram muito complexos, ou muito densos, ou não suficientemente intuitivos. Quando eu estava escrevendo minha rede neural Python, eu realmente queria fazer algo que pudesse ajudar as pessoas a aprender como o sistema funciona e como a teoria da rede neural é traduzida em instruções de programa.
No entanto, às vezes há uma relação inversa entre a clareza do código e a eficiência do código. O programa que discutiremos neste artigo definitivamente não otimizado para desempenho rápido. A otimização é um problema sério no domínio das redes neurais; os aplicativos da vida real podem exigir uma quantidade imensa de treinamento e, conseqüentemente, a otimização completa pode levar a reduções significativas no tempo de processamento. No entanto, para experimentos simples como os que faremos, o treinamento não leva muito tempo, e não há razão para se estressar com as práticas de codificação que favorecem a simplicidade e a compreensão sobre a velocidade.
Todo o programa Python está incluído como uma imagem no final deste artigo, e o arquivo (“MLP_v1.py”) é fornecido para download. O código executa o treinamento e a validação; este artigo se concentra no treinamento e discutiremos a validação mais tarde. Em qualquer caso, porém, não há muitas funcionalidades na parte de validação que não sejam abordadas na parte de treinamento.
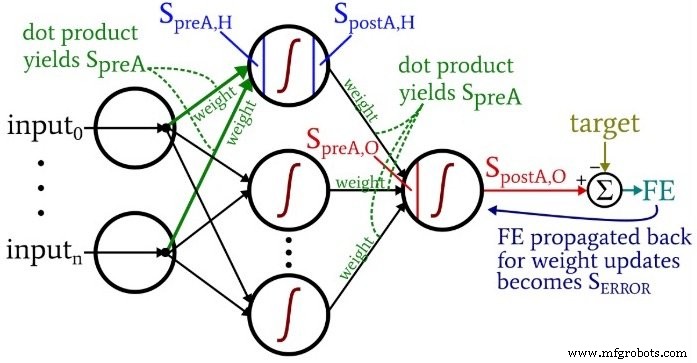
À medida que você está ponderando sobre o código, você pode querer olhar para trás, para o diagrama de arquitetura e terminologia um pouco opressor, mas altamente informativo, que forneci na Parte 10.
Preparando funções e variáveis
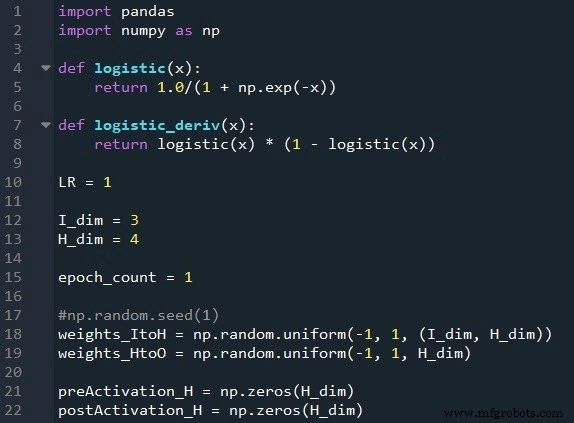
A biblioteca NumPy é usada extensivamente para os cálculos da rede, e a biblioteca Pandas me oferece uma maneira conveniente de importar dados de treinamento de um arquivo Excel.
Como você já sabe, estamos usando a função sigmóide logística para ativação. Precisamos da própria função logística para calcular os valores de pós-ativação, e a derivada da função logística é necessária para a retropropagação.
Em seguida, escolhemos a taxa de aprendizado, a dimensionalidade da camada de entrada, a dimensionalidade da camada oculta e a contagem de épocas. O treinamento em vários períodos é importante para redes neurais reais, pois permite que você extraia mais aprendizado de seus dados de treinamento. Ao gerar dados de treinamento no Excel, você não precisa executar várias épocas porque pode criar facilmente mais amostras de treinamento.
O np.random.uniform () função preenche nossas duas matrizes de peso com valores aleatórios entre -1 e +1. (Observe que a matriz oculta para a saída é na verdade apenas um array, porque temos apenas um nó de saída.) O np.random.seed (1) declaração faz com que os valores aleatórios sejam os mesmos toda vez que você executa o programa. Os valores de peso iniciais podem ter um efeito significativo no desempenho final da rede treinada, portanto, se você estiver tentando avaliar como outros variáveis melhoram ou degradam o desempenho, você pode descomentar esta instrução e, assim, eliminar a influência da inicialização de peso aleatório.
Por fim, crio matrizes vazias para os valores de pré e pós-ativação na camada oculta.
Importando dados de treinamento

Este é o mesmo procedimento que usei na Parte 4. Eu importo dados de treinamento do Excel, separo os valores alvo na coluna "saída", removo a coluna "saída", converto os dados de treinamento em uma matriz NumPy e armazeno o número de amostras de treinamento em training_count variável.
Processamento de feedforward
Os cálculos que produzem um valor de saída, e nos quais os dados estão se movendo da esquerda para a direita em um diagrama de rede neural típico, constituem a parte "feedforward" da operação do sistema. Aqui está o código do feedforward:
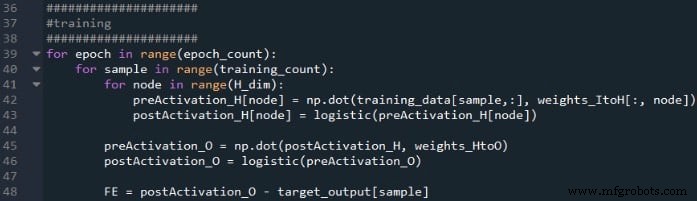
O primeiro loop for nos permite ter várias épocas. Dentro de cada época, calculamos um valor de saída (ou seja, o sinal de pós-ativação do nó de saída) para cada amostra e essa operação amostra por amostra é capturada pelo segundo loop for. No terceiro for loop, atendemos individualmente a cada nó oculto, usando o produto escalar para gerar o sinal de pré-ativação e a função de ativação para gerar o sinal de pós-ativação.
Depois disso, estamos prontos para calcular o sinal de pré-ativação para o nó de saída (novamente usando o produto escalar) e aplicamos a função de ativação para gerar o sinal de pós-ativação. Em seguida, subtraímos o alvo do sinal de pós-ativação do nó de saída para calcular o erro final.
Retropropagação
Depois de realizar os cálculos do feedforward, é hora de inverter as direções. Na parte de retropropagação do programa, passamos do nó de saída em direção aos pesos ocultos para a saída e, em seguida, para os pesos de entrada para ocultos, trazendo conosco as informações de erro que usamos para treinar efetivamente a rede.

Temos duas camadas de loops for aqui:uma para os pesos ocultos para a saída e outra para os pesos de entrada para os ocultos. Primeiro geramos S ERROR , que precisamos para calcular o gradiente HtoO e gradiente ItoH , e então atualizamos os pesos subtraindo o gradiente multiplicado pela taxa de aprendizagem.
Observe como os pesos de entrada para ocultos são atualizados em o loop oculto para saída. Começamos com o sinal de erro que leva de volta a um dos nós ocultos e, em seguida, estendemos esse sinal de erro a todos os nós de entrada que estão conectados a este nó oculto:
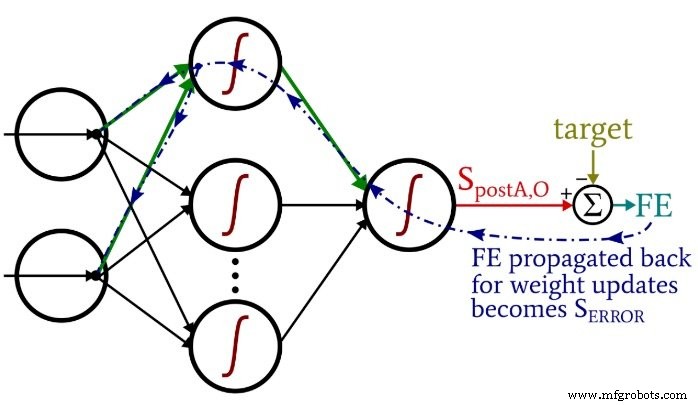
Depois que todos os pesos (ItoH e HtoO) associados a esse nó oculto foram atualizados, fazemos um loop de volta e começamos novamente com o próximo nó oculto.
Observe também que os pesos ItoH são modificados antes dos pesos HtoO. Usamos o peso HtoO atual quando calculamos o gradiente ItoH , portanto, não queremos alterar os pesos HtoO antes que este cálculo seja executado.
Conclusão
É interessante pensar sobre quanta teoria foi aplicada neste programa Python relativamente curto. Espero que este código ajude você a realmente entender como podemos implementar uma rede neural Perceptron multicamadas em software.
Você pode encontrar meu código completo abaixo:
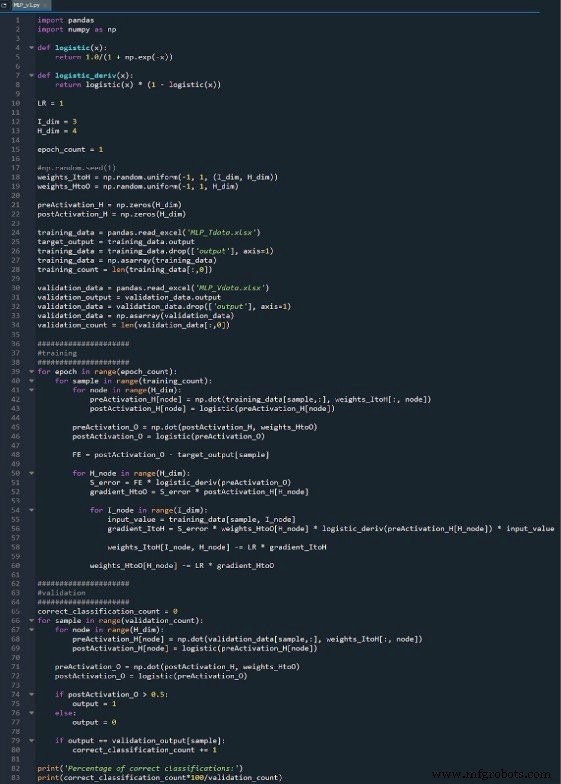
Baixar código
Robô industrial
- Como criar um modelo CloudFormation usando AWS
- Como criar um centro de excelência em nuvem?
- Como criar UX sem Fricção
- Como criar uma lista de strings em VHDL
- Como criar um testbench de autoverificação
- Como criar um temporizador em VHDL
- Como criar um processo cronometrado em VHDL
- Compreendendo os mínimos locais no treinamento de rede neural
- Como criar uma matriz de objetos em Java
- Python - Programação de Rede