


Tolerância a falhas e seu impacto na confiabilidade do sistema
Equipamentos e sistemas projetados sem tolerância a falhas em mente costumam ter baixa (er) confiabilidade.
É por isso que um projeto de sistema tolerante a falhas é uma escolha óbvia para a maioria dos engenheiros de projeto e confiabilidade - especialmente quando se trata de equipamentos críticos cuja falha pode comprometer a confiabilidade, disponibilidade, manutenção e segurança (RAMS) de todo o sistema, eles são um parte de.
Junte-se a nós enquanto exploramos as características dos sistemas tolerantes a falhas e discutimos maneiras de melhorar a tolerância a falhas por meio de projetos redundantes.
O que é tolerância a falhas?
A tolerância a falhas representa a capacidade de qualquer sistema ou equipamento de manter sua operação durante a presença de uma falha.
Sistemas e equipamentos com alta tolerância a falhas, dependendo do mecanismo de tolerância a falhas adotado, são capazes de sustentar total ou parcialmente sua operação na ocorrência de uma falha. Para que isso funcione na prática, tais sistemas não podem ter um único ponto de falha (SPOF).
A essência dos projetos tolerantes a falhas
O desenvolvimento de projetos tolerantes a falhas exige uma consideração cuidadosa das falhas que podem se manifestar ao longo do ciclo de vida do equipamento, juntamente com suas prováveis causas e consequências.
No entanto, os engenheiros de projeto também devem considerar os fatores de custo e recursos necessários para atingir o nível exigido de tolerância, confiabilidade e confiabilidade do equipamento.
Freqüentemente, é mal compreendido que um projeto tolerante a falhas deve fornecer tolerância total a todos os tipos de falhas. Isso não é verdade. Um bom projeto deve combinar o grau de tolerância com a criticidade da falha, de forma que a otimização geral de custos e eficiências de recursos possa ser alcançada.
Por exemplo, pode não ser econômico gastar dinheiro no reprojeto do produto, apenas para resolver uma falha que tem uma chance extremamente baixa de ocorrer.
Características dos sistemas tolerantes a falhas
Para criar um sistema tolerante a falhas, são necessários esforços em todas as fases do ciclo de vida do equipamento. Isso inclui, mas não está limitado à fase de especificação e projeto (incorporando controles de detecção de falhas no projeto), validação e verificação (V&V), manutenção e operação (usando peças de reposição aprovadas pelo OEM e orientações para manutenção de rotina) e até mesmo estágio de descarte .
Cada estágio pode adotar combinações das técnicas indicadas abaixo para desenvolver novos projetos ou melhorar os atuais para aumentar seu nível de tolerância a falhas:
- detecção e exibição de falhas
- diagnóstico de falhas e contenção
- mascaramento de falhas e compensação
1) Detecção e exibição de falhas
A detecção de falha se refere à capacidade do sistema / equipamento de detectar e exibir a falha. É o aspecto fundamental de qualquer sistema tolerante a falhas . Todos os outros aspectos dependem da eficácia do processo de detecção de falhas. Se o sistema não for projetado para detectar sua falha, ou de alguma forma detectar uma falha incorretamente, os demais aspectos também serão ineficazes.
Por exemplo, um sensor de pressão de ar simples em um sistema de monitoramento de pressão de pneu de carro (TPMS) pode detectar o transbordamento de ar e notificar o motorista pelo painel do carro.
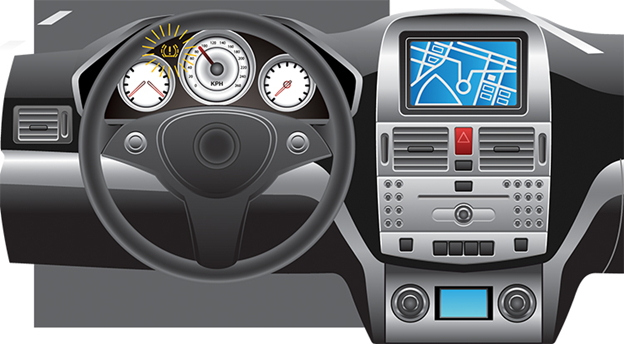
Uma representação da ativação do TPMS
Nesse caso, a detecção e a exibição são o único nível de tolerância aceitável para este evento de falha. O cliente pode desengatar com segurança a mangueira de ar antes de romper o pneu.
Se a detecção de pressão for imprecisa, o motorista pode desengatar a mangueira muito cedo / tarde e experimentar falha do pneu durante a condução. Como não há correção automática da pressão do ar, o aspecto de tolerância para essa falha é restrito apenas à detecção e exibição.
2) Diagnóstico de falha e contenção
Em sistemas mais sofisticados, camadas adicionais são frequentemente adicionadas no estágio de design do produto. Seu objetivo é diagnosticar e realizar contenção além da detecção e exibição. Essas camadas adicionais são garantidas devido à criticidade do sistema ou devido a várias questões de segurança.
Por exemplo, um Sistema de Controle Distribuído (DCS) - um sistema de controle para plantas de processo - não apenas monitora os parâmetros críticos do processo por meio de um conjunto de sensores, mas também realiza um diagnóstico para detectar a localização da falha e realizar a contenção necessária.
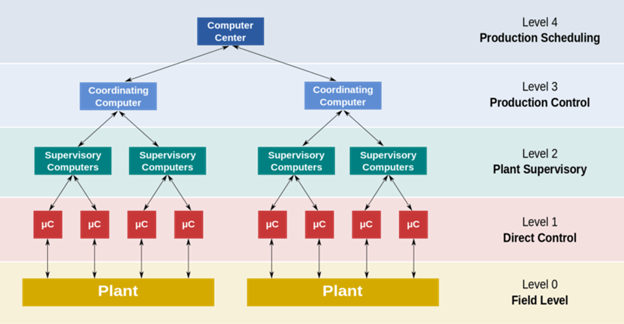
Uma representação do sistema DCS
Por exemplo, no caso de sobrepressão de produtos de petróleo em um vaso, o sistema é acionado por sensores de pressão relevantes. Ele abre a válvula de segurança de pressão e expele os vapores da pilha do queimador.
Neste exemplo, a contenção é realizada desviando o vapor inflamável de alta pressão para a chaminé de exaustão, protegendo o sistema de incêndio ou explosão.
3) Mascaramento e compensação de falhas
Outra abordagem eficaz para a tolerância a falhas é mascarar o estado da falha. É muito eficaz para equipamentos que podem ser monitorados e controlados por meio da tecnologia da Internet das Coisas (IoT).
Com esses equipamentos, um dos desafios mais significativos vem na forma de ameaças à segurança cibernética. Esses tipos de ameaças podem tentar induzir a falha alterando o estado do equipamento por meio da injeção de dados falsos do equipamento no servidor.
Com registros incorretos do estado do equipamento, o próprio sistema de controle e monitoramento originalmente destinado a proteger pode causar a falha do ativo. Alternativamente, pode ser “enganado” pensando que o ativo está em boas condições, quando na verdade não está - permitindo que a deterioração leve à falha sem acionar nenhum alerta.
Ao incorporar o mascaramento de falhas, o sistema é projetado de forma que possa reconhecer e mascarar esses valores incorretos.
Por exemplo, nas redes de eletricidade, os disjuntores são frequentemente controlados e monitorados por meio do Controle Supervisório e Aquisição de Dados (SCADA).
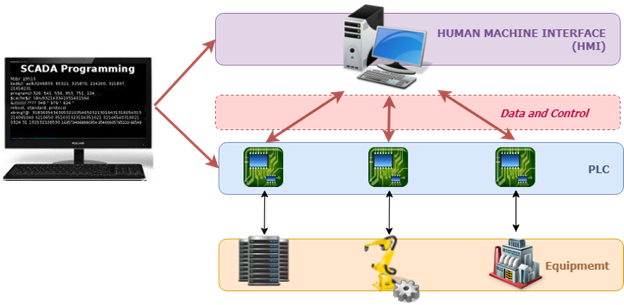
Uma representação do sistema SCADA
Tal sistema monitora de perto os parâmetros de tensão e frequência do equipamento elétrico e faz com que eles fechem ou abram para manter a estabilidade da rede de energia.
Um ataque cibernético de entrada pode alterar os limites de tensão e frequência do equipamento. Consequências? O sistema pode causar queda de energia em vez de evitá-la.
O mascaramento de falhas é frequentemente realizado por meio de algoritmos que detectam fluxos de dados anômalos e injetam dados falsos com o objetivo de mascarar os dados que representam o estado de falha do equipamento. Isso evita que os responsáveis pelos dados ruins espalhem a falha e exacerbem ainda mais a confiabilidade da rede.
Melhorando a tolerância a falhas por meio de projetos redundantes
Uma das ações simples que podem ser tomadas para aumentar a tolerância a falhas é incorporar redundâncias no projeto. Redundância significa simplesmente a presença de um sistema alternativo ou solução que pode assumir a função pretendida caso o sistema principal falhe.
Embora a redundância melhore a tolerância a falhas, adicionar sistemas aleatoriamente não deve ser o objetivo, pois a quantidade de custo necessária para adicionar qualquer novo sistema pode superar significativamente o benefício de confiabilidade alcançável.
Do ponto de vista do equipamento físico, eles podem ser amplamente classificados como ativos ou redundâncias passivas .
Redundâncias ativas
Redundâncias ativas podem ser estabelecidas quando vários equipamentos são operados simultaneamente. Nessa configuração, cada equipamento contribui com sua parcela para o cumprimento da função pretendida, ao mesmo tempo em que atua como redundância entre si.
Uma redundância ativa simplista é a operação em paralelo de duas bombas na metade de suas capacidades nominais. Ambas as bombas operam em conjunto para atingir a pressão de descarga desejada. Se uma bomba falhar, a outra bomba ainda pode ser impulsionada até sua capacidade nominal para atingir a pressão de descarga pretendida por conta própria. Para obter economia de design, os engenheiros de confiabilidade criaram várias outras maneiras complicadas de obter redundâncias ativas, como redundâncias K de N e degradação normal.
Redundâncias em K de N , um determinado subconjunto de equipamentos está sempre em operação. Isso aumenta a confiabilidade do sistema, pois alguns dos equipamentos ainda estão em espera ativa e podem ingressar na operação em caso de falha de alguns equipamentos. Isso garante maior confiabilidade em comparação com a operação paralela simples de duas bombas, pois haverá um maior número de bombas pequenas operando.
Degradação graciosa é uma alternativa para adicionar sistemas idênticos e paralelos caros. Ele garante que os recursos ou a funcionalidade do equipamento geral sejam degradados proporcionalmente ao número de componentes com falha. Para atingir essa degradação escalonável, deve ser realizado um exame de todas as falhas possíveis em todos os componentes. Seu impacto no desempenho geral do sistema deve ser analisado e documentado.
Essas técnicas fornecem tolerância a falhas parciais e permitem que o sistema continue sua função em uma capacidade degradada.
Redundâncias passivas
Redundância passiva é a redundância de espera onde o equipamento alternativo está presente - mas ela só pode assumir a função pretendida em caso de falha do equipamento principal.
Podemos diferenciar dois tipos de redundâncias passivas:
- redundâncias passivas operacionais
- redundâncias passivas não operacionais
Redundâncias passivas operacionais são aqueles em que o equipamento alternativo está presente como hot spare. O equipamento em espera está quente porque pode estar operando em condições sem carga. Em alguns casos, pode estar cumprindo uma função que está fora da definição da função do equipamento principal.
Em caso de falha do equipamento principal, o equipamento de reserva operacional pode ser automaticamente transferido para desempenhar a função de equipamento principal.
Um exemplo de redundância passiva operacional pode ser um alternador secundário que opera sob condições sem carga e atende a todas as outras condições de paralelismo, como a mesma tensão terminal, frequência e sequência de fase. Em caso de falha do alternador primário, o alternador secundário pode ser sincronizado automaticamente com o sistema e assumir a carga.
No caso de redundâncias passivas não operacionais , o equipamento em espera é desligado. Em caso de falha do equipamento principal, o equipamento em espera pode ser automaticamente ou manualmente definido para as condições de operação e assumir a funcionalidade do equipamento principal.
Um bom exemplo de redundância passiva não operacional é uma bomba de água municipal de reserva que pode ser iniciada e operada manualmente para fornecer água aos residentes se a bomba de água principal não funcionar corretamente. Uma vez que a restauração da operação não é crítica, um operador pode ir e iniciar a bomba (e sincronizá-la com o sistema posteriormente, conforme necessário).
Técnicas de confiabilidade para analisar a tolerância a falhas
A tolerância a falhas faz parte dos esforços de engenharia de confiabilidade e requer um exame cuidadoso de todas as falhas possíveis que podem ocorrer no equipamento. A Análise do Efeito do Modo de Falha (FMEA) e a Análise da Árvore de Falhas (FTA) são duas técnicas bem conhecidas para analisar o projeto do sistema de baixo para cima e de cima para baixo, respectivamente.
Para entender melhor a tolerância, a sequência de falha e as dependências devem ser analisadas e investigadas. Uma técnica particularmente útil para analisar dependências e sequência é o modelo de Markov, em que a probabilidade de qualquer evento de falha dependeria do estado do evento anterior.
Da mesma forma, outra técnica poderosa são as simulações de Monte Carlo que podem ser usadas para modelar o impacto das incertezas de qualquer evento de falha no desempenho do sistema.
Tolerância a falhas e operações de manutenção
Os sistemas tolerantes a falhas precisam de menos manutenção? Bem, sim e não.
Por causa de redundâncias e outras características que discutimos anteriormente, tais sistemas geralmente podem apresentar mais falhas antes que sua funcionalidade seja comprometida. No entanto, se os problemas não forem resolvidos, o acúmulo de falhas acabará por levar a uma falha do sistema ou equipamento. Portanto, as equipes de manutenção devem usar um sistema CMMS para garantir que as ações corretivas de manutenção sejam tomadas no devido tempo.
Em certo sentido, a tolerância a falhas dá às equipes de manutenção e suporte mais espaço para respirar. Eles ainda precisam lidar com o problema, mas talvez não imediatamente.
Embora os projetos tolerantes a falhas tenham seus desafios em termos de aumento de custos e complexidade, eles compensam na forma de maior confiabilidade do equipamento.
Manutenção e reparo de equipamentos
- COVID 19 e Nuvem; COVID 19 e seu impacto nos negócios
- Melhor desempenho em manutenção e confiabilidade
- Manutenção e confiabilidade - bom o suficiente nunca é
- Detalhes são importantes na manutenção e confiabilidade
- Fornecedores de manutenção e confiabilidade:Comprador, cuidado
- Fabricação flexível e confiabilidade podem coexistir
- Aplicação de entropia para manutenção e confiabilidade
- UT renomeia o programa como Centro de Confiabilidade e Manutenção
- Uma perspectiva dos canoístas sobre confiabilidade e segurança
- ISA publica livro sobre segurança e confiabilidade do sistema de controle