


Como construir um codificador automático variacional com TensorFlow
Ao longo dos anos, vimos muitos campos e indústrias aproveitarem o poder da inteligência artificial (IA) para expandir os limites da pesquisa. A compressão e reconstrução de dados não é exceção, onde a aplicação de inteligência artificial pode ser usada para construir sistemas mais robustos.
Neste artigo, veremos um caso de uso muito popular de IA para compactar dados e reconstruir os dados compactados com um codificador automático.
Aplicativos Autoencoder
Os codificadores automáticos têm ganhado a atenção de muitas pessoas no aprendizado de máquina, fato que ficou evidente por meio do aprimoramento dos codificadores automáticos e da invenção de diversas variantes. Eles produziram alguns resultados promissores (se não de última geração) em vários campos, como tradução automática neural, descoberta de drogas, eliminação de ruído de imagens e vários outros.
Partes do codificador automático
Autoencoders, como a maioria das redes neurais, aprendem propagando gradientes para trás para otimizar um conjunto de pesos - mas a diferença mais notável entre a arquitetura dos autoencoders e a da maioria das redes neurais é um gargalo. Esse gargalo é um meio de compactar nossos dados em uma representação de dimensões inferiores. Duas outras partes importantes de um codificador automático são o codificador e o decodificador.
A fusão desses três componentes forma um autoencoder "vanilla", embora os mais sofisticados possam ter alguns componentes adicionais.
Vamos dar uma olhada nesses componentes independentemente.
Codificador
Este é o primeiro estágio de compactação e reconstrução de dados e, na verdade, cuida do estágio de compactação de dados. O codificador é uma rede neural feed-forward que recebe recursos de dados (como pixels no caso de compactação de imagem) e produz um vetor latente com um tamanho menor que o tamanho dos recursos de dados.
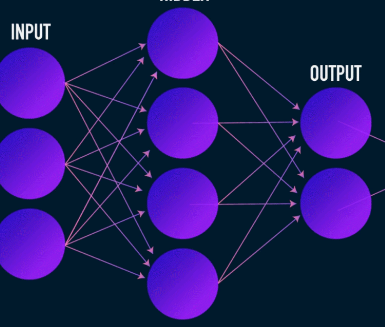
Imagem usada cortesia de James Loy
Para tornar a reconstrução dos dados robusta, o codificador otimiza seus pesos durante o treinamento para espremer os recursos mais importantes da representação dos dados de entrada no vetor latente de pequeno tamanho. Isso garante que o decodificador tenha informações suficientes sobre os dados de entrada para reconstruí-los com perda mínima.
Vetor latente (gargalo)
O gargalo ou componente vetorial latente do codificador automático é a parte mais crucial - e torna-se ainda mais crucial quando precisamos selecionar seu tamanho.
A saída do codificador é o que nos fornece o vetor latente e deve conter as representações de recursos mais importantes de nossos dados de entrada. Ele também serve como entrada para a parte do decodificador e propaga a representação útil para o decodificador para reconstrução.
Escolher um tamanho menor para o vetor latente significa que obtemos uma representação dos recursos de dados de entrada com menos informações sobre os dados de entrada. A escolha de um tamanho de vetor latente muito maior minimiza toda a ideia de compactação com codificadores automáticos e também aumenta o custo computacional.
Decodificador
Este estágio conclui nosso processo de compressão e reconstrução de dados. Assim como o codificador, este componente também é uma rede neural feed-forward, mas parece um pouco diferente estruturalmente do codificador. Essa diferença vem do fato de que o decodificador toma como entrada um vetor latente de tamanho menor que o da saída do decodificador.
A função do decodificador é gerar uma saída do vetor latente muito próxima da entrada.
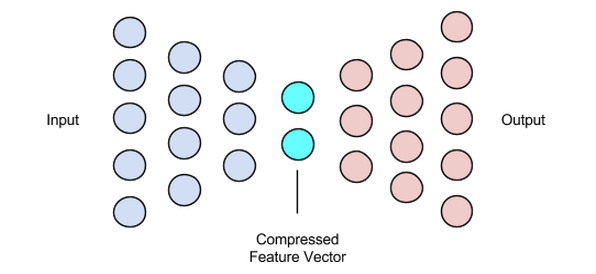
Imagem usada cortesia de Chiman Kwan
Treinamento de codificadores automáticos
Normalmente, ao treinar codificadores automáticos, construímos esses componentes juntos, em vez de construí-los independentemente. Nós os treinamos ponta a ponta com um algoritmo de otimização, como gradiente descendente ou o otimizador ADAM.
Funções de perda
Uma parte do procedimento de treinamento do autencoder que vale a pena discutir é a função de perda. A reconstrução de dados é uma tarefa de geração e, ao contrário de outras tarefas de aprendizado de máquina em que nosso objetivo é maximizar a probabilidade de prever a classe correta, direcionamos nossa rede para produzir uma saída próxima à entrada.
Podemos atingir esse objetivo com várias funções de perda, como l1, l2, erro quadrático médio e algumas outras. O que essas funções de perda têm em comum é que medem a diferença (ou seja, até que ponto ou idêntica) entre a entrada e a saída, tornando qualquer uma delas uma escolha adequada.
Redes Autoencoder
Durante todo esse tempo, temos usado um perceptron multicamadas para projetar nosso codificador e decodificador - mas descobrimos que podemos usar estruturas mais especializadas, como redes neurais convolucionais (CNNs) para capturar mais informações espaciais sobre nossos dados de entrada em o caso da compressão de dados de imagem.
Surpreendentemente, a pesquisa mostrou que as redes recorrentes usadas como autoencoders para dados de texto funcionam muito bem, mas não vamos entrar nisso no escopo deste artigo. O conceito de um codificador-decodificador vetor latente usado no perceptron multicamadas ainda é válido para autoencoders convolucionais. A única diferença é que projetamos o decodificador e o codificador com camadas convolucionais.
Todas essas redes de autencoder funcionariam muito bem para a tarefa de compactação, mas há um problema.
As redes que discutimos têm criatividade zero. O que quero dizer com criatividade zero é que eles só podem gerar resultados que viram ou com os quais foram treinados.
Podemos induzir algum nível de criatividade ajustando um pouco o design de nossa arquitetura. O resultado é conhecido como um autoencoder variacional.
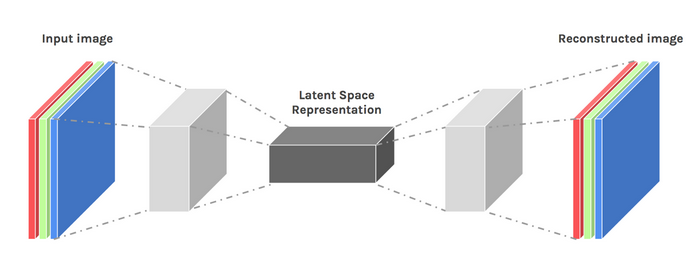
Imagem usada cortesia de Dawid Kopczyk
Autoencoder Variacional
O autoencoder variacional apresenta duas mudanças principais de design:
- Em vez de traduzir a entrada em uma codificação latente, geramos dois vetores de parâmetro:média e variância.
- Um termo de perda adicional denominado perda de divergência KL é adicionado à função de perda inicial.
A ideia por trás do autoencoder variacional é que queremos que nosso decodificador reconstrua nossos dados usando vetores latentes amostrados a partir de distribuições parametrizadas por um vetor de média e um vetor de variância gerado pelo codificador.
A amostragem de recursos de uma distribuição concede ao decodificador um espaço controlado para gerar. Após treinar um autoencoder variacional, sempre que executamos um forward pass com os dados de entrada, o codificador gera um vetor de média e variância responsável por determinar a distribuição a partir da qual amostrar o vetor latente.
O vetor médio determina onde a codificação de dados de entrada deve ser centralizada e a variância determina o espaço radial ou círculo onde queremos escolher a codificação para gerar uma saída realista. Isso significa que, com cada passagem para frente com os mesmos dados de entrada, nosso autoencoder variacional pode gerar diferentes variantes da saída centrada em torno do vetor médio e dentro do espaço de variância.
Para comparação, ao olhar para um autoencoder padrão, quando tentamos gerar uma saída na qual a rede não foi treinada, ela gera saídas irreais devido à descontinuidade no espaço vetorial latente que o codificador produz.
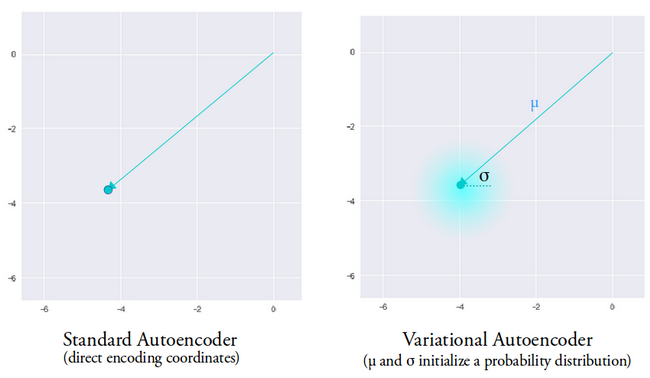
Imagem usada cortesia de Irhum Shafkat
Agora que temos uma compreensão intuitiva de um autoencoder variacional, vamos ver como construí-lo no TensorFlow.
Código TensorFlow para um Autoencoder Variacional
Começaremos nosso exemplo preparando nosso conjunto de dados. Para simplificar, usaremos o conjunto de dados MNIST.
(train_images, _), (test_images, _) =tf.keras.datasets.mnist.load_data () train_images =train_images.reshape (train_images.shape [0], 28, 28, 1) .astype ('float32') test_images =test_images.reshape (test_images.shape [0], 28, 28, 1) .astype ('float32') # Normalizando as imagens para o intervalo de [0., 1.] train_images / =255. test_images / =255. # Binarização train_images [train_images> =.5] =1. train_images [train_images <.5] =0. test_images [test_images> =.5] =1. test_images [test_images <.5] =0. TRAIN_BUF =60000 BATCH_SIZE =100 TEST_BUF =10000 train_dataset =tf.data.Dataset.from_tensor_slices (train_images) .shuffle (TRAIN_BUF) .batch (BATCH_SIZE) test_dataset =tf.data.Dataset.from_tensor_slices (test_images) .shuffle (TEST_BUF) .batch (BATCH_SIZE) Obtenha o conjunto de dados e prepare-o para a tarefa. classe CVAE (tf.keras.Model): def __init __ (self, latent_dim): super (CVAE, self) .__ init __ () self.latent_dim =latent_dim self.inference_net =tf.keras.Sequential ( [ tf.keras.layers.InputLayer (input_shape =(28, 28, 1)), tf.keras.layers.Conv2D ( filters =32, kernel_size =3, strides =(2, 2), activation ='relu'), tf.keras.layers.Conv2D ( filters =64, kernel_size =3, strides =(2, 2), activation ='relu'), tf.keras.layers.Flatten (), # Sem ativação tf.keras.layers.Dense (latent_dim + latent_dim), ] ) self.generative_net =tf.keras.Sequential ( [ tf.keras.layers.InputLayer (input_shape =(latent_dim,)), tf.keras.layers.Dense (unidades =7 * 7 * 32, ativação =tf.nn.relu), tf.keras.layers.Reshape (target_shape =(7, 7, 32)), tf.keras.layers.Conv2DTranspose ( filtros =64, kernel_size =3, strides =(2, 2), padding ="SAME", activation ='relu'), tf.keras.layers.Conv2DTranspose ( filtros =32, kernel_size =3, strides =(2, 2), padding ="SAME", activation ='relu'), # Sem ativação tf.keras.layers.Conv2DTranspose ( filters =1, kernel_size =3, strides =(1, 1), padding ="SAME"), ] ) @ tf.function def sample (self, eps =None): se eps for Nenhum: eps =tf.random.normal (shape =(100, self.latent_dim)) return self.decode (eps, apply_sigmoid =True) def encode (self, x): média, logvar =tf.split (self.inference_net (x), num_or_size_splits =2, eixo =1) return mean, logvar def reparameterize (self, mean, logvar): eps =tf.random.normal (shape =mean.shape) return eps * tf.exp (logvar * .5) + mean def decodificar (self, z, apply_sigmoid =False): logits =self.generative_net (z) if apply_sigmoid: probs =tf.sigmoid (logits) return probs logits de retorno Os dois trechos de código preparam nosso conjunto de dados e constroem nosso modelo autencoder variacional. No fragmento de código do modelo, há algumas funções auxiliares para realizar a codificação, amostragem e decodificação.
Reparameterização para gradientes de computação
Há uma função de reparametrização que não discutimos, mas resolve um problema crucial em nossa rede de autocodificadores variacionais. Lembre-se de que, durante o estágio de decodificação, amostramos a codificação do vetor latente a partir de uma distribuição controlada pelo vetor de média e variância gerado pelo codificador. Isso não gera problemas ao transmitir dados através de nossa rede, mas causa um grande problema ao retropropagar gradientes do decodificador para o codificador, uma vez que a operação de amostragem não é diferenciável.
Em termos simples, não podemos calcular gradientes de uma operação de amostragem.
Uma boa solução para esse problema é aplicar o truque de reparametrização. Isso funciona gerando primeiro uma distribuição gaussiana padrão de média 0 e variância 1 e, em seguida, executando uma operação de adição e multiplicação diferenciável nessa distribuição com a média e a variância geradas pelo codificador.
Observe que transformamos a variação em espaço de logaritmo no código. Isso é para garantir a estabilidade numérica. O termo de perda adicional, a perda de divergência de Kullback-Leibler, é introduzido para garantir que as distribuições que geramos sejam o mais próximo possível de uma distribuição gaussiana padrão com média 0 e variância 1.
Conduzir as médias das distribuições a zero garante que as distribuições que geramos sejam muito próximas umas das outras para evitar descontinuidades entre as distribuições. Uma variação próxima a 1 significa que temos um espaço mais moderado (ou seja, nem muito grande nem muito pequeno) para gerar as codificações.
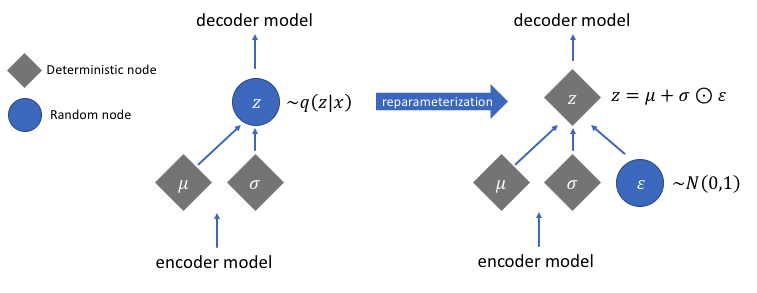
Imagem usada cortesia de Jeremy Jordan
Depois de realizar o truque de reparametrização, a distribuição obtida multiplicando o vetor de variância com uma distribuição gaussiana padrão e adicionando o resultado ao vetor de média é muito semelhante à distribuição imediatamente controlada pelos vetores de média e variância.
Etapas simples para construir um codificador automático de variações
Vamos encerrar este tutorial resumindo as etapas na construção de um autoencoder variacional:
- Construa as redes de codificadores e decodificadores.
- Aplique um truque de reparametrização entre o codificador e o decodificador para permitir a retropropagação.
- Treine ambas as redes de ponta a ponta.
O código completo usado acima pode ser encontrado no site oficial do TensorFlow.
Imagem em destaque modificada de Chiman Kwan
Como implementar o reconhecimento de dígitos com TensorFlow Lite usando um MCU i.MX RT1060 Crossover
Compreendendo os mínimos locais no treinamento de rede neural
Robô industrial
- Como as impressoras 3D constroem objetos de metal
- Como reduzir o desperdício com robôs autônomos
- Como proteger a tecnologia em nuvem?
- O que eu faço com os dados ?!
- Como a IoT pode ajudar com Big Data HVAC:Parte 2
- Como tornar IOT real com Tech Data e IBM Parte 2
- Como tornar a IoT real com Tech Data e IBM Parte 1
- Como as empresas da cadeia de suprimentos podem construir roteiros com IA
- Data Mining, AI:Como as marcas industriais podem acompanhar o comércio eletrônico
- O que é a vida útil da ferramenta? Como otimizar ferramentas com dados de máquina