


Princípios de Engenharia de Confiabilidade para o Engenheiro de Fábrica

Cada vez mais, gerentes e engenheiros responsáveis pela fabricação e outras atividades industriais estão incorporando um foco de confiabilidade em seus planos e iniciativas estratégicas e táticas. Essa tendência está afetando várias áreas funcionais, incluindo projeto e aquisição de máquinas / sistemas, operações e manutenção de fábricas.
Com suas origens na indústria de aviação, a engenharia de confiabilidade, como uma disciplina, historicamente tem se concentrado principalmente em garantir a confiabilidade do produto. Cada vez mais, esses métodos estão sendo empregados para garantir a confiabilidade da produção de instalações e equipamentos de manufatura - geralmente como um facilitador para a manufatura enxuta. Este artigo fornece uma introdução ao mais relevante e prático desses métodos para engenharia de confiabilidade de planta, incluindo:
- Cálculos básicos de confiabilidade para taxa de falha, MTBF, disponibilidade, etc.
- Uma introdução à distribuição exponencial - a pedra angular dos métodos de confiabilidade.
- Identificar dependências de tempo de falha usando o sistema Weibull versátil.
- Desenvolvendo um sistema eficaz de coleta de dados de campo.
História da engenharia de confiabilidade
As origens do campo da engenharia de confiabilidade, pelo menos a demanda por ela, podem ser rastreadas até o ponto em que o homem começou a depender de máquinas para seu sustento. A Noria, por exemplo, é uma bomba antiga considerada a primeira máquina sofisticada do mundo. Utilizando a energia hidráulica do fluxo de um rio ou riacho, os Noria utilizavam baldes para transferir água para calhas, viadutos e outros dispositivos de distribuição para irrigar campos e fornecer água às comunidades.
Se a comunidade Noria falhasse, as pessoas que dependiam dela para seu suprimento de alimentos corriam risco. A sobrevivência sempre foi uma grande fonte de motivação para confiabilidade e segurança.
Embora as origens de sua demanda sejam antigas, a engenharia da confiabilidade como uma disciplina técnica realmente floresceu junto com o crescimento da aviação comercial após a Segunda Guerra Mundial. Ficou rapidamente claro para os gerentes de empresas do setor de aviação que os acidentes são ruins para os negócios. Karen Bernowski, editora de Quality Progress , revelado em uma de suas pesquisas editoriais sobre o valor da morte na mídia por vários meios, conduzida pelo professor de estatística do MIT, Arnold Barnett, e relatada em 1994.
Barnett avaliou o número de artigos de primeira página do New York Times por 1.000 mortes por vários meios. Ele descobriu que as mortes relacionadas ao câncer geraram 0,02 artigos de primeira página por 1.000 mortes, os homicídios geraram 1,7 por 1.000 mortes, a AIDS gerou 2,3 por 1.000 mortes e os acidentes de aviação geraram colossais 138,2 artigos por 1.000 mortes!
O custo e a natureza de alto perfil dos acidentes relacionados à aviação ajudaram a motivar a indústria da aviação a participar fortemente no desenvolvimento da disciplina de engenharia de confiabilidade. Da mesma forma, devido à natureza crítica do equipamento militar na defesa, técnicas de engenharia de confiabilidade têm sido empregadas há muito tempo para garantir a prontidão operacional. Muitos de nossos padrões no campo da engenharia de confiabilidade são padrões MIL ou têm suas origens em atividades militares.
O que é engenharia de confiabilidade?
A engenharia de confiabilidade trata da longevidade e confiabilidade de peças, produtos e sistemas. Mais dolorosamente, trata-se de controlar o risco. A engenharia de confiabilidade incorpora uma ampla variedade de técnicas analíticas projetadas para ajudar os engenheiros a entender os modos e padrões de falha dessas peças, produtos e sistemas. Tradicionalmente, o campo da engenharia de confiabilidade tem se concentrado na confiabilidade do produto e na garantia da confiabilidade.
Nos últimos anos, as organizações que implantam máquinas e outros ativos físicos em ambientes de produção começaram a implantar vários princípios de engenharia de confiabilidade para fins de confiabilidade de produção e garantia de confiabilidade.
Cada vez mais, as organizações de produção implantam técnicas de engenharia de confiabilidade como Manutenção Centrada em Confiabilidade (RCM), incluindo modos de falha e análise de efeitos (e criticidade) (FMEA, FMECA), análise de causa raiz (RCA), manutenção baseada em condições, esquemas de planejamento de trabalho aprimorados, etc. Essas mesmas organizações estão começando a adotar estratégias de aquisição e projeto com base no custo do ciclo de vida, esquemas de gerenciamento de mudanças e outras ferramentas e técnicas avançadas para controlar as causas básicas da baixa confiabilidade.
No entanto, a adoção de aspectos mais quantitativos da engenharia de confiabilidade pela comunidade de garantia de confiabilidade de produção tem sido lenta. Isso se deve em parte à percepção da complexidade das técnicas e em parte à dificuldade em obter dados úteis.
Os aspectos quantitativos da engenharia de confiabilidade podem, superficialmente, parecer complicados e assustadores. Na realidade, no entanto, uma compreensão relativamente básica dos métodos mais fundamentais e amplamente aplicáveis pode permitir ao engenheiro de confiabilidade da planta obter uma compreensão muito mais clara sobre onde os problemas estão ocorrendo, sua natureza e seu impacto no processo de produção - pelo menos no quantitativo senso.
Usados adequadamente, os métodos e ferramentas de engenharia de confiabilidade quantitativa permitem que a engenharia de confiabilidade da planta aplique com mais eficácia as estruturas fornecidas por RCM, RCA, etc., eliminando algumas das conjecturas envolvidas com sua aplicação de outra forma. No entanto, os engenheiros devem ser particularmente espertos na aplicação dos métodos.
Por quê? O contexto operacional e o ambiente de um processo de produção incorporam mais variáveis do que o mundo um tanto unidimensional da garantia da confiabilidade do produto. Isso se deve à influência combinada da engenharia de projeto, aquisição, produção / operações, manutenção, etc., e à dificuldade em criar testes e experimentos eficazes para modelar os aspectos multidimensionais de um ambiente de produção típico.
Apesar da crescente dificuldade na aplicação de métodos de confiabilidade quantitativos no ambiente de produção, vale a pena obter uma compreensão sólida das ferramentas e aplicá-las quando apropriado. Os dados quantitativos ajudam a definir a natureza e a magnitude de um problema / oportunidade, o que fornece uma visão da confiabilidade em sua aplicação de outras ferramentas de engenharia de confiabilidade.
Este artigo fornecerá uma introdução aos métodos mais básicos de engenharia de confiabilidade aplicáveis ao engenheiro de fábrica interessado na garantia da confiabilidade da produção. Pressupõe uma compreensão básica da álgebra, teoria da probabilidade e estatísticas univariadas com base na distribuição gaussiana (normal) (por exemplo, medida de tendência central, medidas de dispersão e variabilidade, intervalos de confiança, etc.).
Deve ficar claro que este artigo é uma breve introdução aos métodos de confiabilidade. Não é de forma alguma um levantamento abrangente dos métodos de engenharia de confiabilidade, nem é de forma alguma novo ou não convencional. Os métodos descritos neste documento são usados rotineiramente por engenheiros de confiabilidade e são conceitos básicos de conhecimento para aqueles que buscam a certificação profissional pela American Society for Quality (ASQ) como engenheiro de confiabilidade (CRE).
Vários livros sobre engenharia de confiabilidade estão listados na bibliografia deste artigo. O autor deste artigo encontrou Métodos de confiabilidade para engenheiros por K.S. Krishnamoorthi e Estatísticas de confiabilidade por Robert Dovich para serem referências particularmente úteis e amigáveis no assunto de métodos de engenharia de confiabilidade. Ambos são publicados pela ASQ Press.
Antes de discutir os métodos, você deve se familiarizar com a nomenclatura da engenharia de confiabilidade. Por conveniência, uma lista resumida dos principais termos e definições é fornecida no apêndice deste artigo. Para uma definição mais exaustiva de termos de confiabilidade e nomenclatura, consulte MIL-STD-721 e outros padrões relacionados. As definições contidas no apêndice são do MIL-STD-721.
Conceitos matemáticos básicos em engenharia de confiabilidade
Muitos conceitos matemáticos se aplicam à engenharia de confiabilidade, principalmente nas áreas de probabilidade e estatística. Da mesma forma, muitas distribuições matemáticas podem ser usadas para vários fins, incluindo a distribuição Gaussiana (normal), a distribuição log-normal, a distribuição Rayleigh, a distribuição exponencial, a distribuição Weibull e uma série de outras.
Para o propósito desta breve introdução, limitaremos nossa discussão à distribuição exponencial e à distribuição Weibull, as duas mais amplamente aplicadas à engenharia de confiabilidade. No interesse da brevidade e simplicidade, conceitos matemáticos importantes, como adequação de distribuição e intervalos de confiança foram excluídos.
Taxa de falha e tempo médio entre / até a falha (MTBF / MTTF)
O objetivo das medições de confiabilidade quantitativa é definir a taxa de falha em relação ao tempo e modelar essa taxa de falha em uma distribuição matemática com o objetivo de compreender os aspectos quantitativos da falha. O bloco de construção mais básico é a taxa de falha, que é estimada usando a seguinte equação:

Onde:
λ =Taxa de falha (às vezes chamada de taxa de risco)
T =Tempo total de funcionamento / ciclos / milhas / etc. durante um período de investigação para itens com e sem falha.
r =O número total de falhas ocorridas durante o período de investigação.
Por exemplo, se cinco motores elétricos operam por um tempo total coletivo de 50 anos com cinco falhas funcionais durante o período, a taxa de falha é de 0,1 falhas por ano.
Outro conceito muito básico é o tempo médio entre / até a falha (MTBF / MTTF). A única diferença entre MTBF e MTTF é que empregamos MTBF quando nos referimos a itens que são reparados quando falham. Para itens que são simplesmente jogados fora e substituídos, usamos o termo MTTF. Os cálculos são os mesmos.
O cálculo básico para estimar o tempo médio entre a falha (MTBF) e o tempo médio até a falha (MTTF), ambas medidas de tendência central, é simplesmente o recíproco da função de taxa de falha. É calculado usando a seguinte equação.

Onde:
θ =Tempo médio entre / até a falha
T =Tempo total de funcionamento / ciclos / milhas / etc. durante um período de investigação para itens com e sem falha.
r =O número total de falhas ocorridas durante o período de investigação.
O MTBF para nosso exemplo de motor elétrico industrial é de 10 anos, que é o inverso da taxa de falha dos motores. A propósito, estimaríamos o MTBF para motores elétricos reconstruídos em caso de falha. Para motores menores considerados descartáveis, declararíamos a medida de tendência central como MTTF.
A taxa de falha é um componente básico de muitos cálculos de confiabilidade mais complexos. Dependendo do projeto mecânico / elétrico, contexto operacional, ambiente e / ou eficácia da manutenção, a taxa de falha de uma máquina em função do tempo pode diminuir, permanecer constante, aumentar linearmente ou aumentar geometricamente (Figura 1). A importância da taxa de falha em relação ao tempo será discutida com mais detalhes posteriormente.
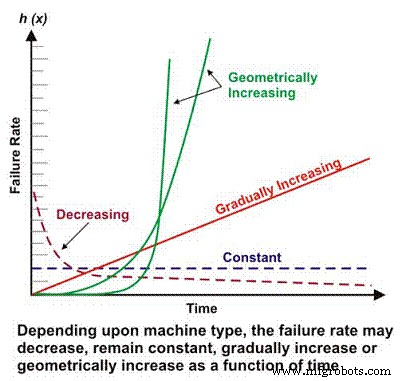
Figura 1. Diferentes taxas de falha vs. cenários de tempo
A curva de ‘banheira’
Os indivíduos que receberam apenas treinamento básico em probabilidade e estatística estão provavelmente mais familiarizados com a distribuição normal ou gaussiana, que está associada à conhecida curva de densidade de probabilidade em forma de sino. A distribuição gaussiana é geralmente aplicável a conjuntos de dados onde as duas medidas mais comuns de tendência central, média e mediana, são aproximadamente iguais.
Surpreendentemente, apesar da versatilidade da distribuição gaussiana na modelagem de probabilidades para fenômenos que variam de pontuações de testes padronizados aos pesos de nascimento de bebês, não é a distribuição dominante empregada na engenharia de confiabilidade. A distribuição gaussiana tem seu lugar na avaliação das características de falha de máquinas com um modo de falha dominante, mas a distribuição primária empregada na engenharia de confiabilidade é a distribuição exponencial.
Ao avaliar a confiabilidade e as características de falha de uma máquina, devemos começar com a muito difamada curva da “banheira”, que reflete a taxa de falha em relação ao tempo (Figura 2). Em conceito, a curva da banheira demonstra efetivamente as três características básicas da taxa de falha de uma máquina:decrescente, constante ou crescente. Lamentavelmente, a curva da banheira foi duramente criticada na literatura de engenharia de manutenção porque falha em modelar efetivamente a taxa de falha característica para a maioria das máquinas em uma planta industrial, o que geralmente é verdadeiro no nível macro.
A maioria das máquinas passa a vida no início da vida, ou na mortalidade infantil, e / ou nas regiões de taxa de falha constante da curva da banheira. Raramente vemos falhas sistêmicas baseadas no tempo em máquinas industriais. Apesar de suas limitações na modelagem das taxas de falha de máquinas industriais típicas, a curva da banheira é uma ferramenta útil para explicar os conceitos básicos da engenharia de confiabilidade.
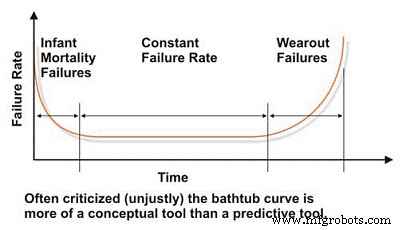
Figura 2. A muito difamada curva de 'Banheira'
O corpo humano é um excelente exemplo de sistema que segue a curva da banheira. As pessoas, e outras espécies orgânicas, tendem a sofrer uma alta taxa de falha (mortalidade) durante os primeiros anos de vida, principalmente nos primeiros anos, mas a taxa diminui à medida que a criança cresce. Supondo que uma pessoa atinja a puberdade e sobreviva à adolescência, sua taxa de mortalidade torna-se razoavelmente constante e permanece lá até que as doenças dependentes da idade (tempo) comecem a aumentar a taxa de mortalidade (desgaste).
Numerosas influências afetam as taxas de mortalidade, incluindo cuidados pré-natais e nutrição da mãe, qualidade e disponibilidade de cuidados médicos, meio ambiente e nutrição, opções de estilo de vida e, claro, predisposição genética. Esses fatores podem ser comparados metaforicamente a fatores que influenciam a vida útil da máquina. Projeto e aquisição são análogos à predisposição genética; a instalação e o comissionamento são análogos ao cuidado pré-natal e nutrição da mãe; e as escolhas de estilo de vida e a disponibilidade de cuidados médicos são análogos à eficácia da manutenção e ao controle proativo sobre as condições de operação.
A distribuição exponencial
A distribuição exponencial, a fórmula de previsão de confiabilidade mais básica e amplamente usada, modela máquinas com taxa de falha constante ou a seção plana da curva da banheira. A maioria das máquinas industriais passa a maior parte de suas vidas com uma taxa de falhas constante, por isso é amplamente aplicável. Abaixo está a equação básica para estimar a confiabilidade de uma máquina que segue a distribuição exponencial, onde a taxa de falha é constante em função do tempo.

Onde:
R (t) =Estimativa de confiabilidade para um período de tempo, ciclos, milhas, etc. (t).
e =Base dos logaritmos naturais (2,718281828)
λ =Taxa de falha (1 / MTBF, ou 1 / MTTF)
Em nosso exemplo de motor elétrico, se você assumir uma taxa de falha constante, a probabilidade de operar um motor por seis anos sem falha, ou a confiabilidade projetada, é de 55 por cento. Isso é calculado da seguinte forma:
R (6) =2,718281828- (0,1 * 6)
R (6) =0,5488 =~ 55%
Em outras palavras, depois de seis anos, cerca de 45% da população de motores idênticos operando em uma aplicação idêntica pode, probabilisticamente, falhar. Vale a pena reiterar neste ponto que esses cálculos projetam a probabilidade de uma população. Qualquer indivíduo da população pode falhar no primeiro dia de operação, enquanto outro indivíduo pode durar 30 anos. Essa é a natureza das projeções de confiabilidade probabilística.
Uma característica da distribuição exponencial é que o MTBF ocorre no ponto em que a confiabilidade calculada é de 36,78%, ou no ponto em que 63,22% das máquinas já falharam. Em nosso exemplo de motor, após 10 anos, 63,22% dos motores de uma população de motores idênticos servindo em aplicações idênticas podem falhar. Ou seja, a sobrevida é de 36,78% da população.
Freqüentemente, falamos da vida projetada do rolamento como a vida L10. Este é o momento em que se espera que 10% de uma população de rolamentos falhe (taxa de sobrevivência de 90%). Na realidade, apenas uma fração dos rolamentos realmente sobrevive até o ponto L10. Chegamos a aceitar isso como a vida objetiva de um rolamento quando talvez devêssemos nos concentrar no ponto L63.22, indicando que nossos rolamentos duram, em média, o MTBF projetado - assumindo, é claro, que os rolamentos siga a distribuição exponencial. Discutiremos esse problema mais tarde na seção de análise de Weibull do artigo.
A função de densidade de probabilidade (pdf), ou distribuição de vida, é uma equação matemática que aproxima a distribuição de frequência de falha. É a fdp, ou distribuição de freqüência de vida, que produz a conhecida curva em forma de sino na distribuição gaussiana ou normal. Abaixo está o pdf para a distribuição exponencial.

Onde:
pdf (t) =Distribuição da frequência de vida para um determinado tempo (t)
e =Base dos logaritmos naturais (2,718281828)
λ =Taxa de falha (1 / MTBF, ou 1 / MTTF)
Em nosso exemplo de motor elétrico, a probabilidade real de falha em três anos é calculada da seguinte forma:
pdf (3) =01. * 2,718281828- (0,1 * 3)
pdf (3) =0,1 * 0,7408
pdf (3) =0,07408 =~ 7,4%
Em nosso exemplo, se assumirmos uma taxa de falha constante, que segue a distribuição exponencial, a distribuição de vida, ou pdf para os motores elétricos industriais, é expressa na Figura 3. Não se confunda com a natureza decrescente da função pdf. Sim, a taxa de falha é constante, mas o pdf matematicamente assume falha sem reposição, então a população da qual as falhas podem ocorrer está continuamente reduzindo - assintoticamente se aproximando de zero.
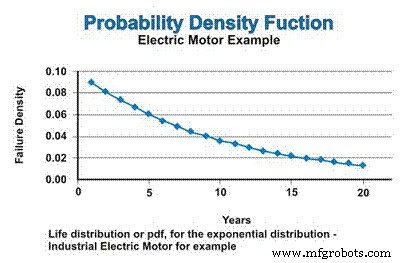
Figura 3. A função de densidade de probabilidade (pdf)
A função de distribuição cumulativa (cdf) é simplesmente o número cumulativo de falhas que se pode esperar ao longo de um período de tempo. Para a distribuição exponencial, a taxa de falha é constante, então a taxa relativa na qual os componentes com falha são adicionados ao cdf permanece constante. No entanto, como a população diminui como resultado de falhas, o número real de falhas matematicamente estimadas diminui em função da população em declínio. Assim como o pdf assintoticamente se aproxima de zero, o cdf assintoticamente se aproxima de um (Figura 4).
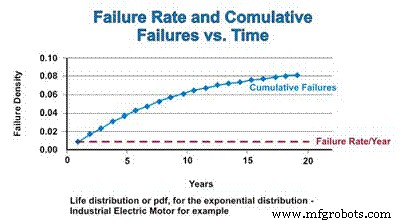
Figura 4. Taxa de falhas e a função de distribuição cumulativa
A porção decrescente da taxa de falha da curva da banheira, que geralmente é chamada de região de mortalidade infantil, e a região de desgaste serão discutidas na seção seguinte, abordando a distribuição versátil de Weibull.
Distribuição Weibull
Desenvolvido originalmente por Wallodi Weibull, um matemático sueco, a análise de Weibull é facilmente a distribuição mais versátil empregada por engenheiros de confiabilidade. Embora seja chamada de distribuição, é na verdade uma ferramenta que permite ao engenheiro de confiabilidade primeiro caracterizar a função de densidade de probabilidade (distribuição de frequência de falha) de um conjunto de dados de falha para caracterizar as falhas como vida precoce, constante (exponencial) ou desgaste (Gaussiano ou log normal) plotando dados de tempo até a falha em um papel de plotagem especial com o log dos tempos / ciclos / milhas até a falha plotados em um eixo X em escala logarítmica versus a porcentagem cumulativa da população representada por cada falha em um log eixo Y com escala de -log (Figura 5).
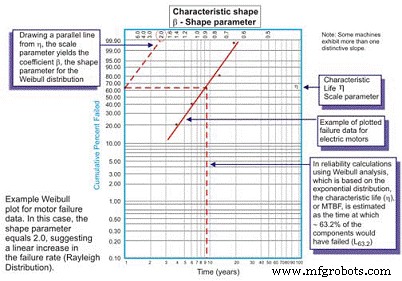
Figura 5. O gráfico simples de Weibull - anotado
Uma vez traçada, a inclinação linear da curva resultante é uma variável importante, chamada de parâmetro de forma, representada por â, que é usada para ajustar a distribuição exponencial para caber um grande número de distribuições de falha. Em geral, se o coeficiente â, ou parâmetro de forma, for menor que 1,0, a distribuição exibe falhas no início da vida ou na mortalidade infantil. Se o parâmetro de forma exceder cerca de 3,5, os dados são dependentes do tempo e indicam falhas de desgaste.
Este conjunto de dados normalmente assume a distribuição gaussiana ou normal. À medida que o coeficiente â aumenta acima de ~ 3,5, a distribuição em forma de sino se estreita, exibindo curtose crescente (pico no topo da curva) e um desvio padrão menor. Muitos conjuntos de dados exibirão duas ou até três regiões distintas.
É comum para engenheiros de confiabilidade plotar, por exemplo, uma curva que representa o parâmetro de forma durante a execução e outra curva para representar a taxa de falha constante ou crescente. Em alguns casos, uma terceira inclinação linear distinta emerge para identificar uma terceira forma, a região de desgaste.
Nesses casos, a pdf dos dados de falha de fato assume a conhecida forma de curva de banheira (Figura 6). A maioria dos equipamentos mecânicos usados nas fábricas, entretanto, exibe uma região de mortalidade infantil e uma região de taxa de falha constante ou crescente. É raro ver surgir uma curva representando o desgaste. A vida característica, ou η (grego minúsculo “Eta”), é a aproximação de Weibull do MTBF. É sempre em função do tempo, milhas ou ciclos onde falham 63,21% das unidades em avaliação, que é o MTBF / MTTF para a distribuição exponencial.
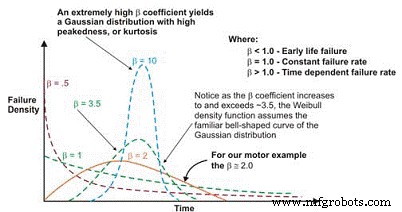
Figura 6. Dependendo do parâmetro de forma, a densidade de falha de Weibull curve pode assumir várias distribuições, o que a torna tão versátil para engenharia de confiabilidade.
Como uma ressalva para amarrar esta ferramenta à excelência em manutenção e excelência em operações, se quiséssemos controlar de forma mais eficaz as funções de forçamento que levam a falhas mecânicas em rolamentos, engrenagens, etc., como lubrificação, controle de contaminação, alinhamento, equilíbrio, operação apropriada, etc., mais máquinas atingiriam sua vida útil de fadiga. As máquinas que atingem sua vida útil de fadiga exibem a característica de desgaste familiar.
Usar o coeficiente β para ajustar a equação da taxa de falha como uma função do tempo produz a seguinte equação geral:

Onde:
h (t) =Taxa de falha (ou taxa de risco) para um determinado tempo (t)
e =Base dos logaritmos naturais (2,718281828)
θ =MTBF / MTTF estimado
β =Parâmetro de forma de Weibull do gráfico.
E, a seguinte função de confiabilidade:
Onde:
R (t) =Estimativa de confiabilidade para um período de tempo, ciclos, milhas, etc. (t)
e =Base dos logaritmos naturais (2,718281828)
θ =MTBF / MTTF estimado
β =Parâmetro de forma de Weibull do gráfico.
E, a seguinte função de densidade de probabilidade (pdf):
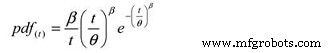
Onde:
pdf (t) =Estimativa da função de densidade de probabilidade para um período de tempo,
ciclos, milhas, etc. (t)
e =Base dos logaritmos naturais (2,718281828)
θ =MTBF / MTTF estimado
β =Parâmetro de forma de Weibull do gráfico.
Deve-se notar que quando o β é igual a 1,0, a distribuição Weibull assume a forma da distribuição exponencial na qual se baseia.
Para os não iniciados, a matemática necessária para realizar a análise Weibull pode parecer assustadora. Mas, uma vez que você entende a mecânica das fórmulas, a matemática é realmente muito simples. Além disso, o software fará a maior parte do trabalho para nós hoje, mas é importante ter uma compreensão da teoria subjacente para que o engenheiro de confiabilidade da planta possa implementar com eficácia a poderosa técnica de análise de Weibull.
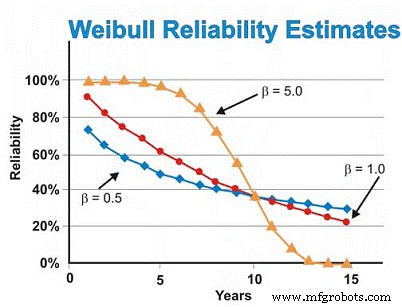
Em nosso exemplo de motores elétricos discutido anteriormente, assumimos anteriormente a distribuição exponencial. No entanto, se a análise de Weibull revelou falhas no início da vida, gerando um parâmetro de forma β de 0,5, a estimativa de confiabilidade em seis anos seria de ~ 46%, e não de ~ 55% estimados assumindo a distribuição exponencial. A fim de reduzir as falhas de desgaste, precisaríamos confiar em nossos fornecedores para fornecer qualidade e confiabilidade mais bem construídas e entregues, armazenar os motores melhor para evitar ferrugem, corrosão, atrito e outros mecanismos de desgaste estático e fazer um trabalho melhor de instalação e inicializando máquinas novas ou reconstruídas.
Por outro lado, se a análise de Weibull revelou que os motores exibiram predominantemente falhas relacionadas ao desgaste, produzindo um parâmetro de forma β de 5,0, a estimativa de confiabilidade em seis anos seria de ~ 93%, em vez dos ~ 55% estimados assumindo a distribuição exponencial. Para falhas de desgaste dependentes do tempo, podemos realizar uma revisão ou substituição programada assumindo que temos uma boa estimativa do MTBF / MTTF após atingirmos a região de desgaste e um desvio padrão suficientemente pequeno para tomar decisões de reconstrução / substituição de alta confiança que não são excessivamente caros.
Em nosso exemplo de motor, assumindo um parâmetro de forma β de 5,0, a taxa de falha começa a aumentar rapidamente após cerca de cinco ou seis anos, então podemos querer editar nossos dados para focar apenas na região de desgaste ao estimar a substituição ou reconstrução com base no tempo Tempo. Alternativamente, podemos melhorar o projeto, visando o (s) modo (s) de falha dominante (s) com o objetivo de diminuir as interferências de “tensão-força”. Em outras palavras, podemos tentar eliminar as fragilidades da máquina por meio da modificação do projeto, com o objetivo de eliminar o que quer que esteja causando as falhas dependentes do tempo.
Assumindo que tudo é constante, exceto o parâmetro de forma β, a Figura 7 ilustra a diferença que o parâmetro de forma β tem na estimativa de confiabilidade assumindo valores de forma β de 0,5 (início da vida), 1,0 (constante ou exponencial) e 5,0 (desgaste) para uma gama de estimativas de tempo. Este gráfico ilustra visualmente o conceito de risco crescente em relação ao tempo (β =0,5), risco constante em relação ao tempo (β =1,0) e risco crescente em relação ao tempo (β =5).
Figura 7. Várias projeções de confiabilidade em função do tempo para diferentes Parâmetros de forma de Weibull
O gráfico de Weibull com múltiplas inclinações
Freqüentemente, ao traçar uma linha de regressão de melhor ajuste através dos pontos de dados em um gráfico Weibull, o coeficiente de correlação é pobre, significando que os pontos de dados reais estão muito distantes da linha de regressão. Isso é avaliado examinando o coeficiente de correlação R, ou mais conservadoramente, R2, que denota a variabilidade dos dados. Quando a correlação é fraca, o engenheiro de confiabilidade deve examinar os dados para avaliar se existem dois ou mais padrões, o que pode denotar grandes diferenças nos modos de falha, contexto operacional, etc. Freqüentemente, isso produz duas ou mais estimativas de beta (Figura 8).
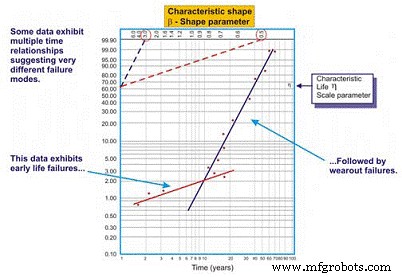
Figura 8. Um exemplo de gráfico Weibull multi-beta
Como vemos em nosso exemplo na Figura 8, o conjunto de dados funciona melhor quando duas linhas de regressão distintas são desenhadas. A primeira linha exibe um parâmetro de forma beta de 0,5, sugerindo falhas no início da vida. A segunda linha exibe uma forma beta de 3,0, sugerindo que o risco de falha aumenta em função do tempo. É comum que equipamentos complexos, especialmente equipamentos mecânicos, apresentem falhas de "run-in" quando novos ou reconstruídos recentemente. Assim, o risco de falha é maior logo após a inicialização.
Uma vez que o sistema funciona durante seu período de rodagem, que pode levar minutos, horas, dias, semanas, meses ou anos, dependendo do tipo de sistema, o sistema entra em um padrão de risco diferente. Neste exemplo, o sistema entra em um período em que o risco de falha aumenta em função do tempo, uma vez que o sistema sai do período de rodagem.
O multi-beta oferece ao engenheiro de confiabilidade uma estimativa mais precisa do risco em função do tempo. Armado com esse conhecimento, ele ou ela está melhor posicionado para tomar ações atenuantes. Por exemplo, durante o período inicial de vida, estaríamos inclinados a melhorar a precisão com a qual fabricamos / reconstruímos, instalamos e inicializamos. Além disso, podemos adicionar técnicas de monitoramento e / ou aumentar nossa frequência de monitoramento durante o período de alto risco. Após o período de rodagem, podemos introduzir técnicas de monitoramento que são direcionadas às falhas de desgaste dependentes do tempo que se acredita afetam o sistema, aumentar a frequência de monitoramento de acordo ou programar ações de manutenção preventiva "difícil" em alguns casos.
Estimando a confiabilidade do sistema
Uma vez que a confiabilidade dos componentes ou máquinas tenha sido estabelecida em relação ao contexto operacional e ao tempo de missão exigido, os engenheiros da fábrica devem avaliar a confiabilidade de um sistema ou processo. Novamente, por uma questão de brevidade e simplicidade, discutiremos as estimativas de confiabilidade do sistema para sistemas redundantes em série, paralelo e de carga compartilhada (sistemas r / n).
Sistemas em série
Antes de discutir os sistemas em série, devemos discutir os diagramas de blocos de confiabilidade. Não sendo uma ferramenta complicada de usar, os diagramas de blocos de confiabilidade simplesmente mapeiam um processo do início ao fim. Para um sistema em série, o subsistema A é seguido pelo subsistema B e assim por diante. No sistema em série, a capacidade de empregar o Subsistema B depende do estado operacional do Subsistema A. Se o Subsistema A não estiver operando, o sistema está inativo, independentemente da condição do Subsistema B (Figura 9).
Para calcular a confiabilidade do sistema para um processo serial, você só precisa multiplicar a confiabilidade estimada do Subsistema A no tempo (t) pela confiabilidade estimada do Subsistema B no tempo (t). A equação básica para calcular a confiabilidade do sistema de um sistema de série simples é:
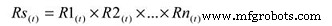
Where:
Rs(t) – System reliability for given time (t)
R1-n(t) – Subsystem or sub-function reliability for given time (t)
So, for a simple system with three subsystems, or sub-functions, each having an estimated reliability of 0.90 (90%) at time (t), the system reliability is calculated as 0.90 X 0.90 X 0.90 =0.729, or about 73%.
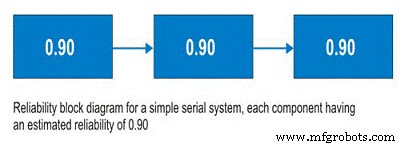
Figure 9. Simple Serial System
Parallel Systems
Often, design engineers will incorporate redundancy into critical machines. Reliability engineers call these parallel systems. These systems may be designed as active parallel systems or standby parallel systems. The block diagram for a simple two component parallel system is shown in Figure 10.
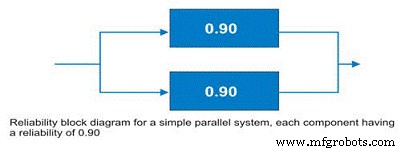
Figure 10. Simple parallel system – the system reliability is increased to 99% due to the redundancy.
To calculate the reliability of an active parallel system, where both machines are running, use the following simple equation:
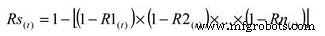
Where:
Rs(t) – System reliability for given time (t)
R1-n(t) – Subsystem or sub-function reliability for given time (t)
The simple parallel system in our example with two components in parallel, each having a reliability of 0.90, has a total system reliability of 1 – (0.1 X 0.1) =0.99. So, the system reliability was significantly improved.
There are some shortcut methods for calculating parallel system reliability when all subsystems have the same estimated reliability. More often, systems contain parallel and serial subcomponents as depicted in Figure 11. The calculation of standby systems requires knowledge about the reliability of the switching mechanism. In the interest of simplicity and brevity, this topic will be reserved for a future article.
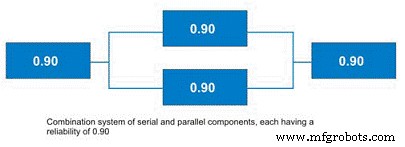
Figure 11. Combination System with Parallel and Serial Elements
r out of n Systems (r/n Systems)
An important concept to plant reliability engineers is the concept of r/n systems. These systems require that r units from a total population in n be available for use. A great industrial example is coal pulverizers in an electric power generating plant. Often, the engineers design this function in the plant using an r/n approach. For instance, a unit has four pulverizers and the unit requires that three of the four be operable to run at the unit’s full load (see Figure 12).
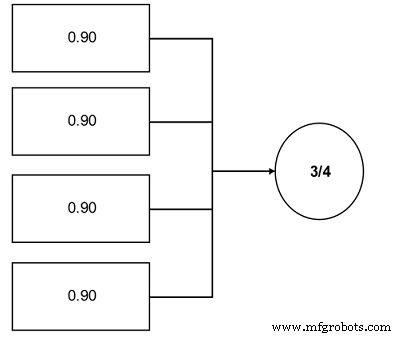
Figure 12. Simple r/n system example – Three of the four components are required.
The reliability calculation for an r/n system can be reduced to a simple cumulative binomial distribution calculation, the formula for which is:
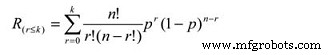
Where:
Rs =System reliability given the actual number of failures (r) is less than or equal the maximum allowable (k)
r =The actual number of failures
k =The maximum allowable number of failures
n =The total number of units in the system
p =The probability of survival, or the subcomponent reliability for a given time (t).
This equation is somewhat more complicated. In our pulverizer example, assuming a subcomponent reliability of 0.90, the equation works out as a summation of the following:
P(0) =0.6561
P(1) =0.2916
So, the likelihood of completing the mission time (t) is 0.9477 (0.6561 + 0.2916), or approximately 95%.
Field Data Collection
To employ the reliability analysis methods described herein, the engineer requires data. It is imperative to establish field data collection systems to support your reliability management initiatives. Likewise, as much as possible, you’ll want to employ common nomenclature and units so that your data can be parsed effectively for more detailed analysis. Collect the following information:
- Basic System Information
- Operating Context
- Environmental Context
- Failure Data
A good general system for data collection is described in the IEC standard 300-3-2. In addition to providing instructions for collecting field data, it provides a standard taxonomy of failure modes. Other taxonomies have been established, but the IEC standard represents a good starting point for your organization to define its own. Likewise, DOE standard NE-1004-92 offers a very nice standard nomenclature of failure causes.
An important benefit derived from your efforts to collect good field data is that it enables you to break the “random trap.” As I mentioned earlier, the bathtub curve has been much maligned – particularly in the Reliability-Centered Maintenance literature. While it’s true that Weibull analysis reveals that few complex mechanical systems exhibit time-dependent wearout failures, the reason, at least in part, is due to the fact that the reliability of complex systems is affected by a wide variety of failure modes and mechanisms.
When these are lumped together, there is a “randomizing” effect, which makes the failures appear to lack any time dependency. However, if the failure modes were analyzed individually, the story would likely be very different (Figure 13). For certain, some failure modes would still be mathematically random, but many, and arguably most, would exhibit a time dependency. This kind of information would arm reliability engineers and managers with a powerful set of options for mitigating failure risk with a high degree of precision. Naturally, this ability depends upon the effective collection and subsequent analysis of field data.
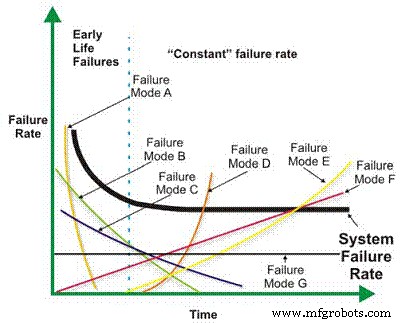
Figure 13. Good field data collection enables you to break the random trap.
This brief introduction to reliability engineering methods is intended to expose the otherwise uninitiated plant engineer to the world of quantitative reliability engineering. The subject is quite broad, however, and I’ve only touched on the major reliability methods that I believe are most applicable to the plant engineer. I encourage you to further investigate the field of reliability engineering methods, concentrating on the following topics, among others:
-
More detailed understanding of the Weibull distribution and its applications
-
More detailed understanding of the exponential distribution and its applications
-
The Gaussian distribution and its applications
-
The log-normal distribution and its applications
-
Confidence intervals (binomial, chi-square/Poisson, etc.)
-
Beta distribution and its applications
-
Bayesian applications of reliability engineering methods
-
Stress-strength interference analysis
-
Testing options and their applicability to plant reliability engineering
-
Reliability growth strategies and management
-
More detailed understanding of field data collection.
Most important, spend time learning how to apply reliability engineering methods to plant reliability problems. If your interest in reliability engineering methods is high, I encourage you to pursue professional certification by the American Society for Quality as a reliability engineer (CRE).
References
Troyer, D. (2006) Strategic Plant Reliability Management Course Book, Noria Publishing, Tulsa, Oklahoma.
Bernowski, K (1997) “Safety in the Skies,” Quality Progress , January.
Dovich, R. (1990) Reliability Statistics, ASQ Quality Press, Milwaukee, WI.
Krishnamoorthi, K.S. (1992) Reliability Methods for Engineers, ASQ Quality Press , Milwaukee, WI.
MIL Standard 721
IEC Standard 300-3-3
DOE Standard NE-1004-92
Appendix:Select reliability engineering terms from MIL STD 721
Availability – A measure of the degree to which an item is in the operable and committable state at the start of the mission, when the mission is called for at an unknown state.
Capability – A measure of the ability of an item to achieve mission objectives given the conditions during the mission.
Dependability – A measure of the degree to which an item is operable and capable of performing its required function at any (random) time during a specified mission profile, given the availability at the start of the mission.
Failure – The event, or inoperable state, in which an item, or part of an item, does not, or would not, perform as previously specified.
Failure, dependent – Failure which is caused by the failure of an associated item(s). Not independent.
Failure, independent – Failure which occurs without being caused by the failure of any other item. Not dependent.
Failure mechanism – The physical, chemical, electrical, thermal or other process which results in failure.
Failure mode – The consequence of the mechanism through which the failure occurs, i.e. short, open, fracture, excessive wear.
Failure, random – Failure whose occurrence is predictable only in the probabilistic or statistical sense. This applies to all distributions.
Failure rate – The total number of failures within an item population, divided by the total number of life units expended by that population, during a particular measurement interval under stated conditions.
Maintainability – The measure of the ability of an item to be retained or restored to specified condition when maintenance is performed by personnel having specified skill levels, using prescribed procedures and resources, at each prescribed level of maintenance and repair.
Maintenance, corrective – All actions performed, as a result of failure, to restore an item to a specified condition. Corrective maintenance can include any or all of the following steps:localization, isolation, disassembly, interchange, reassembly, alignment and checkout.
Maintenance, preventive – All actions performed in an attempt to retain an item in a specified condition by providing systematic inspection, detection and prevention of incipient failures.
Mean time between failure (MTBF) – A basic measure of reliability for repairable items:the mean number of life units during which all parts of the item perform within their specified limits, during a particular measurement interval under stated conditions.
Mean time to failure (MTTF) – A basic measure of reliability for non-repairable items:The mean number of life units during which all parts of the item perform within their specified limits, during a particular measurement interval under stated conditions.
Mean time to repair (MTTR) – A basic measure of maintainability:the sum of corrective maintenance times at any specified level of repair, divided by the total number of failures within an item repaired at that level, during a particular interval under stated conditions.
Mission reliability – The ability of an item to perform its required functions for the duration of specified mission profile.
Confiabilidade – (1) The duration or probability of failure-free performance under stated conditions. (2) The probability that an item can perform its intended function for a specified interval under stated conditions. For non-redundant items this is the equivalent to definition (1). For redundant items, this is the definition of mission reliability.
Manutenção e reparo de equipamentos
- O caso para manutenção móvel:Fiix para pelo podcast Asset Reliability @ Work
- Qual é a função do engenheiro de confiabilidade?
- LCE oferece confiabilidade para curso de gerentes
- A chave nº 1 para o sucesso da confiabilidade
- RH:O elo que faltava para a confiabilidade
- O lado não técnico da confiabilidade
- Práticas recomendadas para limpeza de tintas ecológicas ao redor da planta
- Alimento para o pensamento:Evite a visão de túnel na planta
- Total Corbion PLA em estágio de engenharia para nova planta de PLA na Europa
- O futuro da engenharia de manutenção