


Mergulhe fundo no ciclo de vida da ciência de dados
Desde a chegada do big data, a ciência da computação moderna tem alcançado novos recursos e benchmarks de poder de processamento. Hoje em dia, não é incomum encontrar aplicativos que produzem conjuntos de dados de 100 terabytes ou mais, o que é considerado big data.
Com um volume tão grande de informações em mãos, é fácil ficar desorganizado e perder tempo com conteúdo inútil. Esses são dois motivos pelos quais é muito importante seguir uma metodologia que aumente a eficácia e eficiência de um projeto de big data.

Figura 1. A ciência de dados moderna trabalha com conjuntos de dados muito grandes, também conhecidos como big data.
O ciclo de vida da ciência de dados fornece uma estrutura que ajuda a definir, coletar, organizar, avaliar e implantar projetos de big data. É um processo iterativo que consiste em uma série de etapas organizadas em uma sequência lógica, facilitando o feedback e a rotação.
Como é a sequência do ciclo de vida? A resposta é:não existe um único modelo universal que todos sigam. Muitas empresas que empreendem projetos de big data adaptam o ciclo de vida da ciência de dados a seus processos de negócios, normalmente incluindo mais etapas. Apesar disso, todos os muitos modelos e fluxos de processo têm denominadores comuns. Este artigo usará o modelo de processo CRISP-DM, que é um dos primeiros e mais populares modelos de ciclo de vida da ciência de dados.
O modelo CRISP-DM
CRISP-DM significa Processo Padrão entre Indústrias para Mineração de Dados. Foi publicado pela primeira vez em 1999 pelo ESPRIT, um programa europeu para impulsionar a investigação em tecnologias da informação (TI). O modelo CRISP-DM consiste em seis etapas ou fases que orientam o projeto de big data. Ele incentiva as partes interessadas a pensar sobre o negócio, colocando e respondendo perguntas importantes sobre o problema.
Vamos revisar em detalhes as seis fases do modelo CRISP-DM.
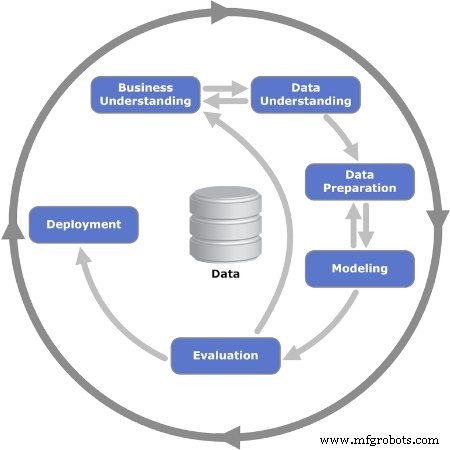
Figura 2. As seis fases iterativas do modelo CRISP-DM são mostradas. Imagem usada cortesia de Kenneth Jensen
Fase 1:Compreensão de negócios
A primeira fase consiste em várias tarefas que definem o problema e estabelecem objetivos. É quando os objetivos do projeto são definidos com o foco no negócio - ou, em outras palavras, no cliente. Normalmente, a equipe montada para trabalhar em um projeto de big data deve entregar uma solução ao cliente, que pode ser outra área ou departamento da empresa.
Uma vez que a necessidade ou o problema do negócio tenha sido estabelecido, a próxima etapa é definir os critérios de sucesso. Podem ser indicadores-chave de desempenho (KPI) ou acordos de nível de serviço (SLA), que fornecem meios objetivos para avaliar o progresso e a conclusão.
Em seguida, a situação do negócio precisa ser analisada para identificar riscos, planos de reversão, medidas de contingência e, mais importante, disponibilidade de recursos. Um plano de projeto é apresentado, incluindo recursos de marcos.
Fase 2:compreensão dos dados
Uma vez que os fundamentos foram estabelecidos na fase anterior, é hora de se concentrar nos dados. Esta fase começa com uma definição inicial de quais dados são considerados necessários e, em seguida, documenta algumas especificações sobre eles:onde encontrá-los, tipo de dados, formato, relações entre diferentes campos de dados, etc.
Com a primeira documentação pronta, a próxima etapa é executar a primeira execução de coleta de dados. Isso fornece um instantâneo útil de como a estrutura está se formando. Este instantâneo de informações é então avaliado quanto à qualidade.
Fase 3:Preparação de dados
A terceira fase reforça a fase anterior e prepara o conjunto de dados para modelagem. Os campos de dados da primeira coleção são ainda selecionados e qualquer informação considerada desnecessária é removida do conjunto:isso é chamado de limpeza dos dados.
Além disso, uma informação específica pode precisar ser derivada de outras informações disponíveis; outras vezes, deve ser combinado. Em outras palavras, os dados precisam ser processados para produzir um formato final.
Fase 4:Modelagem
A tarefa mais importante nesta fase é selecionar um algoritmo para processar os dados coletados. Nesse contexto, um algoritmo é um conjunto de etapas e regras de sequência programadas em um software de computador desenvolvido para projetos de big data.
Muitos algoritmos podem ser usados:regressões lineares, árvores de decisão e máquinas de vetores de suporte são alguns exemplos. A escolha do algoritmo certo para resolver o problema requer habilidades que os cientistas de dados experientes possuem.
Figura 3. A regressão linear é um tipo de algoritmo usado na modelagem de big data.
A próxima etapa é codificar o algoritmo no aplicativo de software. É também quando a fase de teste é planejada, que consiste na alocação de conjuntos de dados específicos para teste e validação.
Fase 5:Avaliação
Às vezes, é difícil escolher um algoritmo desde o início. Quando isso acontece, os cientistas executam vários algoritmos e analisam os resultados para chegar a uma decisão final. Uma vez que a fase de teste é concluída, os resultados são revisados para integridade e precisão.
Mais importante, esta é uma oportunidade de avaliar se os resultados levam a uma solução. No modelo iterativo, esta é uma interseção crucial onde as sequências de iteração principais podem ser lançadas ou uma decisão de avançar para a fase final pode ser alcançada.
Fase 6:implantação
É quando o projeto muda de um ambiente de teste para um ambiente de produção ao vivo. O planejamento do cronograma e da estratégia de implantação é muito importante para reduzir os riscos e o possível tempo de inatividade do sistema.
Embora o diagrama do modelo sugira que este é o fim do projeto, ainda existem várias etapas a serem seguidas depois:monitoramento e manutenção. O monitoramento é um período de observação de perto, também conhecido como hiper cuidado, imediatamente após o go-live. A manutenção é um processo semipermanente para manter e atualizar a solução implementada.
Big data é chamado assim por um motivo:há uma grande quantidade de dados para analisar. A implementação de um dos modelos de ciclo de vida da ciência de dados ajuda a decidir quais informações valem a pena manter e usar em processos como manutenção preditiva.
Como a indústria 4.0 impactará a rede da cadeia de suprimentos?
Compreendendo a dinâmica dos fluidos computacionais (CFD)
Tecnologia da Internet das Coisas
- Além do smartphone:Transformando dados em som
- IA terceirizada e aprendizagem profunda no setor de saúde - A privacidade de dados está em risco?
- Manutenção no mundo digital
- Simplificando o ciclo de vida do SIM
- Democratizando a IoT
- Maximizando o valor dos dados IoT
- Colocar a ciência de dados nas mãos de especialistas do domínio para fornecer insights mais valiosos
- Por que a conexão direta é a próxima fase da IoT industrial
- O valor da medição analógica
- Tableau, os dados por trás das informações