


Como a computação in-memory analógica pode resolver os desafios de energia da inferência de IA de borda
O aprendizado de máquina e o aprendizado profundo já são partes integrantes de nossas vidas. Os aplicativos de Inteligência Artificial (IA) via Processamento de Linguagem Natural (PNL), classificação de imagens e detecção de objetos estão profundamente incorporados em muitos dos dispositivos que usamos. A maioria dos aplicativos de IA são servidos por meio de mecanismos baseados em nuvem que funcionam bem para o que são usados, como obter previsões de palavras ao digitar uma resposta de e-mail no Gmail.
Por mais que aproveitemos os benefícios desses aplicativos de IA, essa abordagem apresenta desafios de privacidade, dissipação de energia, latência e custo. Esses desafios podem ser resolvidos se houver um mecanismo de processamento local capaz de realizar computação parcial ou total (inferência) na origem dos próprios dados. Isso tem sido difícil de fazer com as implementações tradicionais de redes neurais digitais, nas quais a memória se torna um gargalo que consome muita energia. O problema pode ser resolvido com memória multinível e o uso de um método de computação analógico na memória que, juntos, permitem que os mecanismos de processamento atendam aos requisitos de energia de miliwatt (mW) a microwatt (uW) muito mais baixos para realizar a inferência de IA em a borda da rede.
Desafios da computação em nuvem
Quando os aplicativos de IA são servidos por meio de mecanismos baseados em nuvem, o usuário deve fazer upload de alguns dados (voluntariamente ou não) para nuvens onde os mecanismos de computação processam os dados, fornecem previsões e enviam as previsões downstream para o usuário consumir.

Figura 1:Transferência de dados do Edge para a nuvem. (Fonte:Microchip Technology)
Os desafios associados a este processo são descritos abaixo:
- Questões de privacidade e segurança: Com dispositivos sempre ligados e sempre atentos, há uma preocupação com o uso indevido de dados pessoais (e / ou informações confidenciais), seja durante uploads ou durante sua vida útil em data centers.
- Dissipação desnecessária de energia: Se cada bit de dados vai para a nuvem, está consumindo energia de hardware, rádios, transmissão e, potencialmente, em cálculos indesejados na nuvem.
- Latência para inferências de pequenos lotes: Às vezes, pode demorar um segundo ou mais para obter uma resposta de um sistema baseado em nuvem se os dados forem originados na borda. Para os sentidos humanos, qualquer coisa acima de 100 milissegundos (ms) de latência é perceptível e pode ser irritante.
- A economia de dados precisa fazer sentido: Os sensores estão por toda parte e são muito acessíveis; no entanto, eles produzem muitos dados. Não é econômico fazer upload de cada bit de dados para a nuvem e processá-los.
Para resolver esses desafios usando um mecanismo de processamento local, o modelo de rede neural que executará as operações de inferência deve primeiro ser treinado com um determinado conjunto de dados para o caso de uso desejado. Geralmente, isso requer altos recursos de computação (e memória) e operações aritméticas de ponto flutuante. Como resultado, a parte de treinamento de uma solução de aprendizado de máquina ainda precisa ser feita em nuvens públicas ou privadas (ou uma GPU, CPU, FPGA local) com um conjunto de dados para gerar um modelo de rede neural ideal. Uma vez que o modelo de rede neural está pronto, o modelo pode ainda ser otimizado para um hardware local com um pequeno mecanismo de computação porque o modelo de rede neural não precisa de retropropagação para operação de inferência. Um mecanismo de inferência geralmente precisa de um mar de mecanismos Multiply-Accumulate (MAC), seguido por uma camada de ativação, como unidade linear retificada (ReLU), sigmóide ou tanh dependendo da complexidade do modelo de rede neural e uma camada de pooling entre as camadas.
A maioria dos modelos de rede neural requer uma grande quantidade de operações MAC. Por exemplo, mesmo um modelo comparativamente pequeno ‘1.0 MobileNet-224’ tem 4,2 milhões de parâmetros (pesos) e requer 569 milhões de operações MAC para realizar uma inferência. Como a maioria dos modelos é dominada por operações MAC, o foco aqui será nesta parte da computação de aprendizado de máquina - e explorar a oportunidade de criar uma solução melhor. Uma rede de duas camadas simples e totalmente conectada é ilustrada abaixo na Figura 2.
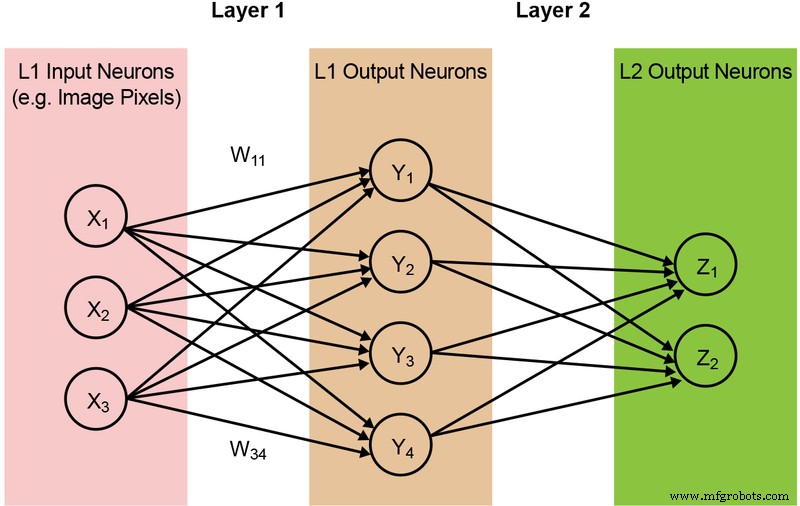
Figura 2:Rede Neural Totalmente Conectada com Duas Camadas. (Fonte:Microchip Technology)
Os neurônios de entrada (dados) são processados com a primeira camada de pesos. Os neurônios de saída das primeiras camadas são então processados com a segunda camada de pesos e fornecem previsões (digamos, se o modelo foi capaz de encontrar uma cara de gato em uma determinada imagem). Esses modelos de rede neural usam "um produto escalar" para o cálculo de cada neurônio em cada camada, ilustrado pela seguinte equação (omitindo o termo de "polarização" na equação para simplificação):
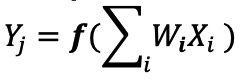
Memória Gargalo na computação digital
Em uma implementação de rede neural digital, os pesos e os dados de entrada são armazenados em uma DRAM / SRAM. Os pesos e os dados de entrada precisam ser movidos para um mecanismo MAC para inferência. Conforme a Figura 3 abaixo, esta abordagem resulta na maior parte da energia sendo dissipada na busca de parâmetros do modelo e dados de entrada para a ALU onde a operação MAC real ocorre.
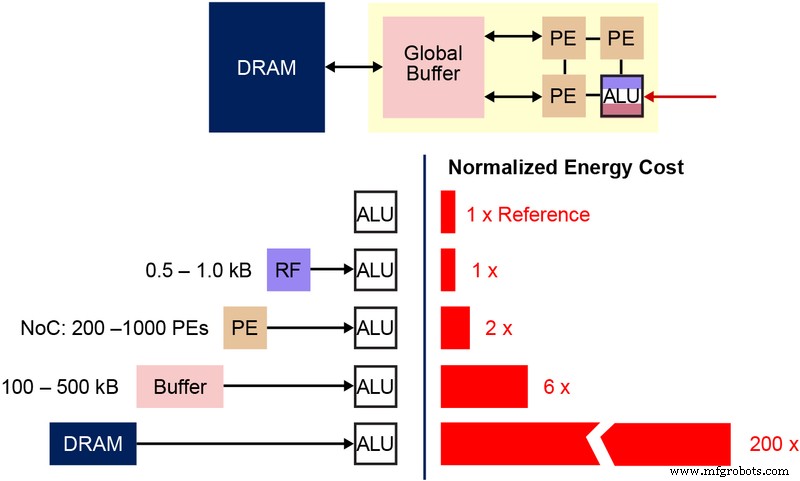
Figura 3:Gargalo de memória na computação de aprendizado de máquina. (Fonte:Y.-H. Chen, J. Emer e V. Sze, "Eyeriss:A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks," in ISCA, 2016.)
Para colocar as coisas em uma perspectiva energética - uma operação típica de MAC usando portas lógicas digitais consome ~ 250 femtojoules (fJ, ou 10
−15
joules) de energia, mas a energia dissipada durante a transferência de dados é mais do que duas ordens de magnitude do que o próprio cálculo e fica na faixa de 50 picojoules (pJ, ou 10
−12
joules) a 100pJ. Para ser justo, existem muitas técnicas de design disponíveis para minimizar a transferência de dados da memória para a ALU; no entanto, todo o esquema digital ainda é limitado pela arquitetura de Von Neumann - portanto, isso representa uma grande oportunidade para reduzir o desperdício de energia. E se a energia para realizar uma operação MAC puder ser reduzida de ~ 100pJ para uma fração de pJ?
Removendo o gargalo de memória com computação analógica na memória
Executar operações de inferência na borda torna-se eficiente em termos de energia quando a própria memória pode ser usada para reduzir a energia necessária para computação. O uso de um método de computação na memória minimiza a quantidade de dados que deve ser movida. Isso, por sua vez, elimina o desperdício de energia durante a transferência de dados. A dissipação de energia é ainda mais minimizada com o uso de células flash que podem operar com dissipação de energia ativa ultrabaixa e quase nenhuma dissipação de energia durante o modo de espera.
Um exemplo dessa abordagem é a tecnologia memBrain ™ da Silicon Storage Technology (SST), uma empresa Microchip Technology. Baseado no SuperFlash
®
da SST tecnologia de memória, a solução inclui uma arquitetura de computação em memória que permite que a computação seja feita onde os pesos do modelo de inferência são armazenados. Isso elimina o gargalo de memória na computação MAC, pois não há movimentação de dados para os pesos - apenas os dados de entrada precisam ser movidos de um sensor de entrada, como câmera ou microfone, para o array de memória.
Este conceito de memória é baseado em dois fundamentos:(a) A resposta de corrente elétrica analógica de um transistor é baseada em sua tensão de limiar (Vt) e os dados de entrada, e (b) a lei da corrente de Kirchhoff, que afirma que a soma algébrica das correntes em uma rede de condutores se encontrando em um ponto é zero.
Também é importante compreender a célula de bits de memória não volátil (NVM) fundamental que é usada nesta arquitetura de memória de vários níveis. O diagrama abaixo (Figura 4) é uma seção transversal de dois ESF3 (Embedded SuperFlash 3
rd
geração) bitcells com Erase Gate (EG) e Source Line (SL) compartilhados. Cada bitcell possui cinco terminais:Control Gate (CG), Work Line (WL), Erase Gate (EG), Source Line (SL) e Bitline (BL). A operação de apagamento na célula de bits é feita pela aplicação de alta tensão no EG. A operação de programação é feita aplicando sinais de polarização de alta / baixa tensão em WL, CG, BL e SL. A operação de leitura é feita aplicando sinais de polarização de baixa tensão em WL, CG, BL e SL.
Figura 4:Célula SuperFlash ESF3. (Fonte:Microchip Technology)
Com esta arquitetura de memória, o usuário pode programar as células de bits de memória em vários níveis de Vt por operação de programação refinada. A tecnologia de memória utiliza um algoritmo inteligente para sintonizar a porta flutuante (FG) Vt da célula de memória para obter certa resposta de corrente elétrica de uma tensão de entrada. Dependendo dos requisitos da aplicação final, as células podem ser programadas em regiões de operação linear ou sublimiar.
A Figura 5 ilustra a capacidade de armazenar e ler vários níveis na célula de memória. Digamos que estejamos tentando armazenar um valor inteiro de 2 bits em uma célula de memória. Para este cenário, precisamos programar cada célula em uma matriz de memória com um dos quatro valores possíveis dos valores inteiros de 2 bits (00, 01, 10, 11). As quatro curvas abaixo são uma curva IV para cada um dos quatro estados possíveis, e a resposta da corrente elétrica da célula dependeria da voltagem aplicada no CG.
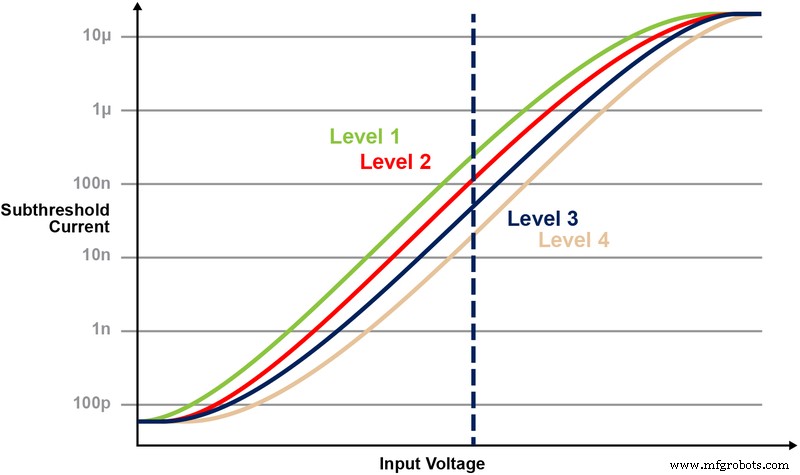
Figura 5:Programação dos níveis de Vt na célula ESF3. (Fonte:Microchip Technology)
Operação de multiplicação-acumulação com computação in-memory
Cada célula ESF3 pode ser modelada como condutância variável (g m ) A condutância de uma célula ESF3 depende da porta flutuante Vt da célula programada. Um peso de um modelo treinado é programado como porta flutuante Vt da célula de memória, portanto, g m da célula representa um peso do modelo treinado. Quando uma tensão de entrada (Vin) é aplicada na célula ESF3, a corrente de saída (Iout) seria dada pela equação Iout =g m * Vin, que é a operação de multiplicação entre a tensão de entrada e o peso armazenado na célula ESF3.
A Figura 6 abaixo ilustra o conceito de multiplicação-acumulação em uma configuração de pequena matriz (matriz 2 × 2) em que a operação de acumulação é realizada adicionando correntes de saída (das células (da operação de multiplicação) conectadas à mesma coluna (por exemplo I1 =I11 + I21) Dependendo da aplicação, a função de ativação pode ser realizada dentro do bloco ADC ou pode ser realizada com uma implementação digital fora do bloco de memória.
clique para ampliar a imagem
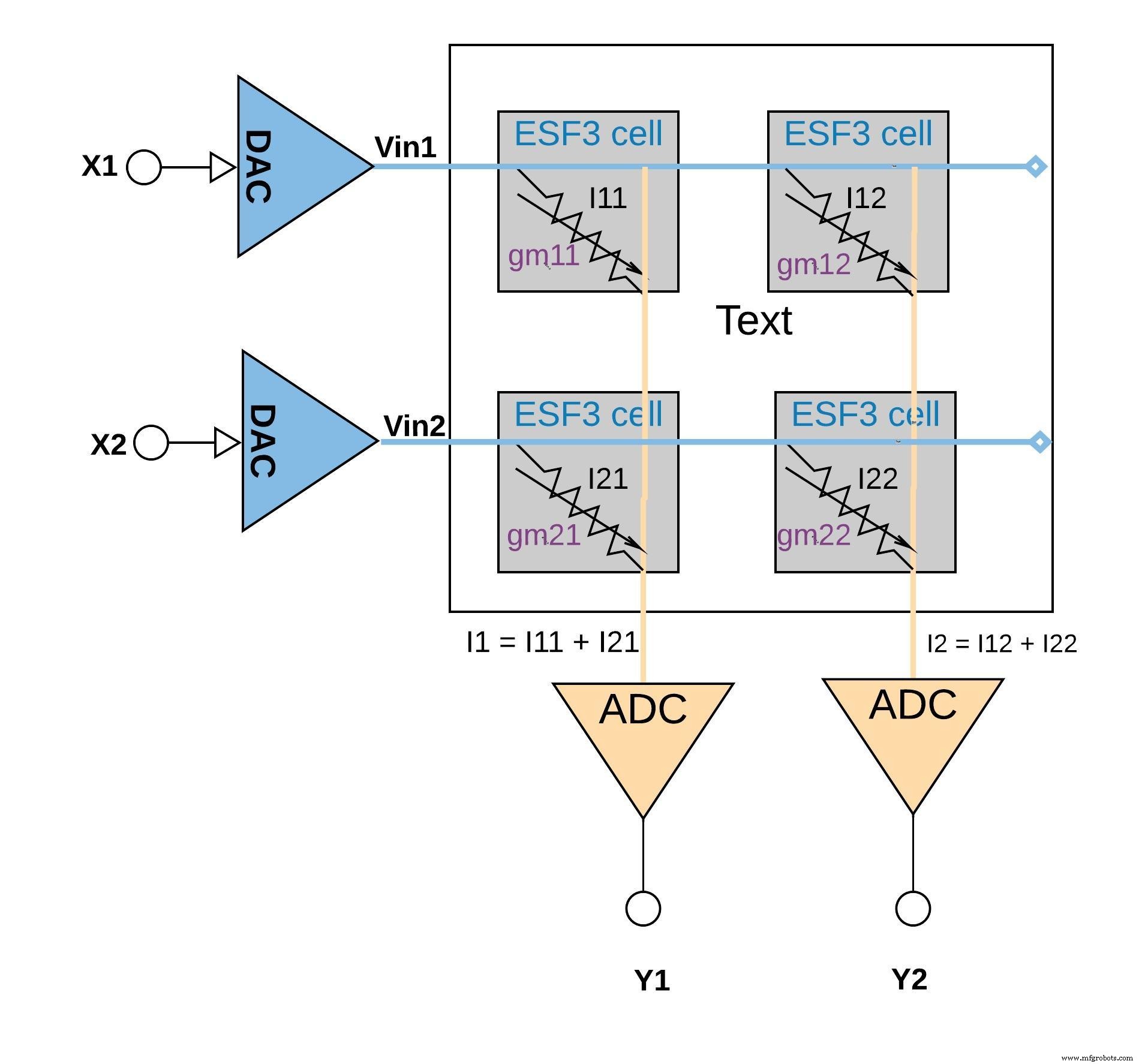
Figura 6:operação de multiplicação-acumulação com matriz ESF3 (2 × 2). (Fonte:Microchip Technology)
Para ilustrar ainda mais o conceito em um nível superior; pesos individuais de um modelo treinado são programados como porta flutuante Vt da célula de memória, de modo que todos os pesos de cada camada do modelo treinado (digamos uma camada totalmente conectada) podem ser programados em uma matriz de memória que se parece fisicamente com uma matriz de peso , conforme ilustrado na Figura 7.
clique para ampliar a imagem
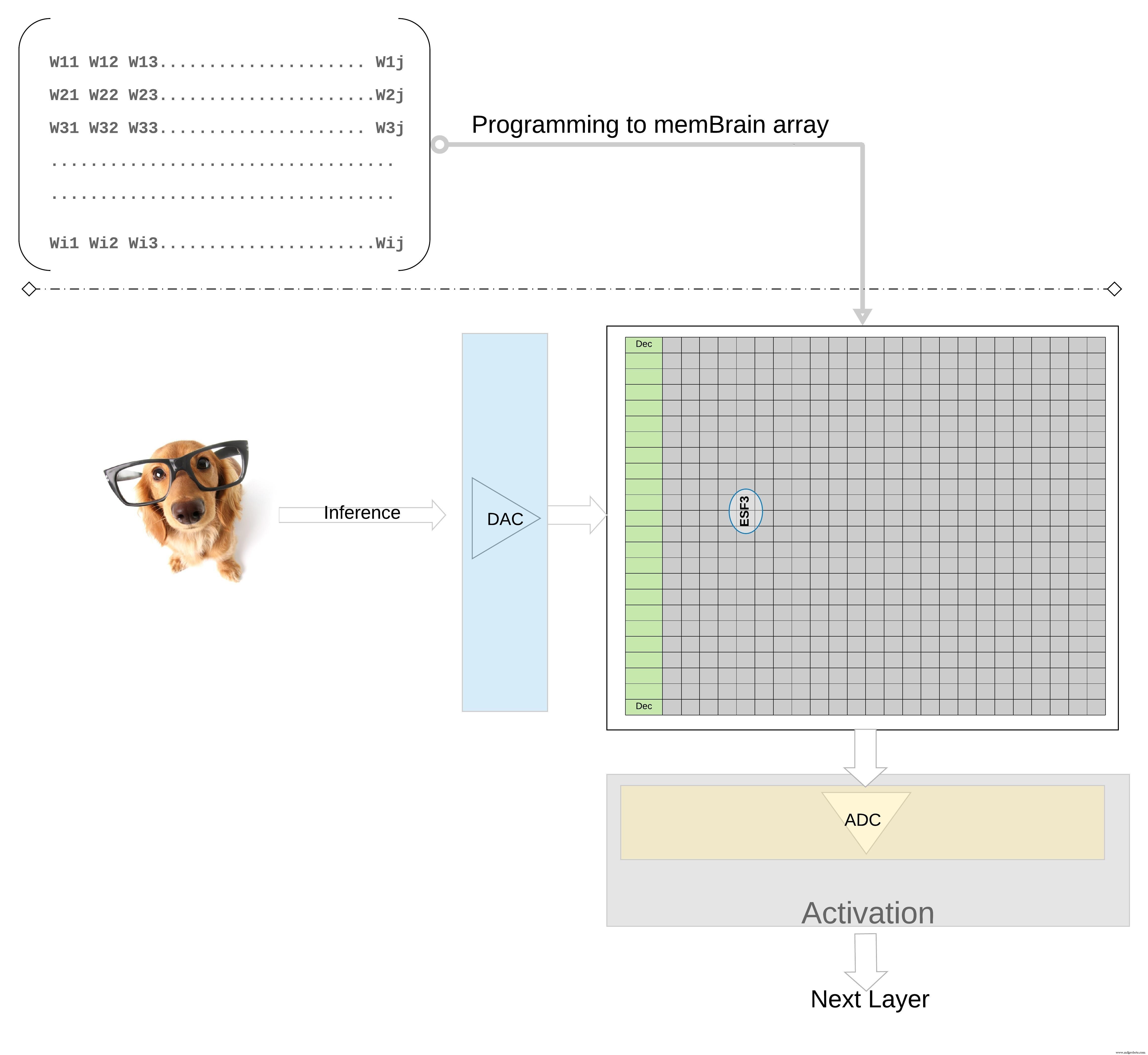
Figura 7:Matriz de memória de matriz de peso para inferência. (Fonte:Microchip Technology)
Para uma operação de inferência, uma entrada digital, digamos pixels de imagem, é primeiro convertida em um sinal analógico usando um conversor digital para analógico (DAC) e aplicada à matriz de memória. A matriz então realiza milhares de operações MAC em paralelo para o vetor de entrada dado e produz saída que pode ir para o estágio de ativação dos respectivos neurônios, que podem então ser convertidos de volta em sinais digitais usando um conversor analógico-digital (ADC). Os sinais digitais são então processados para agrupamento antes de ir para a próxima camada.
Este tipo de arquitetura de memória é muito modular e flexível. Muitos ladrilhos memBrain podem ser costurados para construir uma variedade de modelos grandes com uma mistura de matrizes de peso e neurônios, conforme ilustrado na Figura 8. Neste exemplo, uma configuração de ladrilho 3 × 4 é costurada com um tecido analógico e digital entre os blocos, e os dados podem ser movidos de um bloco para outro por meio de um barramento compartilhado.
clique para ampliar a imagem
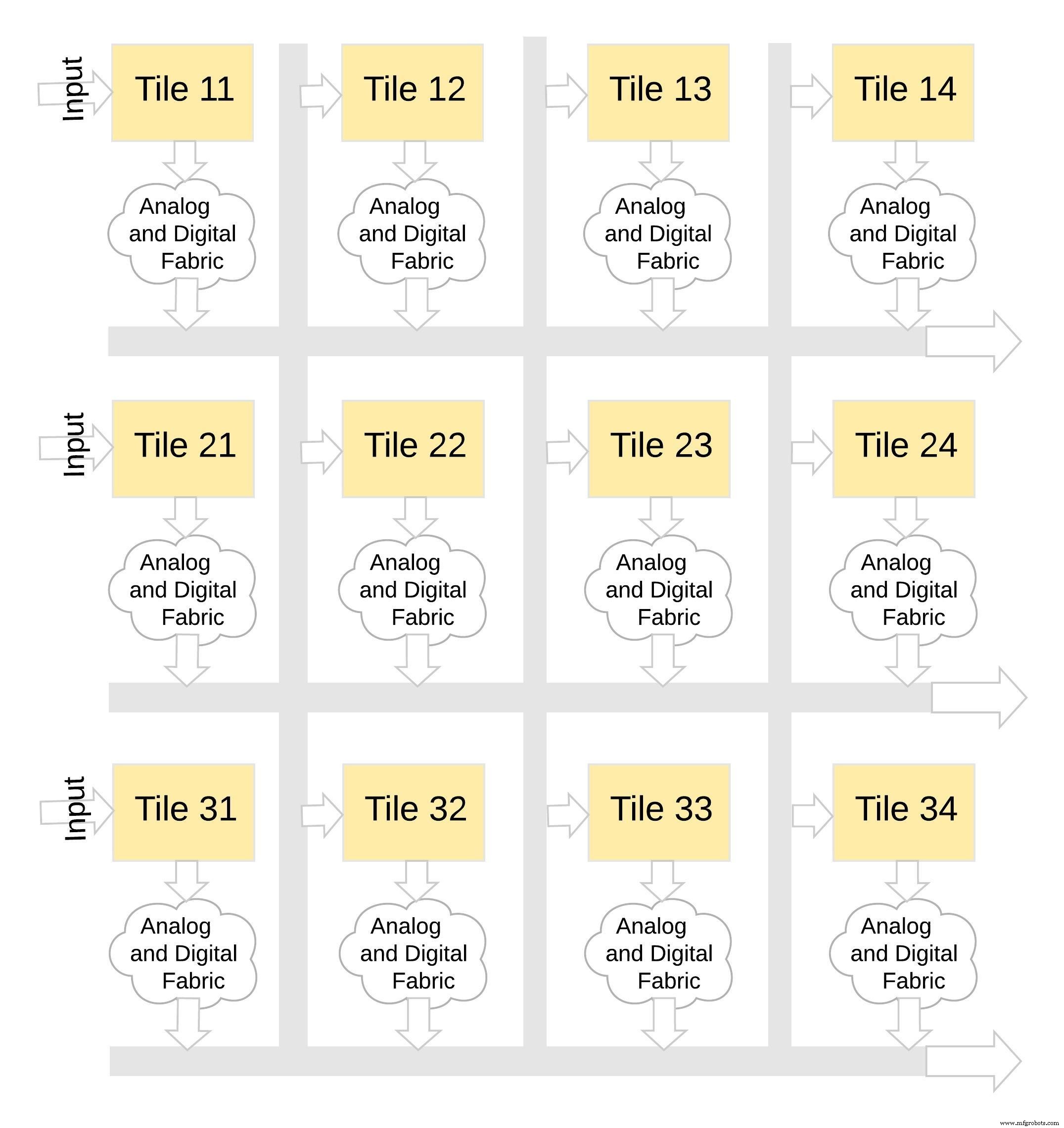
Figura 8:memBrain ™ é modular. (Fonte:Microchip Technology)
Até agora, discutimos principalmente a implementação de silício dessa arquitetura. A disponibilidade de um Software Development Kit (SDK) (Figura 9) auxilia na implantação da solução. Além do silício, o SDK facilita a implantação do mecanismo de inferência.
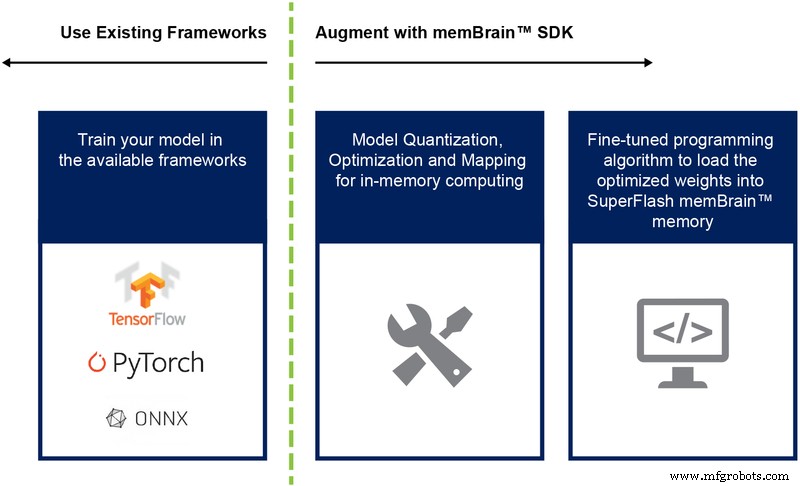
Figura 9:Fluxo do SDK memBrain ™. (Fonte:Microchip Technology)
O fluxo do SDK é independente da estrutura de treinamento. O usuário pode criar um modelo de rede neural em qualquer uma das estruturas disponíveis, como TensorFlow, PyTorch ou outros, usando computação de ponto flutuante conforme desejado. Depois que um modelo é criado, o SDK ajuda a quantizar o modelo de rede neural treinado e mapeá-lo para a matriz de memória onde a multiplicação de vetor-matriz pode ser realizada com o vetor de entrada vindo de um sensor ou computador.
Conclusão
As vantagens dessa abordagem de memória multinível com seus recursos de computação na memória incluem:
- Potência extremamente baixa: A tecnologia é projetada para aplicações de baixo consumo de energia. A vantagem de energia de primeiro nível vem do fato de que a solução é a computação in-memory, então a energia não está sendo desperdiçada na transferência de dados e pesos da SRAM / DRAM durante a computação. A segunda vantagem de energia decorre do fato de que as células flash estão sendo operadas em modo subliminar com valores de corrente muito baixos, de modo que a dissipação de energia ativa é muito baixa. A terceira vantagem é que quase não há dissipação de energia durante o modo de espera, uma vez que a célula de memória não volátil não precisa de energia para manter os dados do dispositivo sempre ligado. A abordagem também é adequada para explorar a dispersão de pesos e dados de entrada. A célula de bits de memória não é ativada se os dados de entrada ou peso forem zero.
- Menor pegada de embalagem: A tecnologia usa uma arquitetura de célula de porta dividida (1.5T), enquanto uma célula SRAM em uma implementação digital é baseada em uma arquitetura 6T. Além disso, a célula é uma célula de bits muito menor em comparação com uma célula 6T SRAM. Além disso, uma célula pode armazenar todo o valor inteiro de 4 bits, ao contrário de uma célula SRAM que precisa de 4 * 6 =24 transistores para fazer isso. Isso fornece uma pegada no chip substancialmente menor.
- Menor custo de desenvolvimento: Devido aos gargalos de desempenho de memória e às limitações da arquitetura de von Neumann, muitos dispositivos criados para esse fim (como o Jetsen da Nvidia ou o TPU do Google) tendem a usar geometrias menores para obter desempenho por watt, o que é uma maneira cara de resolver o desafio de computação de IA de ponta. Com a abordagem de memória multinível usando métodos de computação analógicos na memória, a computação está sendo feita no chip em células flash para que se possa usar geometrias maiores e reduzir os custos de máscara e tempos de entrega.
Os aplicativos de computação de ponta são muito promissores. Ainda assim, há desafios de poder e custo a serem resolvidos antes que a computação de ponta possa decolar. Um grande obstáculo pode ser removido usando uma abordagem de memória que executa computação no chip em células flash. Essa abordagem tira proveito de um tipo padrão de fato comprovado pela produção de solução de tecnologia de memória multinível que é otimizada para aplicativos de aprendizado de máquina.
Integrado
- Como o Edge Computing pode beneficiar a TI corporativa
- Como a computação em nuvem pode beneficiar a equipe de TI?
- Uma introdução à computação de ponta e exemplos de casos de uso
- Computação de borda:5 armadilhas potenciais
- Como os dados IIoT podem aumentar a lucratividade na manufatura enxuta
- Mais perto da borda:Como a computação avançada conduzirá a Indústria 4.0
- Como uma queda de energia pode danificar suas fontes de alimentação
- 6 boas razões para adotar a computação de borda
- Edge Computing e 5G dimensionam a empresa
- Como pequenas lojas podem se tornar digitais — economicamente!