


Como aumentar a precisão de uma rede neural de camada oculta
Neste artigo, vamos realizar alguns experimentos de classificação e reunir dados sobre a relação entre a dimensionalidade da camada oculta e o desempenho da rede.
Neste artigo, você aprenderá como modificar uma camada oculta para melhorar a precisão da rede neural usando uma implementação Python e exemplos de problemas.
Antes de avançarmos para esse assunto, no entanto, considere colocar em dia as entradas anteriores desta série sobre redes neurais:
- Como realizar a classificação usando uma rede neural:o que é o Perceptron?
- Como usar um exemplo de rede neural simples Perceptron para classificar dados
- Como treinar uma rede neural Perceptron básica
- Compreendendo o treinamento de rede neural simples
- Uma introdução à teoria de treinamento para redes neurais
- Compreendendo a taxa de aprendizagem em redes neurais
- Aprendizado de máquina avançado com o Multilayer Perceptron
- A função de ativação sigmóide:ativação em redes neurais multicamadas Perceptron
- Como treinar uma rede neural multicamadas Perceptron
- Noções básicas sobre fórmulas de treinamento e retropropagação para percepções multicamadas
- Arquitetura de rede neural para uma implementação Python
- Como criar uma rede neural multicamadas Perceptron em Python
- Processamento de sinais usando redes neurais:validação no projeto de redes neurais
- Conjuntos de dados de treinamento para redes neurais:como treinar e validar uma rede neural Python
- Quantas camadas e nós ocultos uma rede neural precisa?
- Como aumentar a precisão de uma rede neural de camada oculta
O número de nós incluídos em uma camada oculta influencia a capacidade de classificação e a velocidade de uma rede neural Perceptron. Faremos experimentos que nos ajudarão a formular alguma intuição incipiente sobre como a dimensionalidade da camada oculta se encaixa na tentativa de projetar uma rede que treina dentro de um período de tempo razoável, produz valores de saída com latência aceitável e atende aos requisitos de precisão .
Comparativo em Python
O código Python da rede neural apresentado na Parte 12 já inclui uma seção que calcula a precisão usando a rede treinada para classificar amostras de um conjunto de dados de validação. Portanto, tudo o que precisamos fazer é adicionar algum código que relatará o tempo de execução do treinamento (que inclui a operação de feedforward e retropropagação) e para a funcionalidade de classificação real (que inclui apenas a operação de feedforward). Usaremos o time.perf_counter () função para isso.
É assim que marco o início e o fim do treinamento:
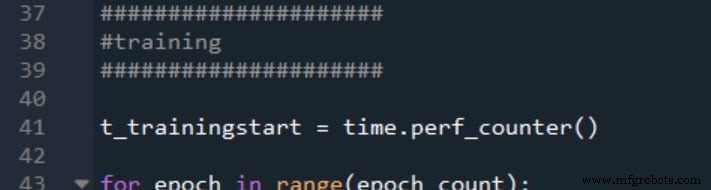
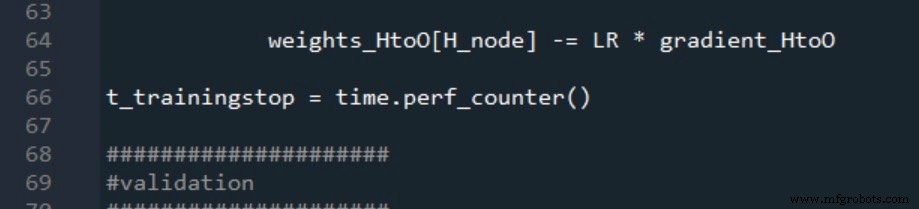
Os horários de início e término da validação são gerados da mesma maneira:
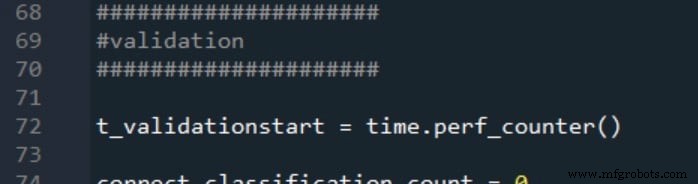

As duas medições de tempo de processamento são relatadas da seguinte forma:
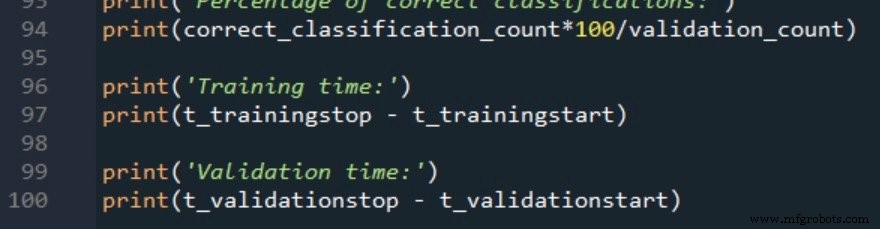
Dados de treinamento e procedimento de medição
A rede neural realizará a classificação verdadeiro / falso em amostras de entrada que consistem em quatro valores numéricos entre –20 e +20.
Assim, temos quatro nós de entrada e um nó de saída, e os valores de entrada são gerados com a equação do Excel mostrada abaixo.
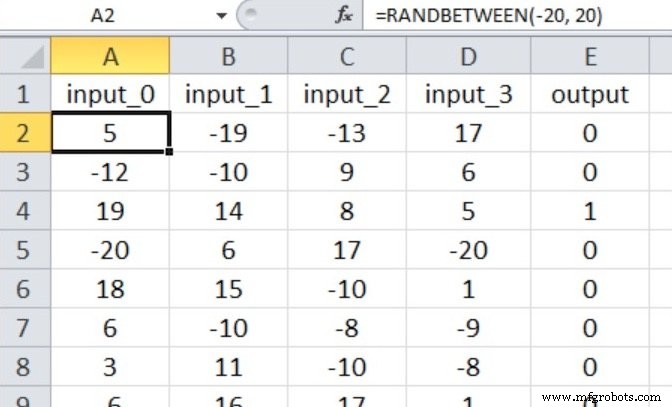
Meu conjunto de dados de treinamento consiste em 40.000 amostras e o conjunto de validação possui 5.000 amostras. A taxa de aprendizado é de 0,1 e estou realizando apenas um período de treinamento.
Faremos três experimentos que representam relações de entrada-saída com vários graus de complexidade. O np.random.seed (1) declaração é comentada, portanto, os valores de peso inicial irão variar e, portanto, a precisão da classificação também.
Em cada experimento, o programa será executado cinco vezes (com os mesmos dados de treinamento e validação) para cada dimensionalidade da camada oculta, e as medidas finais de precisão e tempo de processamento serão a média aritmética dos resultados gerados pelas cinco execuções separadas .
Experimento 1:um problema de baixa complexidade
Neste experimento, a saída é verdadeira apenas se as três primeiras entradas forem maiores que zero, conforme mostrado na captura de tela do Excel abaixo (observe que a quarta entrada não tem efeito no valor de saída).
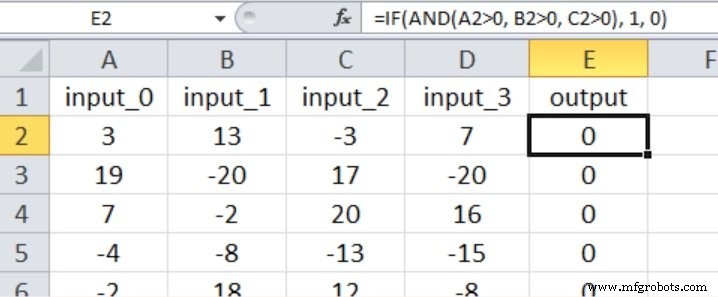
Acho que isso se qualifica como uma relação de entrada-saída bastante simples para um Perceptron multicamadas.
Com base nas recomendações que forneci na Parte 15 sobre quantas camadas e nós uma rede neural precisa, eu começaria com uma dimensionalidade de camada oculta igual a dois terços da dimensionalidade de entrada.
Como não posso ter uma camada oculta com uma fração de um nó, começarei em H_dim =2 . A tabela a seguir apresenta os resultados.
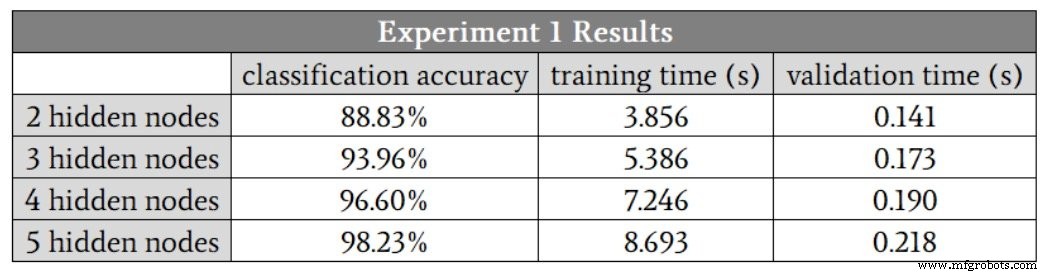
Vemos melhorias na classificação até cinco nós ocultos. No entanto, acho que esses números exageram o benefício de aumentar de quatro para cinco nós, porque a precisão de uma das execuções de quatro nós ocultos foi de 88,6%, e isso diminuiu a média.
Se eu eliminar essa execução de baixa precisão, a precisão média para quatro nós ocultos é, na verdade, ligeiramente maior do que a média para cinco nós ocultos. Suspeito que, neste caso, quatro nós ocultos fornecerão o melhor equilíbrio entre precisão e velocidade.
Outra coisa importante a se notar nesses resultados é a diferença em como a dimensionalidade da camada oculta afeta o tempo de treinamento e o tempo de processamento. Mover de dois para quatro nós ocultos aumenta o tempo de validação por um fator de 1,3, mas aumenta o tempo de treinamento por um fator de 1,9.
O treinamento é significativamente mais intensivo em termos de computação do que o processamento feedforward, portanto, precisamos estar particularmente atentos a como a configuração da rede influencia nossa capacidade de treinar a rede em um período de tempo razoável.
Experimento 2:um problema de complexidade moderada
A captura de tela do Excel mostra a relação de entrada-saída para este experimento. Todas as quatro entradas agora influenciam o valor de saída e as comparações são menos diretas do que eram no Experimento 1.
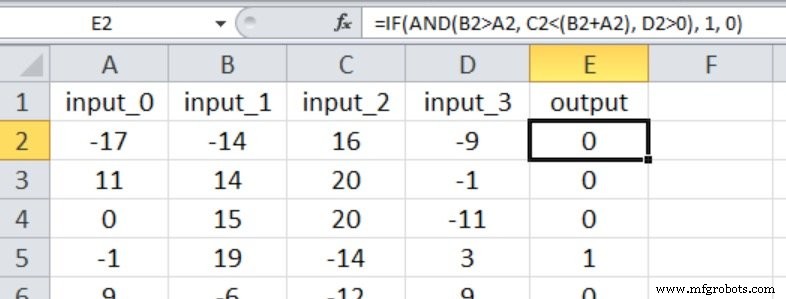
Comecei com três nós ocultos. Aqui estão os resultados:
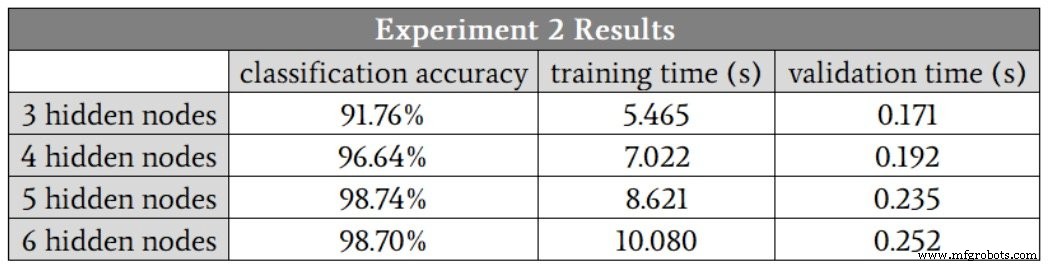
Nesse caso, suspeito que cinco nós ocultos nos darão a melhor combinação de precisão e velocidade, embora, mais uma vez, as execuções de quatro nós ocultos tenham produzido um valor de precisão significativamente menor do que os outros. Se você ignorar esse valor atípico, os resultados para quatro nós ocultos, cinco nós ocultos e seis nós ocultos serão muito semelhantes.
O fato de que as execuções de cinco nós ocultos e seis nós ocultos não geraram quaisquer valores discrepantes nos leva a uma descoberta possível interessante:talvez o aumento da dimensionalidade da camada oculta torne a rede mais robusta contra condições que, por algum motivo, fazem com que o treinamento ser particularmente difícil.
Experimento 3:um problema de alta complexidade
Conforme mostrado abaixo, o novo relacionamento de entrada-saída inclui novamente todos os quatro valores de entrada e introduzimos a não linearidade elevando ao quadrado uma das entradas e obtendo a raiz quadrada de outra.
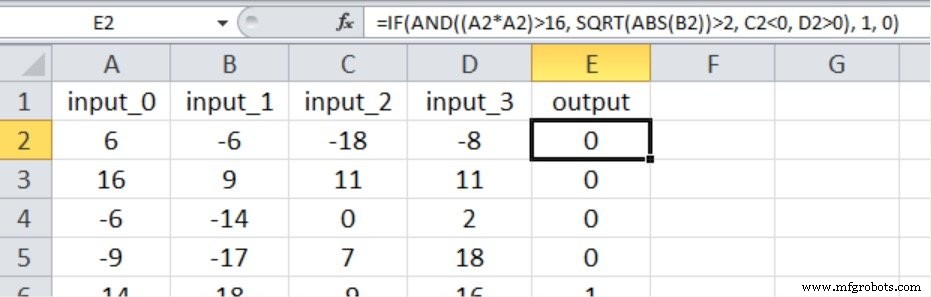
Aqui estão os resultados:
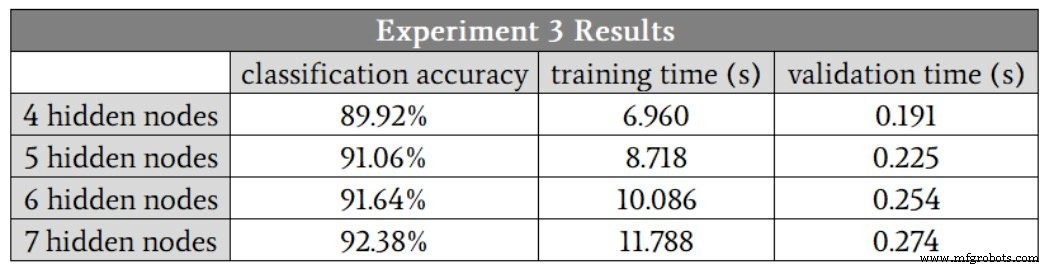
A rede definitivamente tinha mais dificuldade com esse relacionamento matemático de alta complexidade; mesmo com sete nós ocultos, a precisão foi menor do que alcançamos com apenas três nós ocultos no problema de baixa complexidade. Estou confiante de que poderíamos melhorar o desempenho de alta complexidade modificando outros aspectos da rede, por exemplo, incluindo um viés (consulte a Parte 11) ou anulando a taxa de aprendizagem (consulte a Parte 6).
No entanto, eu manteria a dimensionalidade da camada oculta em sete até estar totalmente convencido de que outros aprimoramentos poderiam permitir que a rede mantivesse o desempenho adequado com uma camada oculta menor.
Conclusão
Vimos algumas medições interessantes que pintam um quadro bastante claro da relação entre a dimensionalidade da camada oculta e o desempenho do Perceptron. Certamente há muitos outros detalhes que poderíamos explorar, mas acho que isso fornece algumas informações básicas sólidas que você pode usar quando estiver fazendo experiências com design e treinamento de redes neurais.
Robô industrial
- Quantas camadas e nós ocultos uma rede neural precisa?
- Conjuntos de dados de treinamento para redes neurais:como treinar e validar uma rede neural Python
- Como Criar uma Rede Neural Perceptron Multicamadas em Python
- Arquitetura de rede neural para uma implementação Python
- Como treinar uma rede neural Perceptron multicamadas
- Como o ecossistema de rede está mudando o futuro da fazenda
- Protegendo a IoT da camada de rede à camada de aplicativo
- Como Thomas WebTrax difere do Google Analytics, The Thomas Network e mais
- Como os sensores de rede 0G protegem a cadeia de frio da vacina
- Como escolher o sistema de corte a laser certo para maximizar a produtividade e a precisão