


Práticas recomendadas para depurar aplicativos IoT baseados em Zephyr
O Projeto de código aberto Zephyr da Linux Foundation se tornou a espinha dorsal de muitos projetos de IoT. A Zephyr oferece o melhor sistema operacional em tempo real (RTOS) pequeno, escalonável e otimizado para dispositivos com recursos limitados, em várias arquiteturas. O projeto atualmente tem 1.000 colaboradores e 50.000 commits construindo suporte avançado para múltiplas arquiteturas, incluindo ARC, Arm, Intel, Nios, RISC-V, SPARC e Tensilica, e mais de 250 placas.
Ao trabalhar com o Zephyr, existem algumas considerações críticas para manter as coisas conectadas e funcionando de forma confiável. Os desenvolvedores não conseguem resolver todos os tipos de problemas em suas mesas e alguns só se tornam óbvios quando o número de dispositivos aumenta. Conforme as redes e as pilhas de rede evoluem, você precisa garantir que as atualizações não introduzam problemas desnecessários.
Por exemplo, considere uma situação que enfrentamos com rastreadores GPS implantados para rastrear animais de fazenda. O dispositivo era um colar de pegada baixa baseado em sensor. Em qualquer dia, o animal vagava de rede móvel para rede móvel; de país para país; de local para local. Esse movimento expôs rapidamente configurações incorretas e comportamento inesperado que poderia levar à perda de energia, resultando em grande perda econômica. Não precisávamos apenas saber sobre um problema, precisávamos saber por que ele aconteceu e como corrigi-lo. Ao trabalhar com dispositivos conectados, o monitoramento remoto e a depuração são cruciais para obter uma visão instantânea do que deu errado, as próximas melhores etapas para resolver a situação e, em última análise, como estabelecer e manter a operação normal.
Usamos uma combinação de Zephyr e a plataforma de observabilidade de dispositivos baseada em nuvem Memfault para dar suporte ao monitoramento e atualização de dispositivos. Em nossa experiência, você pode aproveitar ambos para estabelecer as melhores práticas de monitoramento remoto usando reinicializações, watchdogs, falhas / declarações e métricas de conectividade.
Configurando uma plataforma de observação
Memfault permite aos desenvolvedores monitorar, depurar e atualizar firmware remotamente, o que nos permite:
- evite congelamentos de produção em favor de um produto mínimo viável e atualizações do dia 0
- monitorar continuamente a integridade geral do dispositivo
- enviar atualizações e patches antes que a maioria, se houver, os usuários finais percebam os problemas
O SDK do Memfault é facilmente integrado para coletar pacotes de dados para análise em nuvem e desduplicação de problemas. Ele funciona como um módulo Zephyr típico, onde você o adiciona ao seu arquivo de manifesto.
# west.yml [...] - nome:memfault-firmware-sdk url:https://github.com/memfault/memfault-firmware-sdk caminho:modules / memfault-firmware-sdk revisão:mestre # prj.conf CONFIG_MEMFAULT =y CONFIG_MEMFAULT_HTTP_ENABLE =y
Primeira área de foco:reinicializações
Suponha que você observe um aumento considerável nas reinicializações em seu dispositivo. Isso geralmente é um indicador precoce de que algo mudou na topologia ou os dispositivos estão começando a ter problemas devido a defeitos de hardware. É a menor informação que você pode coletar para começar a obter alguns insights sobre a integridade do dispositivo e ajuda pensar sobre isso em duas partes:redefinições de hardware e redefinições de software.
As redefinições de hardware são frequentemente causadas por watchdogs e brownouts do hardware. As redefinições de software podem ser causadas por atualizações de firmware, declarações ou iniciadas pelo usuário.
Depois de identificar quais tipos de reinicializações estão ocorrendo, podemos entender se há problemas que afetam toda a frota, ou se eles estão limitados a uma pequena porcentagem de dispositivos.
Registrar o motivo da reinicialização
vazio fw_update_finish (void) { // ... memfault_reboot_tracking_mark_reset_imminent (kMfltRebootReason_FirmwareUpdate, ...); sys_reboot (0); } Zephyr tem um mecanismo para registrar regiões que serão preservadas em uma reinicialização que o Memfault se conecta. Se você estiver prestes a reinicializar a plataforma, recomendamos salvar antes de começar. Ao reinicializar a plataforma, registre o motivo da reinicialização - neste caso, uma atualização de firmware - e chame-o de Zephyr sys_reboot.
Capturando redefinições de dispositivo no Zephyr
Registre o manipulador de inicialização para ler as informações de inicialização
estático int record_reboot_reason () { // 1. Leia o registro do motivo da reinicialização do hardware. (Verifique a folha de dados MCU para o nome de registro) // 2. Capture o motivo de reinicialização do software da RAM noinit // 3. Envie dados ao servidor para agregação } SYS_INIT (record_reboot_reason, APPLICATION, CONFIG_KERNEL_INIT_PRIORITY_DEFAULT); Você pode configurar uma macro que captura informações do sistema antes de redefinir por meio do registro de motivo de redefinição de MCU. Quando o dispositivo for reiniciado, o Zephyr registrará manipuladores usando a macro system_int. Todos os registros de motivo de reinicialização de MCU têm nomes ligeiramente diferentes e todos são úteis porque você pode ver se há algum problema ou defeito de hardware.
Exemplo:problema com fonte de alimentação
Vejamos um exemplo de como o monitoramento remoto pode fornecer informações vitais sobre a integridade da frota, observando as reinicializações e o fornecimento de energia. Aqui, podemos ver um pequeno número de dispositivos responsáveis por mais de 12.000 reinicializações (Figura 1).
clique para ver a imagem em tamanho real

Figura 1:Exemplo de problema com a fonte de alimentação, gráfico de reinicializações ao longo de 15 dias. (Fonte:Autores)
- 12K reinicializações do dispositivo por dia - demasiadas
- 99% das reinicializações feitas por 10 dispositivos
- Parte mecânica ruim, contribuindo para reinicializações constantes do dispositivo
Nesse caso, alguns dispositivos estão reiniciando 1.000 vezes por dia, provavelmente devido a um problema mecânico (peça ruim, contato ruim da bateria ou vários problemas crônicos de taxa).
Uma vez que os dispositivos estão em produção, você pode lidar com vários desses problemas por meio de atualizações de firmware. A implementação de uma atualização permite contornar os defeitos de hardware e evitar a necessidade de tentar recuperar e substituir dispositivos.
Segunda área de enfoque:cães de guarda
Ao trabalhar com pilhas conectadas, um watchdog é a última linha de defesa para colocar o sistema de volta em um estado de limpeza sem reinicializar manualmente o dispositivo. Os bloqueios podem acontecer por vários motivos, como
- Blocos de pilha de conectividade no envio ()
- Loops de repetição infinitos
- Deadlocks entre tarefas
- Corrupção
Os watchdogs de hardware são um periférico dedicado no MCU que deve ser “alimentado” periodicamente para evitar que reiniciem o dispositivo. Os watchdogs do software são implementados no firmware e disparam antes do watchdog do hardware para permitir a captura do estado do sistema que leva ao watchdog do hardware
Zephyr tem uma API de watchdog de hardware onde todos os MCUs podem passar pela API genérica para instalar e configurar o watchdog na plataforma. (Veja Zephyr API para mais detalhes:zephyr / include / drivers / watchdog.h)
// ... vazio start_watchdog (void) { // consulte a árvore de dispositivos para watchdog de hardware disponível s_wdt =device_get_binding (DT_LABEL (DT_INST (0, nordic_nrf_watchdog))); struct wdt_timeout_cfg wdt_config ={ / * Redefina o SoC quando o cronômetro do watchdog expirar. * / .flags =WDT_FLAG_RESET_SOC, / * Expira watchdog após a janela máxima * / .window.min =0U, .window.max =WDT_MAX_WINDOW, }; s_wdt_channel_id =wdt_install_timeout (s_wdt, &wdt_config); const uint8_t options =WDT_OPT_PAUSE_HALTED_BY_DBG; wdt_setup (s_wdt, opções); // TODO:Iniciar um watchdog de software } vazio feed_watchdog (void) { wdt_feed (s_wdt, s_wdt_channel_id); // TODO:Watchdog do software de feed } Vamos percorrer algumas etapas usando este exemplo do nRF9160 nórdico.
- Vá para a árvore de dispositivos e configure a pasta de watchtime Nordic nRF.
- Defina as opções de configuração do watchdog por meio da API exposta.
- Instale o watchdog.
- Periodicamente, alimente o watchdog quando os comportamentos estiverem funcionando conforme o esperado. Às vezes, isso é feito a partir das tarefas de prioridade mais baixa. Se o sistema estiver travado, ele será reiniciado.
Usando Memfault no Zephyr, você pode fazer uso de temporizadores do kernel, alimentados por um periférico temporizador. Você pode definir o tempo limite do watchdog do software para estar à frente do watchdog do hardware (por exemplo, defina o watchdog do hardware para 60 segundos e o watchdog do software para 50 segundos). Se o retorno de chamada for invocado, um assert será disparado, o que o levará através do manipulador de falhas do Zephyr e obterá informações sobre o que estava acontecendo naquele momento em que o sistema estava travado.
Exemplo:Driver SPI travado
Voltemos novamente a um exemplo de um problema que não é detectado no desenvolvimento, mas surge no campo. Na Figura 2 você pode ver o tempo, os fatos e a degradação dos chips de driver SPI.
clique para ver a imagem em tamanho real
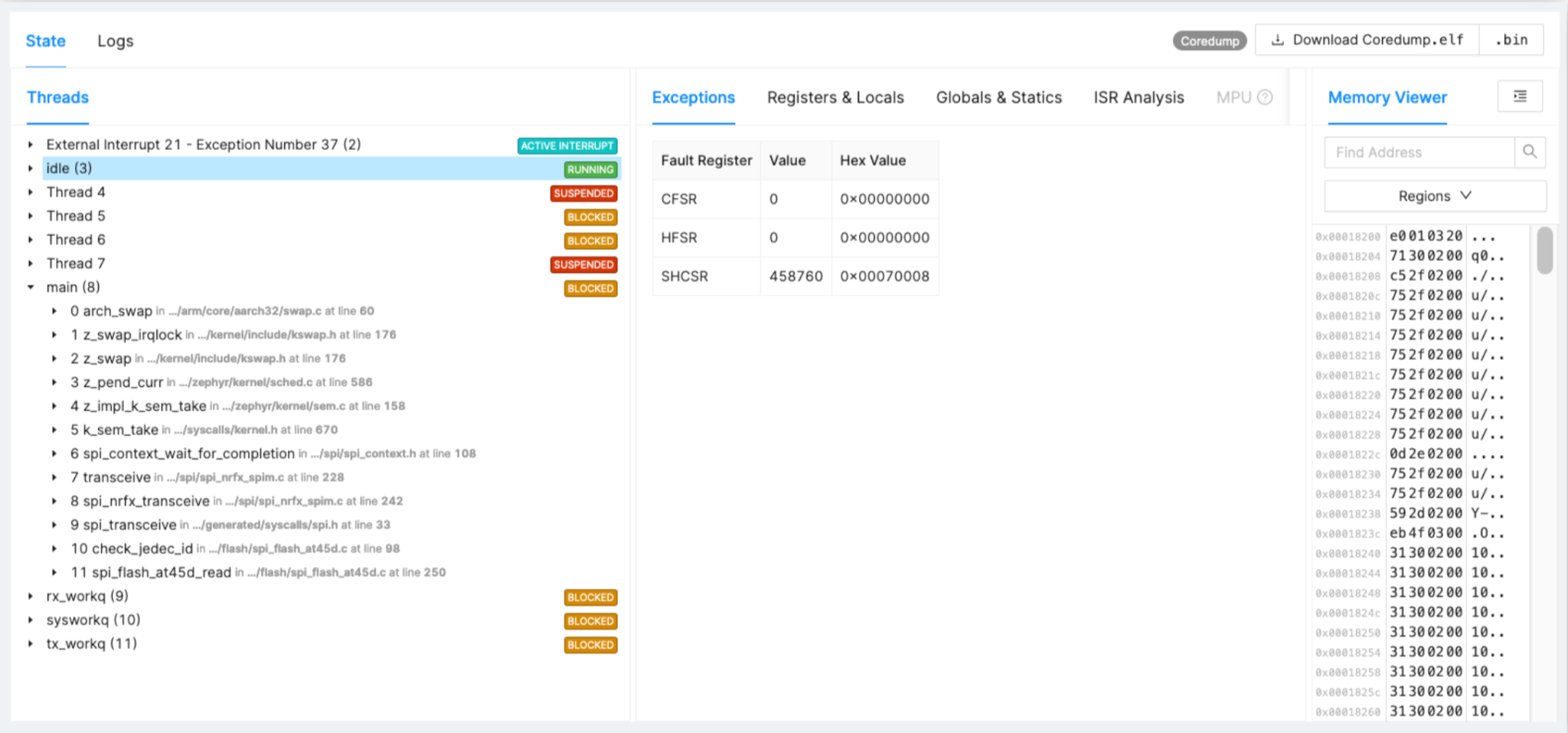
Figura 2:Exemplo de driver SPI travado. (Fonte:Autores)
- SPI flash degradando ao longo do tempo, tempo incorreto de comunicação
- Rastreado em 1% dos dispositivos após 16 meses de implantação em campo
- Correção e implementação do driver na próxima versão
Para o Flash, depois de um ano no campo, você pode ver que há um início repentino de erros devido ao travamento em transações SPI ou vários bits e pedaços de código. Ter o rastreamento completo ajuda a encontrar a causa raiz e desenvolver uma solução.
O watchdog abaixo (Figura 3) está iniciando o manipulador de falhas Zephyr.
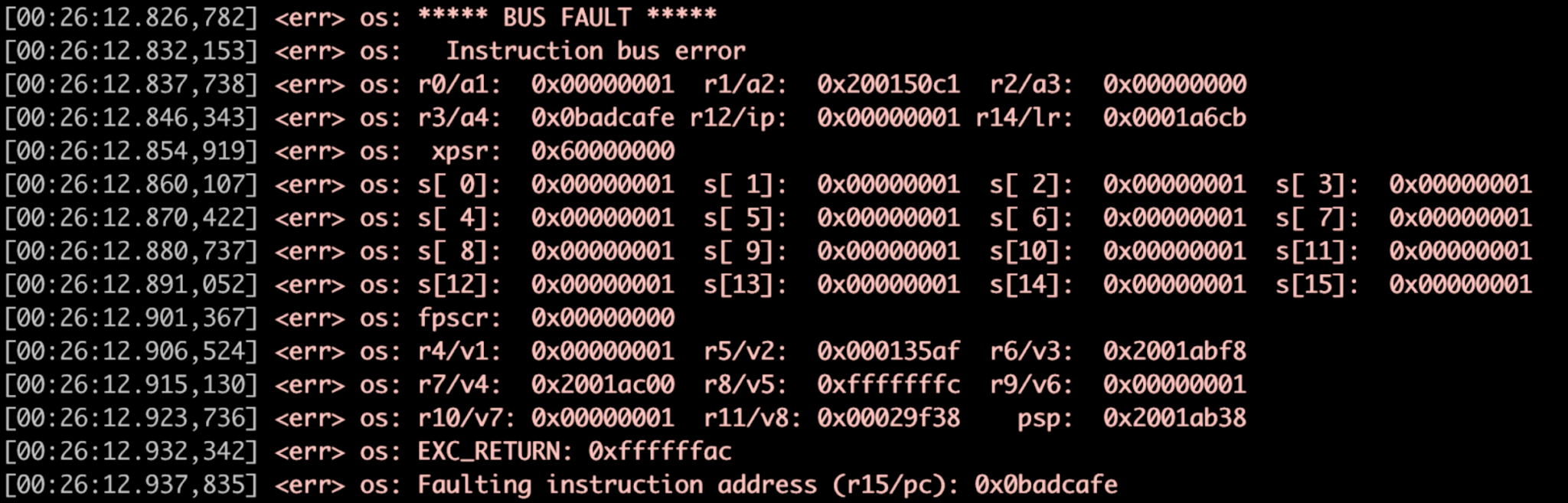
Figura 3:Exemplo de manipulador de falhas, registro de despejo. (Fonte:Autores)
Foco da terceira área:Falhas / afirmações:
O terceiro componente a rastrear são as falhas e afirmações. Se você já fez alguma depuração local ou construiu alguns recursos próprios, provavelmente viu uma tela semelhante sobre o estado de registro quando uma falha ocorreu na plataforma. Isso pode ser devido a:
- afirma, ou
- acessando memória ruim
- divisão por zero
- usando um periférico da maneira errada
Aqui está um exemplo de um fluxo de tratamento de falhas que ocorre em microcontroladores Cortex M no Zephyr.
vazio network_send (vazio) { const size_t packet_size =1500; void * buffer =z_malloc (packet_size); // faltando verificação NULL! memcpy (buffer, 0x0, packet_size); // ... } ↓ vazio network_send (vazio) { const size_t packet_size =1500; void * buffer =z_malloc (packet_size); // faltando verificação NULL! memcpy (buffer, 0x0, packet_size); // ... } ↓ bool memfault_coredump_save (const sMemfaultCoredumpSaveInfo * save_info) { // Salvar estado de registro // Salvar _kernel e contextos de tarefa // Salvar regiões .bss e .data selecionadas } ↓ vazio sys_arch_reboot (tipo interno) { // ... } Quando uma declaração ou falha é acionada, uma interrupção é acionada e um manipulador de falha é invocado no Zephyr que fornece o estado do registro no momento da falha.
O Memfault SDK é integrado automaticamente ao fluxo de tratamento de falhas, salvando informações críticas na nuvem, incluindo o estado do registro, o estado do kernel e uma parte de todas as tarefas em execução no sistema no momento da falha.
Há três coisas a serem observadas ao depurar local ou remotamente:
- O registro de status de falha do Cortex M informa por que a plataforma foi declarada ou falha.
- Memfault recupera a linha exata de código que o sistema estava executando antes da falha e o estado de todas as outras tarefas.
- Colete o _kernel estrutura no Zephyr RTOS para ver o escalonador e, se for um aplicativo conectado, o estado dos parâmetros Bluetooth ou LTE.
Quarta área de enfoque:métricas de rastreamento para capacidade de observação do dispositivo
As métricas de rastreamento permitem que você comece a construir um padrão do que está acontecendo em seu sistema e permite que você faça comparações entre seus dispositivos e sua frota para entender quais mudanças estão tendo um impacto.
Algumas métricas úteis para rastrear são:
- utilização da CPU
- parâmetros de conectividade
- uso de calor
Com o Memfault SDK, você pode adicionar e começar a definir métricas no Zephyr com duas linhas de código:
- Definir métrica
MEMFAULT_METRICS_KEY_DEFINE ( LteDisconnect, kMemfaultMetricType_Unsigned)
- Atualizar métrica no código
vazio lte_disconnect (void) { memfault_metrics_heartbeat_add ( MEMFAULT_METRICS_KEY (LteDisconnect), 1); // ... } Memfault SDK + Cloud
- Serializa e compacta métricas para transporte
- Indexa métricas por dispositivo e versão de firmware
- Mostra a interface da web para navegar nas métricas por dispositivo e em toda a frota
Dezenas de métricas podem ser coletadas e indexadas por dispositivo e versão de firmware. Alguns exemplos:
- Conectividade básica NB-IoT / LTE-M: Veja como um modem afeta a vida útil da bateria, ao ser conectado ou conectado.
- Rastreamento de estações base e PSM em NB-IoT / LTE-M: A qualidade do sinal móvel pode ser dolorosa e pode esgotar a vida útil da bateria se não for gerenciada. Crie métricas para status de rede, eventos, informações de torre de celular, configurações, temporizadores e muito mais. Monitore as mudanças e use alertas.
- Testando grandes frotas: Dados inesperadamente grandes podem aumentar os custos de conectividade do dispositivo e ajudar a identificar valores discrepantes.
Exemplo:tamanho dos dados NB-IoT / LTE-M
clique para ver a imagem em tamanho real
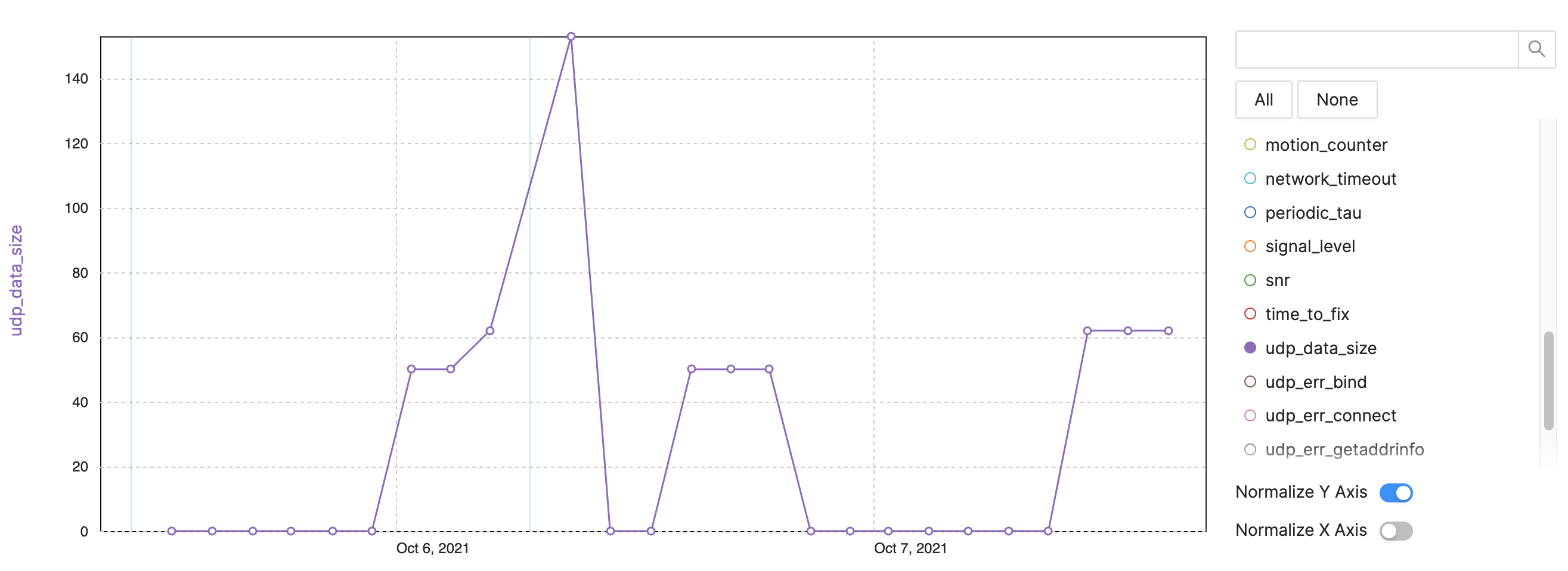
Figura 4:Métricas de rastreamento para observabilidade do dispositivo - exemplo NB-IoT, tamanho dos dados LTE-M. (Fonte:Autores)
- Tamanho dos dados UDP:bytes de rastreamento por intervalo de envio (Figura 4)
- Após a reinicialização, mais dados são enviados
- Alguns pacotes são maiores devido a mais informações ou rastros
- Rastreie o problema de consumo de dados
Conclusão
Aproveitando o Zephyr e o Memfault, os desenvolvedores podem implementar o monitoramento remoto para obter uma melhor capacidade de observação na funcionalidade do dispositivo conectado. Concentrando-se em reinicializações, watchdogs, falhas / declarações e métricas de conectividade, os desenvolvedores podem otimizar o custo e o desempenho dos sistemas IoT.
Saiba mais assistindo a uma apresentação gravada do 2021 Zephyr Developer Summit.
Tecnologia da Internet das Coisas
- Práticas recomendadas para monitoramento sintético
- Transceptores bidirecionais 1G para provedores de serviços e aplicativos de IoT
- ETSI se move para definir padrões para aplicativos de IoT em comunicações de emergência
- IIC e TIoTA colaboram nas melhores práticas de IoT/Blockchain
- NIST publica recomendações preliminares de segurança para fabricantes de IoT
- Parceria visa a vida útil infinita da bateria do dispositivo IoT
- 3 melhores razões para usar a tecnologia IoT para gerenciamento de ativos
- Por que considerar a IoT a melhor plataforma para monitoramento ambiental?
- Melhores aplicações para sistemas de ar comprimido
- Práticas recomendadas de marketing de fabricação para 2019