


O que está por trás da mudança para agentes de voz personalizados?
A automação é o caminho do futuro. Vivemos na era de agora, desejando que tudo seja respondido, alcançado e recebido em alta velocidade. Apesar dessa mudança fundamental, muitas pessoas não abraçam a tecnologia. Para alguns, está relacionado ao estilo de vida:as grandes empresas podem ser muito desajeitadas para transformar seu sistema e os indivíduos podem ficar presos em seus caminhos por não querer aprender a navegar em uma tela de toque. Para a maioria, no entanto, tudo se resume aos dados - quem os possui e como mantê-los protegidos.
A solução? É tão simples quanto uma voz. A tecnologia de ativação de voz pode desbloquear a necessidade de automação e, ao mesmo tempo, manter os dados próximos, e é algo que usamos todos os dias, independentemente do local ou plataforma. Como a transformação digital continua a impactar mais e mais aplicativos, os agentes de voz são a resposta. Mais empresas estão explorando a construção de plataformas de voz personalizadas, incorporadas à tecnologia, além de nomes familiares de agentes de voz populares como Alexa e Google Voice. As plataformas de voz exclusivas serão o caminho a seguir para as empresas que buscam manter e controlar seus próprios dados.
Por trás da interrupção está a automação
À medida que a Internet das Coisas (IoT) se baseia na Inteligência Artificial (IA), começamos a ver a necessidade de crescimento da automação. Quando a IoT colabora com a IA, ela melhora o controle que os usuários têm sobre a vasta e ampla coleção de dispositivos da Internet. Estamos começando a ver a capacidade de expansão da voz dentro e fora de casa, fazendo interface por meio de plataformas como Google Voice, Amazon Alexa, Microsoft Cortana ou plataformas criadas exclusivamente. Na Harman Embedded Audio, trabalhamos com todos os mecanismos de voz do planeta e entendemos a amplitude do mercado em primeira mão. Vemos mais empresas procurando construir seus produtos habilitados para voz em suas próprias plataformas personalizadas de assistente de voz, para que tenham controle dos dados.
A demanda por controle de voz está crescendo
É uma das tendências mais quentes em áudio. A próxima grande novidade na interface do usuário, agora que recursos como telas sensíveis ao toque são quase onipresentes, é ser capaz de falar com um dispositivo. O Voice está liderando a próxima geração de colaboração humana. Pense no processamento de linguagem natural em um computador:a voz é processada de uma maneira que se encaixa no que a máquina prefere ouvir, mas se você reproduzisse o mesmo arquivo processado, seria mecânico e não natural. O mesmo vale para falar ao telefone:não dá a mesma impressão de estar em uma sala com alguém. É para onde a voz precisa ir e para onde as plataformas de voz exclusivas mencionadas acima se seguirão.
Qual é a aparência dos agentes de voz personalizados e o que está envolvido na construção
Embora cada solução de voz seja diferente, é importante que todas as soluções sejam flexíveis o suficiente para se adaptar aos requisitos necessários de seu caso de uso, enquanto ainda coleta e protege os dados do usuário. Para conseguir isso, existem três elementos principais envolvidos na construção e integração de qualquer agente de voz.
O primeiro são os algoritmos de campo distante. Use um algoritmo de nível superior que irá capturar voz de campo distante. Na minha empresa, usamos quatro algoritmos de software principais dos algoritmos Sonique:supressão de ruído, cancelamento de ruído acústico, separação de som e formação de feixe, bem como detecção de atividade de voz. Esses algoritmos são desenvolvidos especificamente para serem usados em combinação uns com os outros para oferecer suporte a aplicativos habilitados para voz.
Como eles funcionam? Pense em comparar um alto-falante inteligente com um humano. O DSP / SOC atua como o "cérebro" do alto-falante, os microfones são os ouvidos e os alto-falantes são a boca. Para nós, quando alguém chama nosso nome, nosso cérebro cancela todos os ruídos ao nosso redor e coloca toda sua energia naquela palavra-chave. Isso é o que conseguimos em um alto-falante inteligente - quando a palavra-chave é detectada, o microfone usa diferentes técnicas de supressão de ruído e coloca toda a sua força na fonte. No processo, ele cancela a maior parte do ruído ao seu redor. Em ambientes acústicos, existem muitas fontes de ruído, como ruído ambiente, alto-falantes locais, HVAC e muito mais, que ecoam o feedback do alto-falante para o microfone. Cada uma dessas fontes de ruído precisa de sua própria solução individual. Os algoritmos do Sonique suprimem os ruídos e capturam o melhor comando de voz claro possível.
Além disso, construir um mecanismo de detecção de palavras-chave (KWS) é crucial. O KWS detecta palavras-chave como “Alexa” ou “OK Google,” para iniciar uma conversa. Já trabalhei com quase todos os fornecedores de mecanismo KWS, e cada um é alimentado por redes neurais profundas - altamente personalizáveis, sempre ouvindo, leves e integradas. Para uma ótima experiência do cliente em um aplicativo de voz de campo distante, o componente crucial é uma taxa de aceitação falsa e rejeição falsa. Em uma condição do mundo real, é realmente desafiador manter uma taxa baixa de rejeição falsa, pois há muitos ruídos externos, como TVs, eletrodomésticos, chuveiros, etc., que causam o cancelamento imperfeito da reprodução de áudio. Desenvolvedores experientes ajustam o mecanismo KWS para manter a taxa de aceitação falsa baixa.
Finalmente, o mecanismo de reconhecimento automático de fala (ASR) converte voz em texto. ASR consiste na principal ferramenta de fala para texto (STT) e compreensão de linguagem natural (NLU), que converte o texto bruto em dados. O motor também exige habilidade, ou, em outras palavras, uma base de conhecimento a partir da qual as respostas possam ser fornecidas, bem como a ferramenta de conversão de texto para fala. Desenvolvemos um mecanismo ASR chamado E-NOVA, por exemplo, que oferece integrações multi-plataforma no local, oferece suporte a vários idiomas (atualmente sete idiomas e em crescimento) e inclui modelos treináveis, suporte de integração de terceiros e identificação do locutor.
ASR é a primeira etapa que permite que tecnologias de voz como Amazon Alexa, OK Google, Cortana ou cliente respondam quando solicitado, "como está o tempo em Los Angeles?" É a parte principal que detecta o som falado, reconhece-os como palavras, combina-os com o som em um determinado idioma e, por fim, identifica as palavras que dizemos. Por causa do mecanismo ASR, a conversa parece natural. E, com tecnologias modernas, a maioria dos motores ASR tira proveito da computação em nuvem. Com tecnologias adicionais como a NLU, as conversas entre humanos e computadores estão ficando mais inteligentes e complexas.
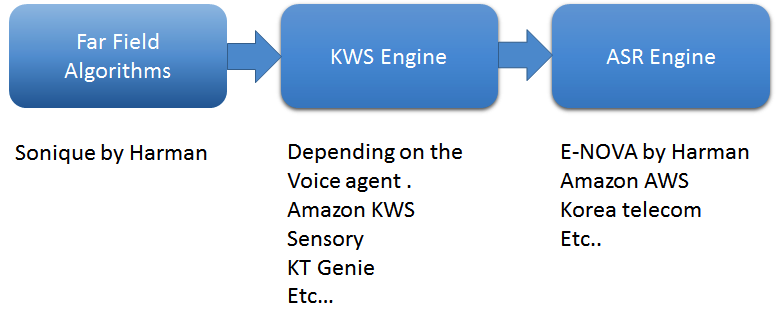
Figura 1:Pipeline de processamento básico em agentes de voz. (Fonte:Harman Embedded Audio)
Construir agentes de voz personalizados apresenta uma série de desafios únicos, entretanto. Compreender o ambiente do produto é um dos principais desafios do processo, e cada aplicativo irá variar com base no caso de uso específico. Por exemplo, imagine cozinhar em sua casa, suas mãos estão ocupadas e cheias, quando é hora de ferver um pouco de água, tudo o que é necessário é um pedido rápido para o agente de voz conectado ao seu espaço de encanamento:"Ferva a água a x graus." O desafio aqui é se o dispositivo é capaz de ouvir o que você disse e quanto ruído o dispositivo cancelará para obter o sinal limpo e ouvi-lo corretamente. Para garantir isso, os algoritmos de voz precisam ser ajustados para ambientes hostis, os locais dos microfones precisam ser ajustados para que possam captar o som e alto-falantes com THD baixo devem ser usados para ajudar a SNR alto para os microfones. Com isso, você obterá o áudio mais claro possível para o mecanismo ASR, o que resulta na resposta certa para suas perguntas.
Além disso, imagine estar em um navio de cruzeiro:os ruídos ao seu redor são completamente diferentes do que você ouve na sala de estar ou na cozinha. O maior desafio é treinar algoritmos para suprimir esses ruídos e obter o sinal de áudio limpo para o sistema para uma resposta precisa. Implementado de maneira adequada, um sistema de assistente de cruzeiro pessoal virtual, como o que desenvolvemos para a MSC Cruzeiros, pode concluir com segurança as etapas mostradas na Figura 2.
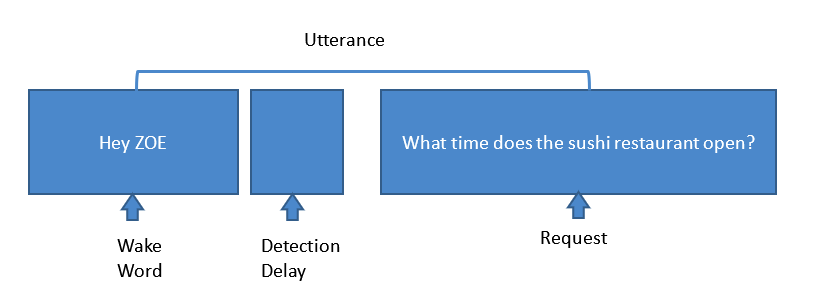
Figura 2:Etapas envolvidas na solicitação típica do assistente de voz. (Fonte:Harman Embedded Audio)
Aqui, uma unidade de assistente de voz na sala do passageiro detecta a palavra de despertar ‘Hey Zoe’. Então, conforme o KWS detecta a palavra-chave, todo o microfone, baseado em algoritmos de supressão de ruído, desvia sua energia para a fonte e cancela o ruído ambiente, como ruído CA, TV, ruídos não correlacionados, ruídos de hélice e motor, ruídos de vento, AEC , etc. Os algoritmos do Sonique são ajustados para cancelar todos esses ruídos e obter o sinal mais limpo possível para o sistema. Então, quando o sistema obtém a solicitação, o mecanismo ASR converte essa voz em texto. Os motores NLU então convertem esse texto em dados brutos para obter a resposta. Mas ainda não terminamos. Para obter a resposta que você está procurando, a habilidade de conhecimento fornece a resposta à solicitação e o mecanismo ASR converte esse texto de dados em fala e o envia pelo alto-falante.
Outro desafio é a rejeição de taxa falsa (FRR). O processo de obtenção do Wake Word FRR, que é um dos pontos de verificação usados para medir o desempenho do alto-falante inteligente, é demorado e caro. O sistema é usado para verificar se o produto pode ser ativado corretamente sempre que uma palavra de ativação for detectada. Para alcançar a FRR, palavras-chave treinadas são essenciais. Em nossa experiência, combinar o modelo treinado com um algoritmo de primeira linha permite que as equipes de desenvolvimento superem o desafio e alcancem o melhor FRR possível. A resposta do wake word é posteriormente testada em várias condições em um laboratório para garantir que o sistema atenda aos padrões da indústria.
As vantagens de empregar agentes de voz exclusivos
Os agentes de voz oferecem grande valor à experiência do usuário. A música é o caso de uso maior e mais simples, mas o valor dos agentes de voz vai muito além de abrir sua conta do Spotify remotamente. A voz pode ligar coisas, interagir com eletrodomésticos, ferver água, abrir uma torneira - e muito mais! A voz é poderosa, e os agentes sabem muito sobre seus usuários, razão pela qual as empresas estão procurando obter seus próprios dados - possuí-los, armazená-los e protegê-los.
As soluções de voz têm amplas aplicações, mas a chave é aproveitar uma tecnologia que funcione em todas as plataformas - relevante para alto-falantes inteligentes, laptops e smartphones, em Apple, Windows ou Android - e aproveitar os dados coletados para construir um agente que entenda, constantemente aprende e lembra as necessidades do usuário. A criação de um agente de voz exclusivo permite essa flexibilidade de uso - e mantém os dados internos ao mesmo tempo.
Integrado
- O que é o vidro metálico?
- Qual é a diferença entre a produção em massa e a produção personalizada?
- O que é reformulação da plataforma na nuvem?
- O que eu faço com os dados ?!
- O que é a economia circular?
- Motor CC x CA:qual é a diferença?
- O que está no processo de fabricação?
- O que é a indústria gráfica?
- O que é a indústria de tintas?
- O que é a indústria de embalagens?