


Dominar os desafios da programação e depuração multicore
Neste artigo, iremos discutir vários aspectos do processamento multicore, incluindo uma olhada em diferentes tipos de processadores multicore e por que esses dispositivos estão se tornando comuns e populares hoje em dia. Em seguida, examinaremos alguns dos desafios introduzidos por ter mais de um núcleo em um chip e como os depuradores modernos com reconhecimento de múltiplos núcleos podem ajudar a tornar essas tarefas complexas mais gerenciáveis.
Desempenho de sistemas
Existem muitas maneiras de aumentar o desempenho de um sistema de computação embarcado, desde algoritmos de compilador inteligentes até soluções de hardware eficientes. As otimizações do compilador são importantes para obter o agendamento de instrução mais eficiente a partir de código de linguagem de alto nível que seja fácil de ler e entender. Além disso, os sistemas podem aproveitar o paralelismo disponível no projeto para processar mais de uma coisa por vez. E, claro, dimensionar a frequência do clock pode ser uma maneira eficaz de obter mais desempenho do seu sistema de computação.
Infelizmente, já se passaram os dias em que se podia presumir que a velocidade do relógio aumentava geometricamente. E a otimização de código só pode trazer melhorias, principalmente agora, depois de muitas gerações de desenvolvimento de tecnologia de compilador. Isso nos deixa ver o paralelismo como a melhor oportunidade para continuar a dimensionar o desempenho do nosso sistema com o passar do tempo.
Paralelismo

Cavar um poço é uma tarefa difícil de paralelizar. Outros podem ajudar, removendo a sujeira com uma pá, mas a verdadeira escavação no buraco é normalmente um trabalho para uma única pessoa. Como resultado, adicionar mais pessoas ao buraco não fará o trabalho mais rápido. Na verdade, os outros podem apenas atrapalhar e retardar o processo. Algumas tarefas não são adequadas para paralelização.
Outras tarefas são facilmente paralelizadas. Cavar uma vala é uma tarefa adequada para paralelização. Muitas pessoas podem trabalhar lado a lado.

Esta imagem mostra uma forma de paralelismo chamada MIMD, Multiple Instruction Multiple Data. Cada escavadeira é uma unidade separada e pode realizar tarefas diferentes. Neste caso, você pode imaginar que quatro escavadores podem fazer o trabalho em cerca de 1/4
th
o tempo de um único escavador.
Com SIMD, Single Instruction Multiple Data, um único escavador pode usar uma pá como esta.
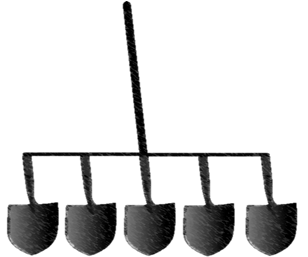
A unidade SIMD pode fazer apenas um tipo de cálculo por vez, mas pode executá-lo em várias partes de dados em paralelo. Esses tipos de instruções são comuns em unidades de processamento vetorial de muitos processadores. Isso é útil se seus dados são muito regulares e você precisa fazer as mesmas operações continuamente em um grande conjunto de dados, como no processamento de imagens. No entanto, para tarefas de computação mais gerais, este modelo carece de flexibilidade e não produzirá ganhos de desempenho.
Isso nos leva à escolha de colocar vários subsistemas de CPU completos em um único chip, criando processadores com vários núcleos. Vários núcleos em um chip podem aumentar o desempenho. Cada núcleo é uma CPU completa e pode funcionar independentemente ou em conjunto com outros núcleos.
Diferentes tipos de processamento multicore
Existem diferentes combinações de tipos de núcleos que você pode ter em um chip do processador, bem como a forma como o trabalho é distribuído entre eles.
Os processadores multicore homogêneos têm duas ou mais cópias do mesmo núcleo do processador. Cada núcleo é executado de forma autônoma e pode se comunicar e sincronizar com outros núcleos por meio de vários mecanismos, como memória compartilhada ou sistemas de caixa de correio. Cada processador tem seus próprios registradores e unidades de função, e pode ter sua própria memória local ou cache. No entanto, o que torna isso homogêneo é o fato de que todos os núcleos que estamos olhando são do mesmo tipo.
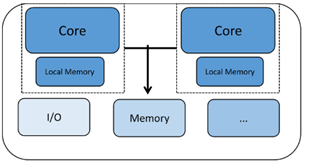
Outro tipo de chip de núcleo múltiplo é conhecido como multicore heterogêneo com dois ou mais tipos diferentes de núcleos de CPU. Aqui, os núcleos podem ter características muito diferentes que os tornam adequados para diferentes partes das necessidades de processamento do sistema. Um exemplo pode ser um chip de comunicação Bluetooth onde um núcleo é dedicado a gerenciar a pilha de protocolo Bluetooth enquanto o outro núcleo pode gerenciar comunicações externas, processamento de aplicativos, a interface humana, etc. Este tipo de chip de núcleo múltiplo pode ser usado para aplicativos que precisam de ambos desempenho dedicado em tempo real em um núcleo e recursos de gerenciamento de sistema no outro.
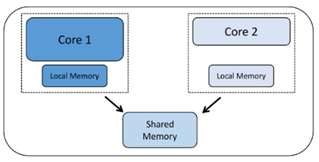
Agora veremos como os núcleos são usados. O multiprocessamento simétrico (SMP) acontece quando você tem mais de um núcleo e os núcleos executam a mesma base de código do projeto. Diferentes núcleos podem estar executando diferentes partes do código ao mesmo tempo, mas o código é construído como um único projeto e é despachado para os núcleos separados por algum programa de controle como um sistema operacional em tempo real (RTOS). Por necessidade, os núcleos que funcionam dessa forma devem ser do mesmo tipo, pois todos usam o mesmo código de projeto compilado para um tipo de processador.
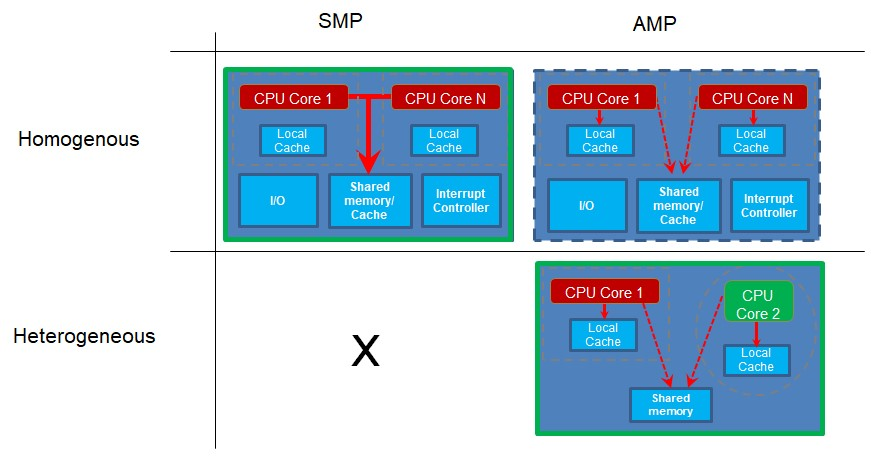
O multiprocessamento assimétrico (AMP) ocorre quando você tem mais de um núcleo ou processador e cada processador está executando seu próprio aplicativo de projeto. Os núcleos separados podem sincronizar ou comunicar de vez em quando, mas cada um tem sua própria base de código que executa. Como cada um está executando seu próprio projeto, esses núcleos podem ser de tipos diferentes ou núcleos heterogêneos. No entanto, isso não é um requisito. Se dois ou mais núcleos do mesmo tipo executam códigos de projeto diferentes, eles são núcleos homogêneos, executando AMP.
Observe que, para a operação do SMP, você deve ter vários núcleos homogêneos, uma vez que todos eles executam código a partir da mesma base de código de projeto único. No entanto, se você tiver vários projetos com diferentes bases de código para os diferentes núcleos executar, eles podem ser núcleos diferentes, como em um sistema heterogêneo. No entanto, se os núcleos forem iguais, também funciona.
Razões para usar multicore
Ao longo dos últimos anos, a lei de Moore, cunhada em meados dos anos 1960, finalmente parece estar perdendo força, ou pelo menos desacelerando. As taxas de clock do processador não dobram mais a cada 2-3 anos e, de fato, as CPUs de velocidade mais alta atingiram um teto na faixa baixa de GHz de um dígito por muitos anos.
Uma maneira de continuar empurrando o envelope de desempenho é ter mais núcleos de CPU trabalhando juntos, se você puder usá-los com eficiência.
Embora as velocidades tenham se estabilizado, o tamanho do transistor continuou a diminuir. Embora mais lentos do que no passado, os pequenos transistores permitem o empacotamento de mais lógica em um único chip. Como resultado, usar esses transistores para colocar vários núcleos de CPU em um único chip pode tirar proveito de interconexões de barramento muito mais rápidas e mais amplas entre os vários subsistemas de CPU e memória.
O multiprocessamento assimétrico heterogêneo é muito útil quando um aplicativo tem duas ou mais cargas de trabalho com características e requisitos muito diferentes. Um pode ser em tempo real e dependente da latência de interrupção, enquanto o outro pode ser mais dependente do rendimento do que do tempo de resposta. Este modelo funciona muito bem:por exemplo, um dispositivo pode dedicar um núcleo para gerenciar uma pilha de protocolo de comunicação como Bluetooth ou Zigbee, enquanto outro núcleo atua como um processador de aplicativo executando interações humanas e operações gerais de gerenciamento do sistema. O processador de comunicações, sendo isolado, pode fornecer excelente resposta em tempo real necessária para a pilha de protocolo. Além disso, o software de comunicação pode ser certificado de acordo com um padrão, facilitando a certificação de todo o produto, mantendo as modificações funcionais separadas dessa parte do sistema.
Desafios usando multicore
Que tipos de desafios são introduzidos quando você coloca mais de um núcleo da CPU em um chip? Bem, vamos aprofundar.
Um aplicativo ou software monolítico pode não ser capaz de usar os recursos de computação disponíveis de forma eficiente. Você precisa organizar o aplicativo em tarefas paralelas que podem ser executadas ao mesmo tempo para usar recursos de mais de um núcleo. Isso pode exigir uma maneira desconhecida de os engenheiros de software pensarem em design embarcado. Migrar o código de loop único existente pode não ser muito fácil. Poucos threads ou mesmo muitos threads podem se tornar barreiras de desempenho.
Os aplicativos que compartilham estruturas de dados ou dispositivos de E / S entre vários threads ou processos podem ter gargalos seriais. Para manter a integridade dos dados, o acesso a esses recursos compartilhados pode ter que ser serializado usando técnicas de bloqueio, por exemplo, bloqueio de leitura, bloqueio de leitura e gravação, bloqueio de gravação, spinlock, mutex e assim por diante. Os bloqueios projetados de forma ineficiente podem criar gargalos devido a contenções de alta bloqueio entre vários threads ou processos que tentam adquirir o bloqueio para usar um recurso compartilhado. Isso pode degradar potencialmente o desempenho do aplicativo ou software. O desempenho de um aplicativo pode até mesmo degradar à medida que o número de núcleos ou processadores aumenta se alguns núcleos estão paralisando outros esperando por bloqueios comuns, fazendo com que dois núcleos tenham um desempenho pior do que um.
Uma carga de trabalho distribuída desigualmente pode ser ineficiente na utilização de recursos de computação. Você pode ter que dividir tarefas grandes em tarefas menores que podem ser executadas em paralelo. Você pode ter que mudar algoritmos seriais para paralelos para melhorar o desempenho e escalabilidade. No entanto, se algumas tarefas forem executadas muito rapidamente e outras demorarem muito, as tarefas rápidas podem gastar uma quantidade significativa de tempo esperando que as tarefas longas sejam concluídas. Isso resulta em valiosos recursos de computação inativos e baixo escalonamento de desempenho.
Um RTOS provavelmente irá ajudá-lo, mas pode não resolver tudo. Em um sistema SMP, isso é praticamente obrigatório para agendar tarefas em vários núcleos semelhantes. O trabalho a ser realizado pode ser dividido por dados ou por função. Se você dividir as coisas por blocos de dados, cada thread pode realizar todas as etapas em um pipeline de processamento. Como alternativa, você pode fazer com que um thread execute uma etapa da função, enquanto outro executa a próxima etapa, etc. As vantagens de uma técnica sobre a outra dependerão das características do trabalho a ser feito.
Depuração em ambientes multicore
A primeira coisa que é útil ao depurar um sistema multicore é a visibilidade de todos os núcleos. Idealmente, devemos ser capazes de iniciar e interromper os núcleos simultaneamente ou individualmente - ou seja, dar uma única etapa em um núcleo enquanto os outros estão em execução ou parados. Os pontos de interrupção multicore podem ser muito úteis para controlar a operação de um núcleo baseado no estado de outro.
O rastreamento multicore pode ser muito difícil de implementar. Gerenciar a alta largura de banda de informações de rastreamento de vários núcleos, bem como lidar com tipos potencialmente diferentes de dados de rastreamento de diferentes tipos de núcleos, é um verdadeiro desafio.
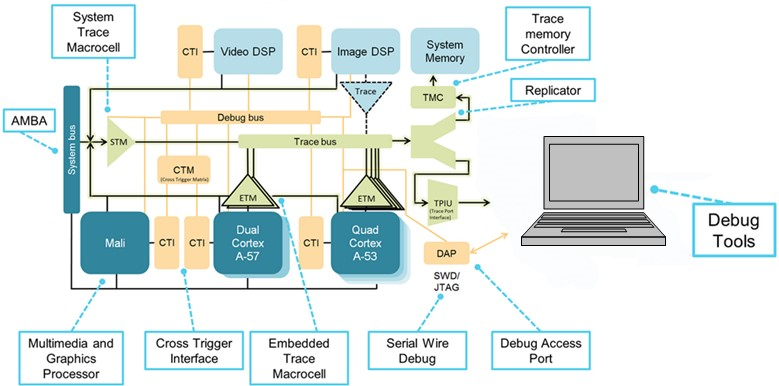
(Fonte:IAR Systems, diagrama cortesia de Arm Ltd.)
Aqui está um exemplo de um processador com implementações multicore heterogêneas e homogêneas. Existem dois grupos principais homogêneos, um baseado em um Dual Arm Cortex-A57 e o outro em um quad Cortex-A53. Esses grupos são homogêneos entre si, mas heterogêneos entre os dois grupos.
A arquitetura de depuração CoreSight fornece protocolos e mecanismos para comunicação com os recursos de depuração em todos os núcleos e cabe ao depurador gerenciar todas essas informações e analisar mensagens de diferentes núcleos. As interfaces e matriz de disparo cruzado (CTI, CTM) permitem a parada simultânea de ambos os núcleos, o disparo de rastreio e muito mais. A infraestrutura de rastreamento inclui as portas de rastreamento serial (SWD) e paralela (TPIU) usadas para suavizar o fluxo de rastreamento e os funis de rastreamento que combinam o rastreamento de cada fonte em um único fluxo. Em comparação com a parte dual-core, o diagrama mostrado representa um chip muito mais complexo de controlar.
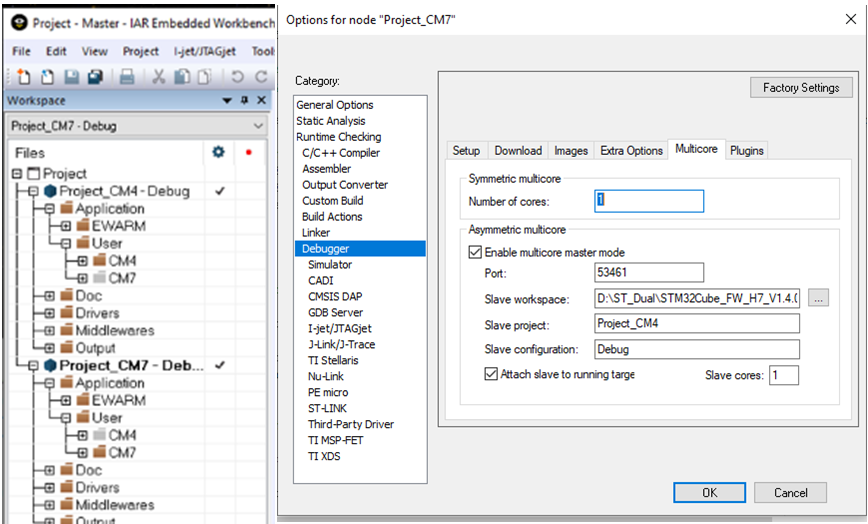
O C-SPY Debugger no IAR Embedded Workbench fornece suporte para depuração multicore simétrica e assimétrica. Isso é habilitado por meio das opções do depurador na guia de vários núcleos. Para habilitar a depuração simétrica de vários núcleos, tudo o que é necessário é que o número de núcleos seja inserido para permitir que o depurador saiba com quantos processadores diferentes se comunicar. Outros IDEs podem ter opções semelhantes disponíveis.
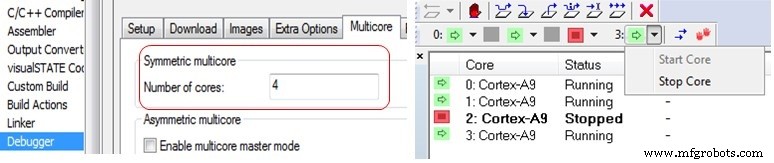
À direita (acima), você pode ver uma visualização no depurador onde um cluster Cortex-A9 SMP de 4 núcleos tem o status de seus núcleos exibido com o núcleo número 2 interrompido enquanto os outros três núcleos estão em execução.
Um sistema multicore assimétrico pode usar uma parte multicore heterogênea, como o ST STM32H745 / 755 que tem um núcleo Cortex-M7 e um Cortex-M4 separado. Neste caso, quando o depurador é executado, ele usa duas instâncias do IDE (Mestre e Nó). Um para cada núcleo, já que os dois núcleos estão executando códigos de projeto diferentes.
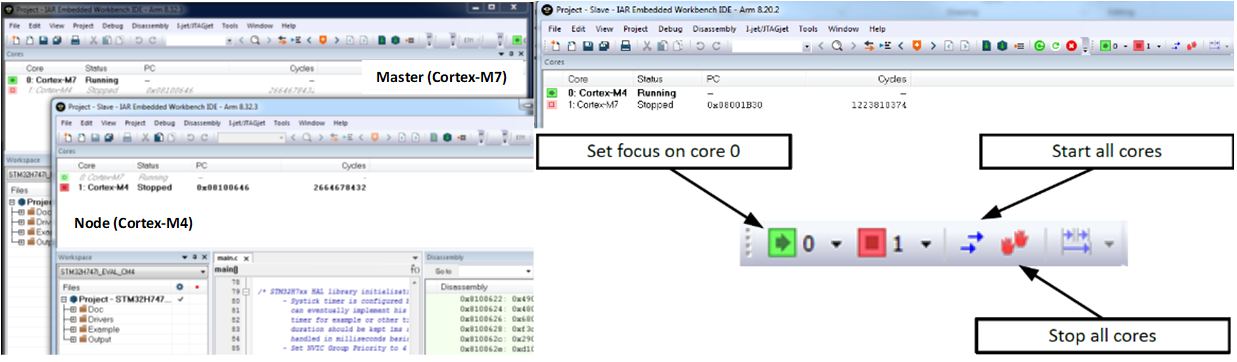
Em cada instância do IDE, há informações de status sobre o núcleo que está sendo controlado, bem como o outro núcleo controlado na outra janela. Existem opções que podem ser selecionadas para controlar o comportamento do depurador de forma que iniciar e interromper os núcleos juntos ou separadamente esteja sob o controle do desenvolvedor.
Este controle total é possível graças às interfaces de disparo cruzado (CTI) e matriz de disparo cruzado (CTM) juntas formam o recurso de disparo cruzado incorporado no Arm. Existem três componentes CTI, um no nível do sistema, um dedicado ao Cortex-M7 e um dedicado ao Cortex-M4. Os três CTIs são conectados entre si por meio do CTM, conforme ilustrado na figura abaixo. O nível de sistema e os CTIs do Cortex-M4 são acessíveis ao depurador por meio da porta de acesso do sistema e do APB-D associado. O Cortex-M7 CTI está fisicamente integrado no núcleo Cortex-M7 e é acessível através da porta de acesso Cortex-M7.
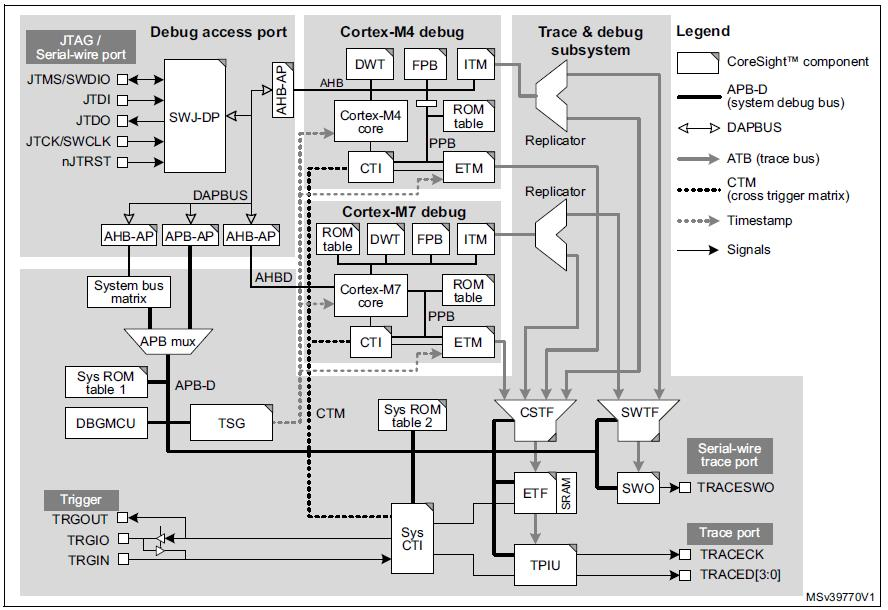
(Fonte:IAR Systems, diagrama cortesia de STMicroelectronics do manual de referência M0399)
Os CTIs permitem que eventos de várias fontes acionem atividades de depuração e rastreamento. Por exemplo, um ponto de interrupção alcançado em um dos núcleos do processador pode parar o outro processador, ou uma transição detectada em uma entrada de gatilho externa pode ser configurada para iniciar o rastreamento do código.
Neste exemplo, com um processador multicore heterogêneo que tem um núcleo Cortex-M7 e um núcleo Cortex-M4 em um único chip, dois programas separados são usados:um para rodar no Cortex-M4 e outro rodando no Cortex-M7. Cada projeto usa FreeRTOS para gerenciar o software em execução nos processadores. Os dois núcleos se comunicam por meio de uma interface de memória compartilhada. No entanto, os aplicativos usam os mecanismos de passagem de mensagem FreeRTOS para se comunicar com o outro processador e ocultar a complexidade dos mecanismos subjacentes. Então, da perspectiva de uma CPU, ele está apenas enviando ou recebendo mensagens com outra tarefa. É transparente que a outra tarefa está sendo executada em outro núcleo da CPU.
A imagem abaixo é a janela do explorador de espaço de trabalho no IDE. A visão geral de dois projetos é exibida aqui para que você possa ver o conteúdo dos projetos Cortex-M7 e Cortex-M4.
Selecionando uma das outras guias na parte inferior da janela, você pode alternar o foco para o projeto M4 ou o projeto M7.
O projeto Cortex-M7 possui uma tarefa que envia mensagens para tarefas em execução no Cortex-M4. O Cortex-M4 possui duas instâncias de uma tarefa de recepção em execução. O Cortex-M7 tem uma tarefa de “verificação” que é executada periodicamente para ver se as coisas ainda estão funcionando corretamente.
Finalmente, o depurador carrega os dois projetos. Isso significa que uma instância adicional do Embedded Workbench para o segundo depurador é iniciada.
Para configurar o depurador para suporte a multiprocessamento assimétrico, precisamos designar um projeto como o “Mestre” e o outro como o projeto “Nó”. Na verdade, a seleção é arbitrária e apenas determina qual projeto tem a capacidade de iniciar o outro na inicialização.
O projeto “Node” não tem configurações especiais e não sabe que está sendo executado como um “Node” para outro projeto.
Desta forma, quando o projeto “Mestre” tem seu depurador iniciado, ele inicia automaticamente outra instância do IDE para acomodar uma segunda sessão do depurador na qual o segundo projeto será executado.
Resumo
Multicore permite ganhos de desempenho quando a lei de Moore se esgota. No entanto, multicore apresenta desafios de depuração e requer abordagens de desenvolvimento específicas para que o aplicativo possa tirar o máximo proveito da arquitetura multicore.
Depois que a configuração de depuração é configurada, a depuração multicore nunca foi tão fácil. Se você já usou ferramentas para depurar mono-núcleos antes, você reconhecerá tudo incluído nisso e provavelmente nunca entenderá outras pessoas falando sobre como a depuração multicore é difícil para eles.
Ferramentas de hardware e software modernas o ajudarão a superar os desafios de depuração de vários núcleos.
Nota:As imagens das figuras são da IAR Systems, a menos que indicado de outra forma.
 Aaron Bauch é engenheiro sênior de aplicação de campo na IAR Systems, trabalhando com clientes no leste dos Estados Unidos e Canadá. Aaron trabalhou com sistemas embarcados e software para empresas como Intel, Analog Devices e Digital Equipment Corporation. Seus projetos cobrem uma ampla gama de aplicações, incluindo instrumentação médica, navegação e sistemas bancários. Aaron também ministrou vários cursos de nível universitário, incluindo Embedded System Design como professor na Southern NH University. O Sr. Bauch é bacharel em Engenharia Elétrica pela Cooper Union e mestre em Engenharia Elétrica pela Columbia University, ambos em Nova York, NY.
Aaron Bauch é engenheiro sênior de aplicação de campo na IAR Systems, trabalhando com clientes no leste dos Estados Unidos e Canadá. Aaron trabalhou com sistemas embarcados e software para empresas como Intel, Analog Devices e Digital Equipment Corporation. Seus projetos cobrem uma ampla gama de aplicações, incluindo instrumentação médica, navegação e sistemas bancários. Aaron também ministrou vários cursos de nível universitário, incluindo Embedded System Design como professor na Southern NH University. O Sr. Bauch é bacharel em Engenharia Elétrica pela Cooper Union e mestre em Engenharia Elétrica pela Columbia University, ambos em Nova York, NY. Conteúdos Relacionados:
- Garantindo o comportamento do tempo do software em sistemas embarcados baseados em múltiplos núcleos críticos
- Sistemas multicore, hipervisores e frameworks multicore
- Computação incorporada de alto desempenho - paralelismo e otimização do compilador
- Você acha que seu software funciona? Prove!
- Rastreamento de software em dispositivos implantados em campo
- Compiladores no mundo estranho da segurança funcional
Para obter mais informações sobre o Embedded, assine o boletim informativo semanal da Embedded por e-mail.
Integrado
- Redes WiFi, provedores de SaaS e os desafios que eles trazem para a TI
- Placas - Divida o Pi - I2C, UART, GPIO e mais
- Os cinco principais problemas e desafios para 5G
- Os Fatores de Risco Complexos do Aeroespacial e da Defesa
- 5G, IoT e os novos desafios da cadeia de suprimentos
- Conheça os desafios de ETL de dados de IoT e maximize o ROI
- Dominando os desafios de torneamento difícil
- Os 4 principais desafios enfrentados pela indústria OEM aeroespacial e de defesa
- A importância e os desafios da documentação atualizada
- Compreendendo os benefícios e desafios da fabricação híbrida