


2017 é o ano da interface de voz?
Nos últimos anos, avanços significativos no reconhecimento automático de voz (ASR) levaram a uma abundância de dispositivos e aplicativos que usam a voz como sua interface principal. O espectro IEEE a revista declarou 2017 o ano do reconhecimento de voz; A ZDNet relatou da CES 2017 que a voz é a próxima interface de computador; e muitos outros compartilham pontos de vista semelhantes. Então, onde estamos em relação ao avanço das interfaces de voz? Esta postagem fará um levantamento do estado atual das interfaces de voz e suas tecnologias de habilitação.
Quantos de seus dispositivos conversam com você?
A ativação por voz está ao nosso redor. Quase todo smartphone tem uma interface de voz, com carros-chefe como o Apple iPhone 7 e Samsung Galaxy S7, incluindo recursos de escuta permanente. A maioria dos smartwatches oferece ativação por voz, bem como outros wearables, e especialmente audíveis, como AirPods da Apple e Gear IconX da Samsung. Na maioria desses dispositivos, não há uma maneira conveniente de integrar qualquer outra interface, tornando a voz uma solução ideal e necessária. Novas câmeras, como a GoPro Hero 5, podem ser operadas usando comandos de voz, o que é ótimo para selfies. Os sistemas de infoentretenimento para automóveis ativados por voz tornaram-se uma mercadoria, tornando muito mais seguro mudar de estação enquanto se dirige.
O Amazon Echo deu início à tendência do assistente de conversação, que está em alta com o Google Home tentando contender e uma variedade de clones semelhantes apresentados no CES 2017. O serviço de voz do Echo, chamado Alexa, vem com várias habilidades integradas. Por exemplo, você pode dizer “Alexa, conte uma piada” (entrega muito irônica), “Alexa, os Warriors ganharam?” (é claro que sim), ou “Alexa, que estrelou o filme 2001:Uma Odisséia no Espaço?” (ninguém mais parece saber). Também há um monte de ovos de Páscoa divertidos, como a resposta quando você diz “Alexa, iniciar sequência de autodestruição”. (veja também este vídeo que demonstra alguns dos ovos de Páscoa de Alexa).
Além das funções integradas, novos recursos podem ser adicionados ao Alexa por terceiros usando o Alexa Skills Kit (ASK). Este ASK permite que os desenvolvedores ensinem novas habilidades a Alexa para que ela (ou ela?) Possa controlar e interagir com mais produtos e serviços. Como você pode ver neste vídeo, por exemplo, uma pessoa hackeou seu iRobot Roomba e adicionou uma habilidade para controlar o robô aspirador de pó.
Outras habilidades do Alexa incluem coisas úteis, como pedir comida em uma variedade de restaurantes ou chamar um Uber, e diversões aleatórias, como fazer perguntas sobre a bola 8 mágica, curiosidades sobre Seinfeld e aprender novos fatos sobre frutas. As colaborações entre a Amazon e empresas como Whirlpool e GE também fortalecerão a aptidão de Alexa na casa inteligente, adicionando recursos para controlar eletrodomésticos como máquinas de lavar, geladeiras, lâmpadas e muito mais.
Atualmente, a Amazon parece estar na liderança neste mercado, mas outros estão fazendo grandes esforços (e investimentos) para alcançá-los. Mark Zuckerberg recrutou Morgan Freeman para ser a voz de seu assistente de voz de inteligência artificial (IA). De acordo com uma nota que descreve como ele o construiu, Zuckerberg passou um ano desenvolvendo o aplicativo como uma IA simples para ajudar a administrar sua casa “como Jarvis no Homem de Ferro” (ele também o chamou de Jarvis). Jarvis supostamente identifica quem está falando por sua voz e também reconhece rostos, para que possa permitir que pessoas autorizadas entrem enquanto se reporta a Zuckerberg.
Outro contendor interessante é um dispositivo semelhante ao Amazon-Echo japonês chamado Gatebox, que apresenta um personagem holográfico chamado Azuma Hikari.

A resposta do Japão ao Amazon Echo (Fonte:Gatebox)
Em cima de um simples alto-falante, o dispositivo utiliza uma tela e um projetor para dar vida ao assistente virtual tanto visual quanto audível. Além dos microfones, possui câmeras e sensores de movimento e temperatura que permitem uma interação mais holística com o usuário.
Como funciona a captação de voz de campo distante?
Como um dispositivo ouve e entende seus comandos de voz enquanto reproduz música do outro lado da sala? Existem muitos componentes envolvidos na habilitação desse talento, mas alguns deles são fundamentais. O primeiro é o mecanismo de reconhecimento automático de fala (ASR), que permite que as máquinas convertam os sons que fazemos em instruções executáveis. Para que o mecanismo ASR funcione corretamente, ele precisa receber uma amostra de voz limpa. Isso requer redução de ruído e cancelamento de eco, para filtrar as interferências. A seguir estão algumas das tecnologias mais importantes que permitem a captação de voz em campo distante:
Aprendizado profundo tem um grande papel nisso. A capacidade de entender a linguagem natural foi estabelecida há alguns anos, mas os refinamentos recentes a aproximaram da capacidade do nível humano. Usando técnicas baseadas em aprendizagem como Redes Neurais Profundas (DNNs), tanto o processamento de linguagem quanto o reconhecimento de objetos visuais igualaram ou superaram o desempenho humano em muitos casos de teste. DNNs são gerados usando conjuntos de dados massivos durante a fase de treinamento. Após o treinamento ter sido realizado offline, os DNNs são usados para desempenhar sua função em tempo real.
Adaptive Beamforming é a chave para uma interface de usuário robusta ativada por voz. Ele permite recursos como redução de ruído, rastreamento de alto-falante caso o usuário esteja se movendo enquanto fala e separação de alto-falante para quando vários usuários estiverem falando simultaneamente.
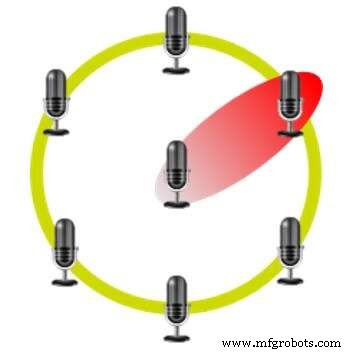
Beamforming usando uma matriz hexagonal de microfone (Fonte:CEVA)
Este método usa vários microfones em posições fixas em relação uns aos outros. Por exemplo, o Amazon Echo usa sete microfones em um layout hexagonal com um microfone em cada vértice e um no centro. O intervalo de tempo entre a recepção do sinal nos vários microfones permite que o dispositivo identifique de onde vem a voz e cancele sons vindos de outras direções.
Cancelamento de eco acústico é necessário porque muitos dos produtos que executam o reconhecimento automático de voz também produzem sons; por exemplo, tocar música ou fornecer informações. Mesmo durante a execução dessas ações, os dispositivos devem ser capazes de ouvir para que o usuário possa interromper (intrometer) e parar a música ou solicitar uma ação diferente. Para continuar ouvindo, a máquina deve ser capaz de cancelar o som que ela mesma gera. Isso é chamado de cancelamento de eco acústico (AEC).
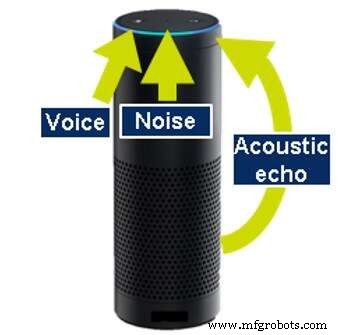
Cancelamento de eco acústico (Fonte:CEVA)
Para realizar o AEC, o dispositivo deve estar ciente do som que está fazendo, seja analisando os dados de saída ou ouvindo os sons gerados com um microfone adicional dedicado. Tecnologia semelhante também é aplicada para remover ecos que saltam de paredes e outros objetos ao redor do dispositivo.

Uma plataforma de desenvolvimento de vários microfones para modelar DNNs, formação de feixes e algoritmos de cancelamento de eco (Fonte:CEVA)
Outro tipo de eco é gerado pelos próprios comandos do usuário quando se recuperam de objetos ou das paredes. O cancelamento de tais ecos imprevisíveis requer ainda outro algoritmo denominado dereverberação. O som é então filtrado e a máquina pode escutar os comandos do usuário.
As interfaces de voz de hoje estão longe de ser perfeitas
Por um lado, 2017 parece ser um ano notável para as interfaces de voz, considerando o quão difundidas elas já se tornaram. Por outro lado, mesmo com todos os avanços impressionantes dos últimos anos, ainda há um longo caminho a percorrer.
Ainda existem muitos problemas com as implementações atuais de interfaces de voz em dispositivos produzidos em massa, mas esse será o tópico para uma coluna futura. Em minha próxima postagem, pretendo examinar algumas das falhas e recursos ausentes que afetam as interfaces de voz de hoje. Não se esqueça de sintonizar.
Eran Belaish é gerente de marketing de produto da linha de produtos de áudio e voz da CEVA, elaborando soluções requintadas que vão desde disparo por voz e voz móvel até áudio sem fio e áudio doméstico de alta definição. Embora não esteja ocupado com o fascinante mundo do som envolvente, Eran gosta de mergulhar no silêncio hipnotizante do mundo subaquático.
Como evitar que projetos baseados em FPGA se desviem
Otimizando a linha de alimentação RF no design de PCB
Integrado
- O CEO da Monroe Engineering é finalista em Empreendedor do Ano pela EY
- A interface da linha de comando
- MajorTom:Alexa Voice Controlled ARDrone 2.0
- Motion nomeado fornecedor do ano
- Mobius ganha o prêmio de Produto do Ano
- 2020 será o ano da inteligência contínua
- Tendências do CMMS 2019:o ano do cliente
- Monroe ganhou o negócio do ano 2019!
- O grande churrasco de pimentão de Wisconsin
- A Voz Unida da Indústria de Ar Comprimido